2023 untersuchte das Markt- und Sozialforschungsinstitut intervista zusammen mit den Partnerinstituten des globalen IRIS-Netzwerks die weltweite Stimmungslage zu den Themen Klima, Wirtschaft und Gesundheit. Das IRIS-Netzwerk ist auf sechs Kontinenten aktiv und damit weltweit eines der grössten Marktforschungsnetzwerke.
Für diese Studie wurden in insgesamt 27 Ländern in Nord- und Südamerika, Europa, Asien und Australien über 18’000 Personen zu ihren Ansichten befragt. In der Schweiz wurden die Teilnehmenden über das intervista Online-Panel rekrutiert, in den meisten anderen Ländern jeweils über regionale Panelanbieter. Im vorliegenden Artikel werden die Daten der Nullmessung 2023 dargestellt. Die Befragung wird zukünftig jährlich durchgeführt.
Schweizer Bevölkerung im internationalen Vergleich zuversichtlich
Obwohl Schweizer:innen nicht unbedingt für ihren Optimismus bekannt sind, zeigen sie sich im internationalen Vergleich überdurchschnittlich zuversichtlich hinsichtlich der aktuellen Lage im eigenen Land. Eine Mehrheit der Bevölkerung der befragten Länder glaubt, dass sich ihr Land in die falsche Richtung bewege. In der Schweiz ist das Gegenteil der Fall: Rund zwei Drittel der Bevölkerung denken, dass der richtige Weg eingeschlagen sei.
Zudem beurteilt die Schweizer Bevölkerung auch die wirtschaftliche Situation deutlich positiver als die Bevölkerung anderer Länder. Dennoch zeigen sich auch in der Schweiz kritische Tendenzen: Fast die Hälfte der Bevölkerung berichtet, dass sie 2023 im Vergleich zum Vorjahr den Gürtel enger schnallen musste. Gespart wird vor allem bei Kleidern und Restaurantbesuchen; glücklicherweise muss kaum jemand auf Medikamente verzichten oder kann seine Miete nicht bezahlen. Dies ist keine Selbstverständlichkeit: Im internationalen Durchschnitt berichtete jede:r Fünfte, die Miete oder den Hypothekarzins nicht mehr rechtzeitig bezahlen zu können. Zudem konnte sich fast jede:r Vierte nicht mehr leisten, eigentlich benötigte Medikamente zu konsumieren.
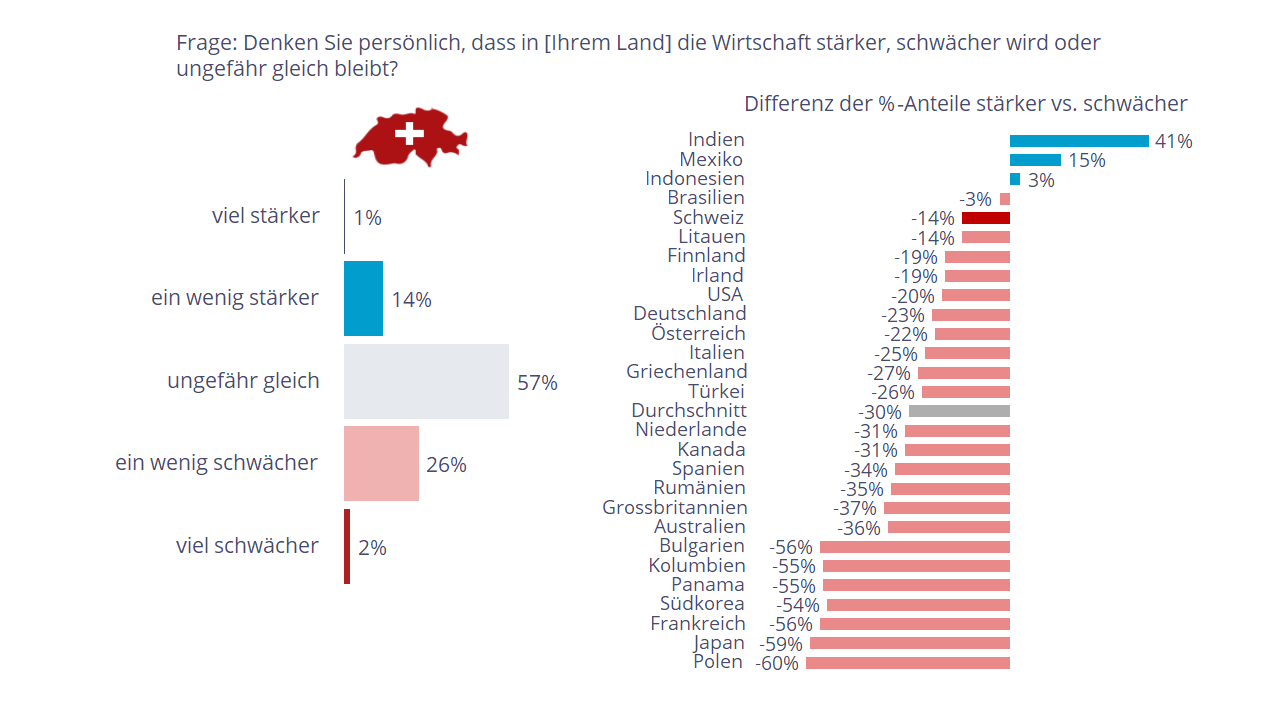
Auch in der Schweiz wurde zum Messzeitpunkt 2023 eine Schwächung der Wirtschaft erwartet, wenn auch bei weitem nicht so stark wie anderswo. Einzig einige Schwellenländer (Indien, Mexiko, Indonesien) zeigten sich optimistischer und erwarteten trotz der damaligen Weltlage ein Wirtschaftswachstum.
Abb. 1: Erwartete wirtschaftliche Entwicklung in der Schweiz (links) und im internationalen Vergleich (rechts)
Nachhaltige Kaufentscheidungen
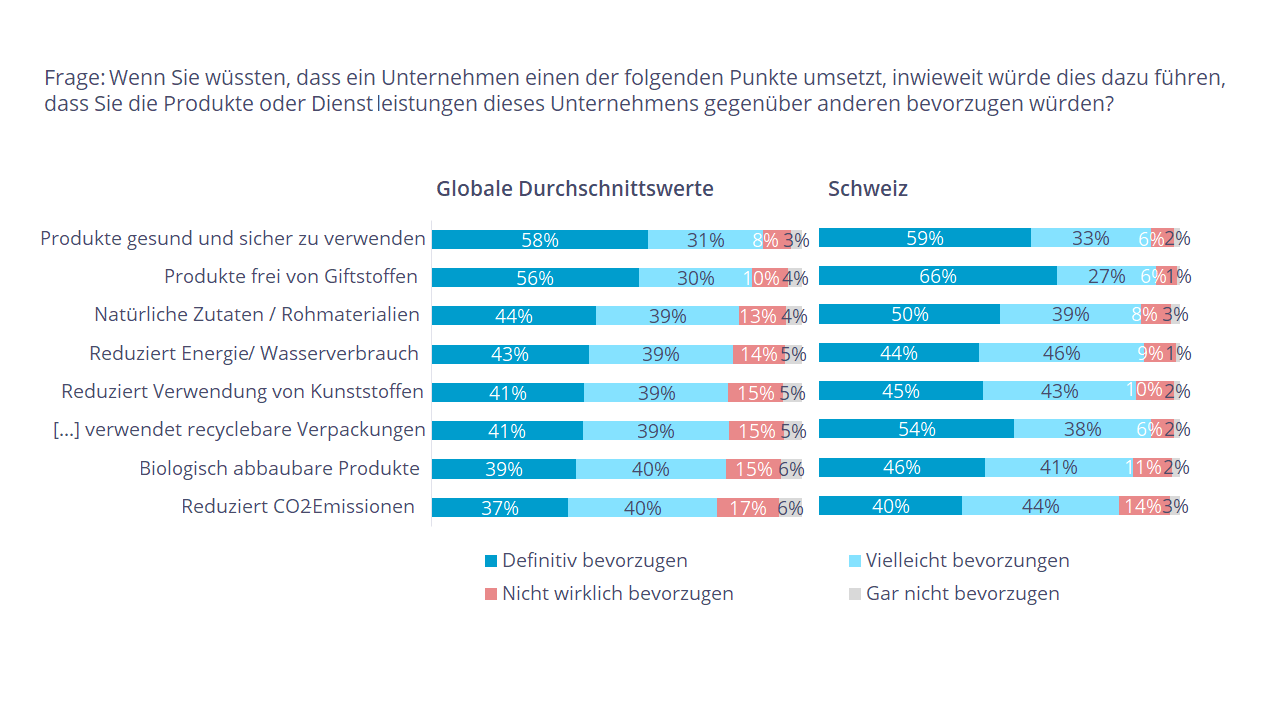
Die im internationalen Vergleich angenehme wirtschaftliche Lage, in der sich viele Schweizer:innen zum Zeitpunkt der Erhebung 2023 befinden, hat einen direkten Einfluss auf ihre alltäglichen Entscheidungen. So können es sich Schweizer:innen eher leisten, bei Kaufentscheidungen auf Nachhaltigkeit zu achten. In fast allen untersuchten Dimensionen erreicht die Schweizer Bevölkerung höhere Werte als die befragte Weltbevölkerung. Besonders auffällig ist dies bei Produktverpackungen. Ganze 92 Prozent und damit ein im weltweiten Vergleich überdurchschnittlich hoher Anteil der Bevölkerung legten in der Schweiz Wert auf reduzierte oder recyclebare Verpackungen.
Abb. 2: Nachhaltige Entscheidungen weltweit (links) und in der Schweiz (rechts)
Wahrnehmung des Klimawandels
Generell sind Klimawandel und Nachhaltigkeit Themen, die bewegen. Ganze 82 Prozent der Schweizer Bevölkerung machen sich Sorgen über die Folgen des Klimawandels. Damit befindet sich die Schweiz im internationalen Mittelfeld und auf gleichem Niveau wie andere europäische Länder (zum Beispiel Spanien, Deutschland und Österreich). Die grösste Besorgnis äussern Bewohner:innen in Schwellenländern. Beispielsweise zeigen sich in der Türkei 98 Prozent der Bevölkerung besorgt hinsichtlich des Klimawandels.
In den Industrieländern geht man davon aus, dass nicht das eigene Land oder gar die eigene Wohnregion, sondern in erster Linie andere Länder vom Klimawandel betroffen sind. Auch in den Schwellenländern findet sich diese differenzierte Wahrnehmung, jedoch in bedeutend geringerem Ausmass. Dies widerspiegelt die Situation, dass Schwellenländer von den Folgen des Klimawandels tendenziell stärker betroffen sind als Industrieländer.
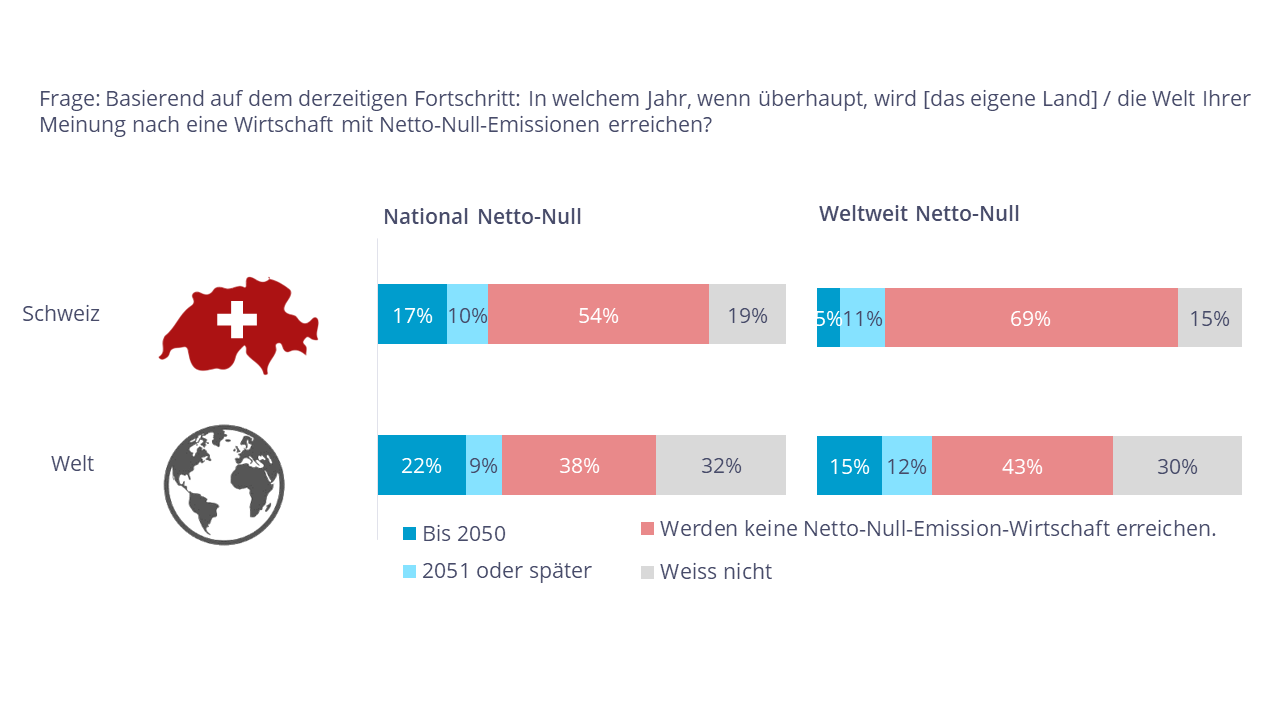
Zur Frage, ob die Folgen des Klimawandels noch abgefedert werden können, gibt es in der Bevölkerung unterschiedliche Meinungen. In der Schweiz ist knapp die Hälfte noch optimistisch, während 35 Prozent der Bevölkerung denken, dass es bereits zu spät sei, schwerwiegende negative Effekte des Klimawandels zu vermeiden. Im internationalen Vergleich sind nur 23 Prozent der befragten Bevölkerung pessimistisch. Rund 70 Prozent der Schweizer:innen glauben nicht mehr daran, dass man weltweit Netto-Null-Emissionen erreichen wird. Auch hier sind die Schweizer:innen deutlich pessimistischer als der globale Durchschnitt. Allerdings ist die Schweizer Bevölkerung etwas optimistischer, wenn es um die Frage geht, ob in der Schweiz das Netto-Null-Ziel erreicht werden kann. Dann glaubt bloss noch die Hälfte, dass dieses Ziel nicht erreicht werden kann.
Abb. 3: Zuversicht, Netto-Null-Emissionen in der Schweiz (oben) und weltweit (unten) zu erreichen
Einschätzung der Gesundheitsversorgung
Wenn man an den Klimawandel denkt, könnte man meinen, dass zusätzliche (finanzielle) Ressourcen viele Probleme lösen könnten – schliesslich sind Personen in den reicheren Industrienationen deutlich optimistischer. Bei der gesundheitlichen Versorgung zeigt sich aber, dass Geld nicht alles ist.
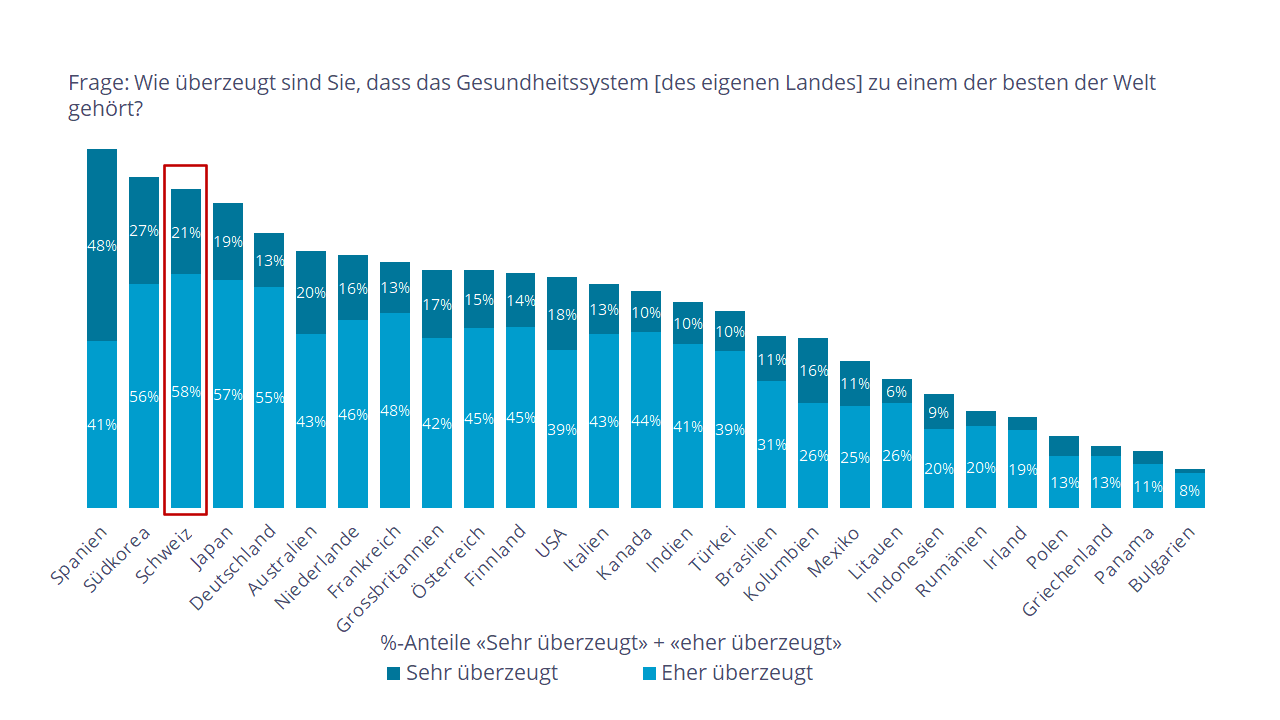
Aber zunächst die guten Nachrichten. Auch wenn sich Schweizer:innen über hohe Krankenkassenprämien ärgern, so meint doch mehr als die Hälfte der Schweizer Bevölkerung, dass wir ein gutes oder sogar hervorragendes Gesundheitssystem haben. Damit bewerten Schweizer:innen im internationalen Durchschnitt das nationale Gesundheitssystem deutlich positiver als Personen anderer Länder. Vier von fünf Schweizer:innen sind gar überzeugt, dass das Schweizer Gesundheitssystem zu den Besten der Welt gehöre. Nur in wenigen Ländern (Spanien, Südkorea, Japan) ist die Bevölkerung ebenso positiv zum eigenen Gesundheitssystem eingestellt.
Abb. 4: Wahrgenommene Qualität des eigenen Gesundheitssystems im internationalen Vergleich
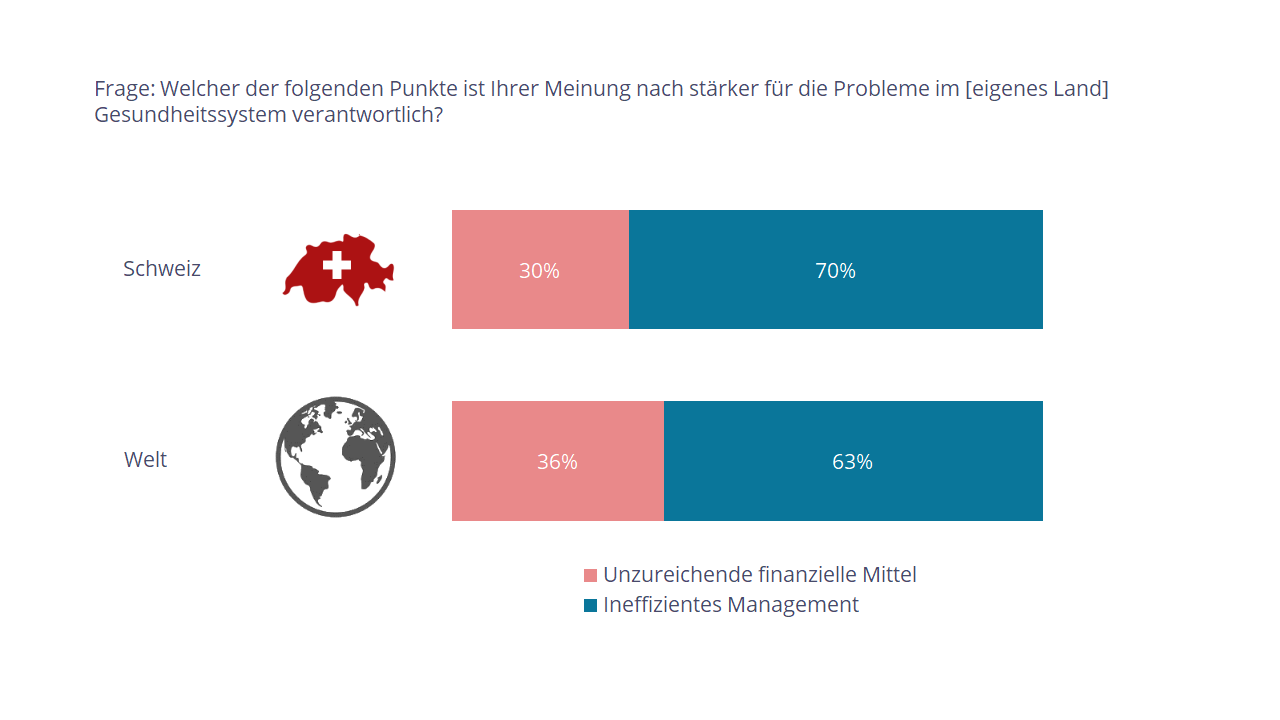
Es zeigen sich aber auch Schattenseiten. Wenn es um die Probleme im Gesundheitssystem geht, meint die Mehrheit, dass dies nicht ein Problem der finanziellen Ressourcen sei. Ganz im Gegenteil, die Probleme seien auf ein ineffizientes Management zurückzuführen. In anderen Ländern wird dies ähnlich eingeschätzt. So erstaunt es auch nicht, dass mehr als die Hälfte der Schweizer Bevölkerung mit dem politischen Management des Gesundheitssystems nicht einverstanden ist. Ein ähnliches Bild zeigt sich im restlichen Europa und in Amerika. In Asien und Australien hingegen unterstützt man die gesundheitspolitischen Entscheide der eigenen Regierung deutlich stärker.
Abb. 5: Ursachen der Probleme im Gesundheitssystem in der Schweiz (oben) und im weltweiten Vergleich (unten)
Studiendesign
Datenerhebungsmethode: Online-Befragung im intervista Online-Panel sowie in den Panels von 24 IRIS-Partnerinstituten; in zwei Ländern wurde die Stichprobe über einen externen Panelpartner erhoben Zielgruppe: Bevölkerung im Alter von über 18 Jahren, jeweils repräsentativ nach Alter, Geschlecht und Siedlungstyp Stichprobengrösse: Min. n = 500 pro Land, total n = 18’572 (maximaler Standardfehler für die Schweiz +/- 4.3 %, für alle Länder zusammen +/- 0.7 %) Feldzeit: Februar bis April 2023
Die Autorin Dr. Kim Buchmüller ist Projektleiterin beim Marktforschungsinstitut intervista. Sie promovierte an der Eidg. Technischen Hochschule Zürich (ETH Zürich) und ist Expertin für Fragestellungen zum Verhalten von Konsument:innen.
Da Nachhaltigkeit in unserem Leben und in den Medien eine immer grössere Rolle spielt, beeinflusst sie unweigerlich auch die Werbebranche. Die Anerkennung des Klimawandels und sozialer Themen wie Gender Equality und Diversity wächst und die Schweizer Konsumentinnen und Konsumenten erwarten, dass Marken verantwortungsvolle Massnahmen ergreifen. Doch wie können Werbung und Nachhaltigkeit ineinandergreifen, um eine nachhaltigere Zukunft und verantwortungsbewusstes Markenwachstum zu fördern?
Botschaften kombinieren
Im Zuge einer grossen, globalen Metaanalyse der Werbe-Pretest-Daten von Ipsos wurden Werbungen mit Botschaften zur Nachhaltigkeit identifiziert und deren Effektivität bewertet. Ipsos setzt für Werbepretests Creative|Spark ein. Eine Lösung, die in der Schweiz und international sowohl als Full-DIY aber auch begleitet durch Ipsos Schweiz Consultants über die Ipsos.Digital Plattform genutzt wird.
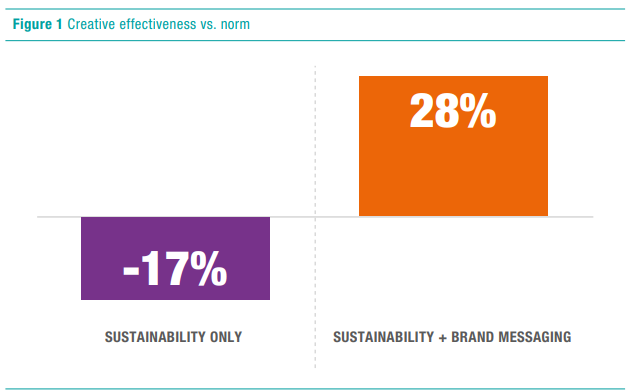
Die Auswertung zeigt, dass erfolgreiche Werbemassnahmen ein Gleichgewicht zwischen Nachhaltigkeit und den Markenbotschaften bieten. Werbungen, die sich ausschliesslich auf Nachhaltigkeit konzentrieren, übermitteln oft keine einzigartige oder unterhaltsame Botschaft. Bessere Ergebnisse erzielen Werbemassnahmen, die Marken- und Nachhaltigkeitsbotschaften kombinieren; das zeigt, wie wichtig es ist, die Botschaften zur und über die Marke nicht zu vernachlässigen.
Grafik 1
Eines von vielen positiven (internationalen) Beispielen ist diesbezüglich die Volvo-Kampagne «The Ultimate Safety Test».
Ein weiterer Trend bei Werbungen mit Bezug zur Nachhaltigkeit betrifft die Gestaltung der Botschaft. Werbungen, die sich auf die Menschen und ihre Probleme konzentrieren und eine nachhaltige Lösung anbieten, sind effektiver als solche, die nur über die Marke sprechen. Am wirksamsten sind Werbungen, die eine Lösung anbieten und die Konsumentinnen und Konsumenten in ein nachhaltiges Verhalten hineinziehen, indem sie ihnen diesen Schritt leicht machen.
Eine geringere Anzahl an Werbungen entscheidet sich dafür, direkt mit dem «Problem» zu beginnen, quasi als Einführung in das Nachhaltigkeitsthema, das sie behandeln werden. Solche Ansätze reichen von der Darstellung der Auswirkungen des Klimawandels bis hin zu lokalen Unternehmen in Schwierigkeiten oder von diskriminierten Minderheiten. Während der Aufbau von Problem und Lösung in der Werbung recht traditionell ist, sind die Probleme hier sehr ernst und können teilweise von der Zielgruppe auch als generisch wahrgenommen werden.
Empathie als Schlüssel
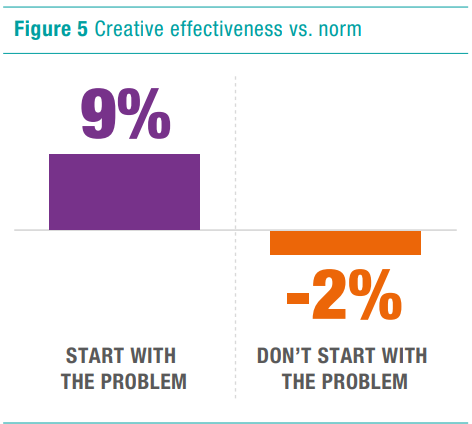
Funktioniert diese Art des Aufbaus gut, wenn es um Nachhaltigkeit und ernste Themen geht? Die Antwort ist: ja! Insgesamt übertreffen Werbungen, die mit dem Problem beginnen, andere Werbungen in Bezug auf ihre Wirksamkeit (+11 Prozent).
Grafik 2
Will man Teil der Lösung sein, ist das Anerkennen des Problems ein guter Anfang, Ein gutes Beispiel ist die «Forklift»-Kampagne von Sodastream. Der Spot geht sowohl auf Nachhaltigkeit als auch auf die Markenbotschaft ein: Im ersten Teil wird der übermässige Verbrauch von Plastikflaschen aufgezeigt. Im zweiten Teil wird den Zuschauerinnen und Zuschauern eine Lösung angeboten, wie sie zu kohlensäurehaltigem Wasser kommen – verknüpft mit den markanten Markenzeichen wie dem Geräusch der Sodastream-Flasche beim Befüllen mit Gas.
Wichtig ist hier die Empathie. Man sollte das Problem anerkennen, aber auf einer menschlichen, alltäglichen Ebene. Werbung, die den Menschen in den Mittelpunkt und das Thema Nachhaltigkeit in einen alltäglichen Kontext stellt, ist wirksamer als Werbung, die auf die beängstigenden Elemente des Klimawandels verweist. Versucht man, eine nachhaltige Botschaft zu vermitteln, ist es wichtig, sie visuell darzustellen. Dies kann mit Bildern oder Statistiken geschehen; die Werbung muss jedoch deutlich machen, worum es geht und wie die Marke zur Nachhaltigkeit beiträgt.
Ein weiterer wichtiger Aspekt betrifft die Glaubwürdigkeit. Um Anschuldigungen wegen Greenwashings und daraus resultierende Kritik zu vermeiden, müssen Marken sicherstellen, dass ihre Botschaften glaubwürdig und authentisch sind und ihre Versprechen zur Nachhaltigkeit eingehalten werden. Übertriebene Markenversprechen werden als wenig glaubhaft wahrgenommen und haben einen negativen Effekt. Kleine Schritte und Erfolge eines nachhaltigeren Produktes oder einer Dienstleistung, die mit der Nutzung der Marke durch den Konsumenten verknüpft sind, erzielen in der Regel bessere Ergebnisse.
Zusammenfassend lässt sich sagen, dass Werbung und Nachhaltigkeit Hand in Hand gehen können und sollten. Die Menschen wünschen sich, dass Marken sich für eine bessere Welt einsetzen und dies auch kommunizieren. Aber das blosse Hinzufügen einer Nachhaltigkeitsbehauptung zu einer Werbung ist nicht ausreichend. Werbungen müssen sich von anderen abheben, ein neues, ansprechendes und relevantes Erlebnis bieten und effektiv nachweisen, dass die Marke Teil der Lösung ist. Letztendlich stehen wir am Anfang eines schwierigen Übergangs zu einer nachhaltigeren Zukunft, in der noch viel zu tun ist. Dieser Übergang wird nicht ohne das Handeln der Marken und ohne überzeugende Werbemassnahmen zur Unterstützung dieser Veränderung stattfinden.
Die meisten Unternehmen erfassen Kundenfeedback durch Befragungen. Die von ihnen verwendeten Customer Feedback Metrics (CFMs) unterscheiden sich jedoch: Einige messen Kundenzufriedenheit, andere verwenden den Net Promoter Score (NPS) und wieder andere berechnen einen Kundenzufriedenheitsindex (CSI) – ein Mass für die Kundenzufriedenheit, das aus verschiedenen Indikatoren besteht. Insbesondere der NPS ist zu einer beliebten Kennzahl geworden, seit Reichheld (2003) ihn im Harvard Business Review veröffentlicht hat. Der NPS basiert auf der Wahrscheinlichkeit, ein Unternehmen weiterzuempfehlen, gemessen auf einer 11-Punkte-Skala. Befragte, die eine Bewertung zwischen 0 und 6 abgeben, gelten als Detractors, Befragte, die eine Bewertung zwischen 7 und 8 abgeben, gelten als Passives, und Befragte, die eine Bewertung zwischen 9 und 10 abgeben, gelten als Promoters. NPS ist definiert als Anteil Promoters minus Anteil Detractors. Der Wertebereich liegt somit zwischen –100 % und +100 %.
Laut Bain & Company (2020) gaben 77 % der an einer internationalen Umfrage teilnehmenden 1200 Führungskräfte an, dass ihre Unternehmen den NPS derzeit nutzen oder bis 2023 nutzen werden. Dennoch weisen sowohl Wissenschaftler:innen als auch Praktiker:innen auf dessen Nachteile hin:
– Der NPS erfordert einen grösseren Stichprobenumfang als CFMs, die auf Durchschnittsberechnungen beruhen.
– Er ist anfälliger gegenüber kulturellen Unterschieden als andere CFMs. Insbesondere in Ländern wie Japan oder Korea ist der NPS in der Regel niedriger.
– Er erklärt Zielgrössen wie Umsatzwachstum oder Kundenabwanderung nicht besser als andere CFMs.
In Bezug auf den letzten Aspekt haben sich bisherige Untersuchungen meist darauf konzentriert, den NPS mit anderen CFMs hinsichtlich der Fähigkeit zu vergleichen, Zielgrössen wie Umsatzwachstum oder Kundenabwanderung zu erklären – insbesondere, weil Reichheld (2003) auf der Grundlage von Korrelationsanalysen behauptet hatte, dass NPS in vielen Branchen die effektivste Kennzahl sei. Dabei wurden jedoch folgende Aspekte in der Regel nicht berücksichtigt:
– Kombinationen von CFMs,
– CFMs, die sich auf die Determinanten der Kundenzufriedenheit beziehen und
– CFMs mit affektiven Komponenten.
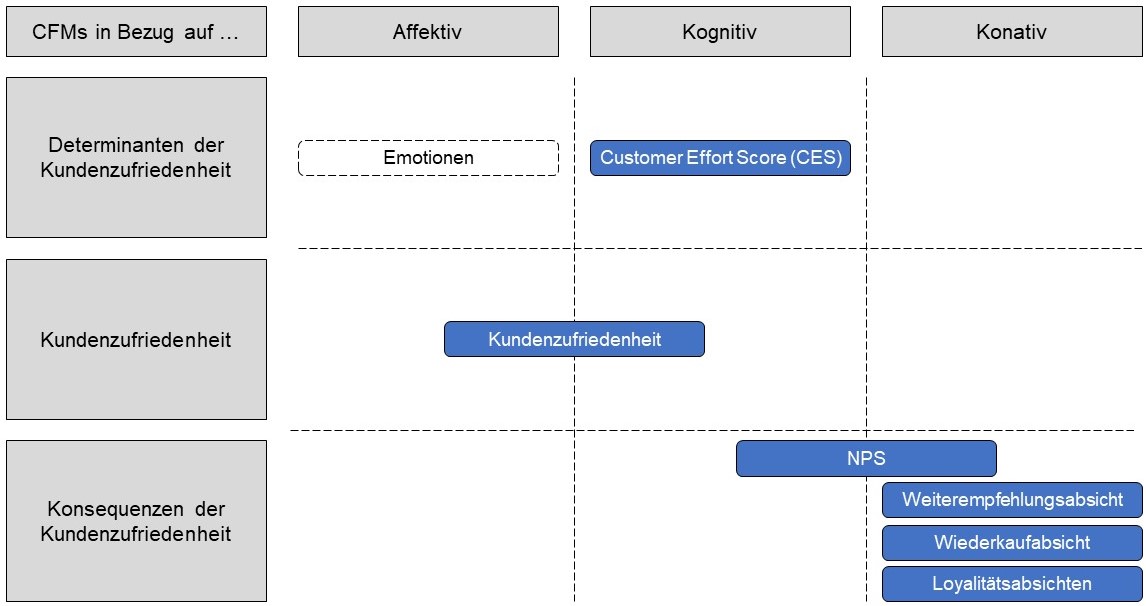
Abbildung 1: Kategorisierung der CFMs in bisheriger Forschung
Bisherige Forschung
Morgan und Rego (2006) antworten auf Reichheld (2003) mit Daten aus den USA. Sie testen sechs verschiedene CFMs sowie sechs verschiedene Zielgrössen und stellen fest, dass die Kundenzufriedenheit – gemessen mit drei Items gemäss American Customer Satisfaction Index (ACSI) – ein signifikanter Prädiktor für alle Zielgrössen ist, «Net Promoters» jedoch nicht. Sie messen jedoch nicht den NPS, wie von Reichheld (2003) vorgeschlagen. Daher können «Net Promoters» und NPS nicht verglichen werden. Keiningham et al. (2007) stellen auf der Grundlage von Daten aus Norwegen fest, dass keine der elf untersuchten CFMs ein signifikanter Prädiktor für Umsatzwachstum ist. Van Doorn et al. (2013) wiederholen die Untersuchung von Morgan und Rego (2006) in den Niederlanden, messen aber den NPS, wie ursprünglich von Reichheld (2003) vorgeschlagen. Sie stellen fest, dass alle CFMs – mit Ausnahme der Loyalitätsabsichten – signifikante Prädiktoren für das aktuelle (aber nicht für das zukünftige) Umsatzwachstum sind.
Ebenfalls in den Niederlanden betrachten De Haan et al. (2015) fünf CFMs und konzentrieren sich auf die Kundenabwanderung als Zielgrösse. Sie stellen fest, dass auf Unternehmensebene die Abwanderung in 10 von 18 Branchen durch mindestens eine CFM vorhergesagt werden kann. Der NPS ist in zwei Branchen die beste CFM.
Insgesamt bestätigt die bisherige Forschung somit, dass es keine einzelne, am besten geeignete CFM gibt, um insbesondere Zielgrössen wie Umsatzwachstum oder Kundenabwanderung zu erklären. Die meisten Untersuchungen berücksichtigen keine Kombinationen von CFMs. Ausnahmen sind Keiningham et al. (2007) und De Haan et al. (2015). Keiningham et al. (2007) finden keine Verbesserung, wenn sie Kombinationen von CFMs verwenden. De Haan et al. (2015) stellen fest, dass sich die Vorhersage von Kundenabwanderung verbessert, wenn NPS mit Kundenzufriedenheit oder Customer Effort Score (CES) mit Kundenzufriedenheit kombiniert wird.
Abbildung 1 gibt einen zusammenfassenden Überblick über die in der bisherigen Forschung verwendeten CFMs. Daraus leiten wir die folgenden Schlussfolgerungen und Forschungslücken ab:
Die meisten CFMs in bisheriger Forschung beziehen sich auf die Kundenzufriedenheit oder auf die Konsequenzen der Kundenzufriedenheit (z. B. NPS, Weiterempfehlungsabsicht, Wiederkaufabsicht, Loyalitätsabsichten).
Determinanten der Kundenzufriedenheit wurden meist nicht berücksichtigt. Customer Effort Score (CES) ist, wie von Dixon et al. (2010) vorgeschlagen, eine Ausnahme.
Die meisten der in Abbildung 1 dargestellten CFMs haben kognitive oder konative Komponenten. Daher betrachten wir CFMs, die sich auf die Determinanten der Kundenzufriedenheit beziehen und affektive Komponenten aufweisen, als Forschungslücke und schlagen vor, dass Unternehmen Emotionen messen sollten.
Wie bereits erwähnt, wurden in bisheriger Forschung meist keine Kombinationen von CFMs berücksichtigt, was wir als weitere Forschungslücke betrachten. Daher schlagen wir vor, dass Unternehmen sowohl NPS als auch Emotionen messen sollten.
Messung von Emotionen
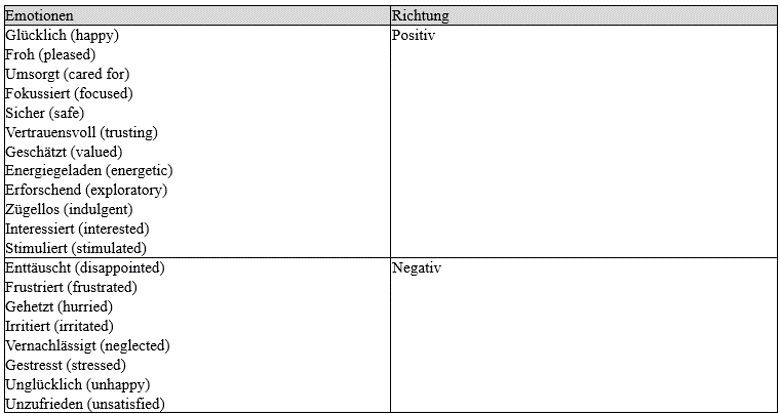
Obwohl Emotionen wichtige Determinanten der Kundenzufriedenheit sind, werden sie in der Praxis selten gemessen. Emotionen können unter anderem durch die Analyse von Texten oder durch die Analyse von Gesichtsausdrücken erfasst werden. Ebenso möglich ist die Messung durch Befragungen. Sowohl Wissenschaftler:innen als auch Praktiker:innen haben Messinstrumente für Befragungen entwickelt. Shaw (2007) schlägt vor, 20 Emotionen zu verwenden, davon zwölf mit positiver und acht mit negativer Richtung (siehe Tabelle 1). Er schlägt vor, Net Emotional Value (NEV) als positive Emotionen minus negative Emotionen zu berechnen. Daher liegt der Wertebereich zwischen –8 (wenn Kund:innen nur negative Emotionen haben) und +12 (wenn Kund:innen nur positive Emotionen haben).
Tabelle 1: Emotionen als Grundlage des NEV (Shaw, 2007)
Auf dieser Grundlage untersuchen wir die folgenden Forschungsfragen:
– Wie gut erklärt NPS Zielgrössen?
– Wie gut erklären Emotionen – gemessen durch NEV – Zielgrössen?
– Wie gut erklärt eine Kombination aus NPS und Emotionen – gemessen durch NEV – Zielgrössen?
Methodik
Wir haben n=599 Kund:innen von Mobilfunkbetreibern in Deutschland über ein ISO-zertifiziertes Online-Access-Panel befragt. Wir messen NPS wie von Reichheld (2003) vorgeschlagen und NEV wie von Shaw (2007) empfohlen. NPS und NEV sind somit die in unserer Studie untersuchten CFMs. Zielgössen sind die Wiederkaufsabsicht, die Cross-Buying-Absicht und der durchschnittliche Monatsumsatz.
Ergebnisse
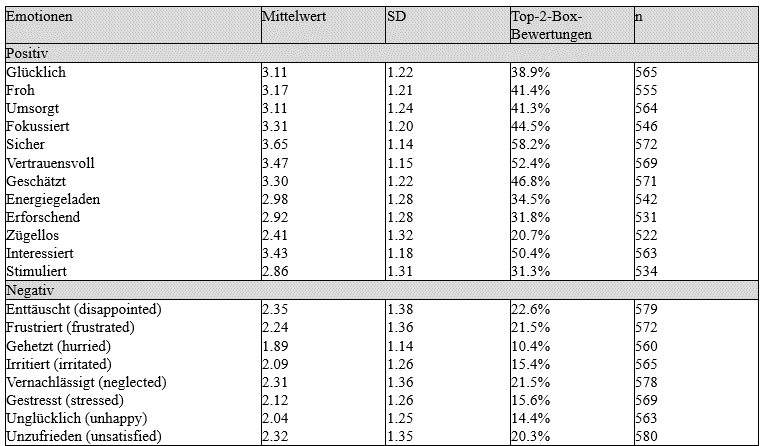
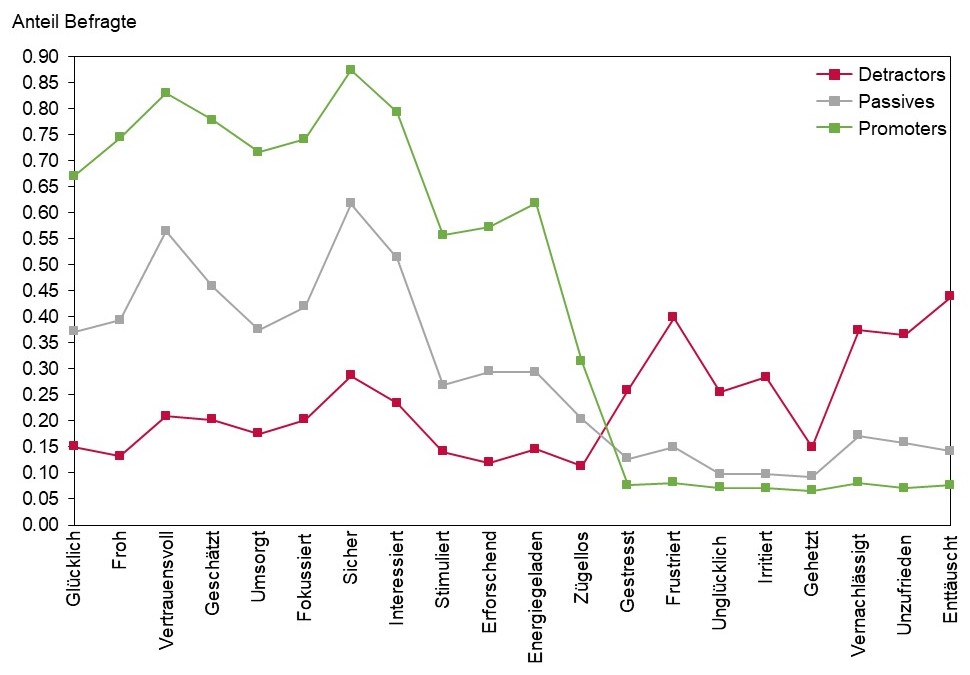
Tabelle 2 zeigt die deskriptiven Ergebnisse für die 20 Emotionen (Skala 1-5). Insgesamt sind die drei positiven Emotionen mit dem höchsten Mittelwert vertrauensvoll, sicher und interessiert, die drei negativen Emotionen mit dem höchsten Mittelwert vernachlässigt, unzufrieden und enttäuscht. Die Differenz in n ist auf eine «weiss nicht»-Option zurückzuführen.
Tabelle 2: Deskriptive Ergebnisse für NEV
Zur Berechnung des NEV auf Ebene der Befragten verwenden wir die Top-2-Box-Bewertungen. Wir gehen davon aus, dass die Befragten eine Emotion haben, wenn sie diese mit einer 4 oder 5 bewerten. Es wurden nur Befragte berücksichtigt, die alle Emotionen bewertet haben, was zu einer Stichprobengrösse von n=464 führt. Insgesamt erreichen 16,8 % aller Befragten einen negativen NEV (–8 bis –1), 16,4 % einen neutralen NEV (0) und 66,8 % einen positiven NEV (+1 bis +12).
Tabelle 3: ANOVA-Ergebnisse
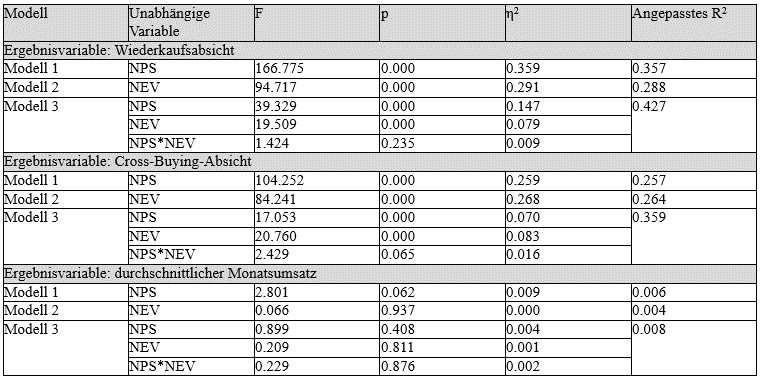
Um die Forschungsfragen zu untersuchen, führen wir ANOVAs mit drei verschiedenen Zielgrössen, d.h. abhängigen Variablen, durch: Wiederkaufabsicht, Cross-Buying-Absicht und durchschnittlicher Monatsumsatz. Wir testen drei Modelle, die sich in den unabhängigen Variablen unterscheiden: Modell 1 verwendet nur NPS, Modell 2 nur NEV und Modell 3 verwendet sowohl NPS als auch NEV. Für NPS verwenden wir die drei Kategorien Detractors, Passives und Promoters. Für NEV verwenden wir die Kategorien negativ, neutral und positiv. Mit Modell 1 und Modell 2 können wir vergleichen, wie viel Varianz NPS und NEV als einzelne CFMs erklären können. Mit Modell 3 können wir beurteilen, ob eine Kombination aus beiden CFMs mehr Varianz erklärt und ob es einen Interaktionseffekt zwischen NPS und NEV gibt. Tabelle 3 zeigt die Ergebnisse.
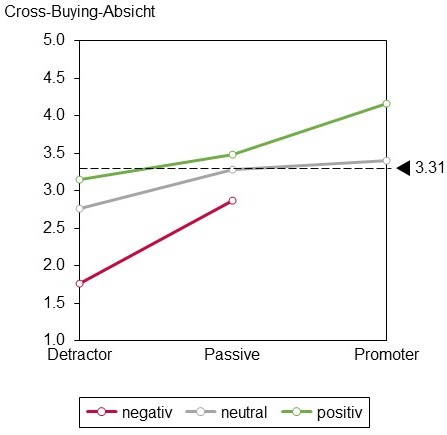
Für die Wiederkaufsabsicht als Zielgrösse erklärt Modell 3 die meiste Varianz (angepasstes R2 =0,427). Der Interaktionseffekt zwischen NPS und NEV ist nicht signifikant. Für die Cross-Buying-Absicht als Zielgrösse erklärt Modell 3 erneut die meiste Varianz (angepasstes R2 =0,359). Der Interaktionseffekt zwischen NPS und NEV ist signifikant, wie Abbildung 2 zeigt. Promoters mit einem positiven NEV haben eine höhere Cross-Buying-Absicht als Promoters mit einem neutralen NEV, und Detractors mit einem negativen NEV haben eine geringere Cross-Buying-Absicht als Detractors mit einem neutralen NEV. Für den durchschnittlichen Monatsumsatz als abhängige Variable ist Modell 1 marginal signifikant. Modell 2 und Modell 3 sind nicht signifikant.
Abbildung 2: Auswirkung der NPS- und NEV-Kategorie auf die Cross-Buying-Absicht
Diskussion
Unsere Ergebnisse zeigen, dass Emotionen die Wiederkaufsabsicht und die Cross-Buying-Absicht erklären – zusätzlich zum NPS. Daher empfehlen wir, NPS in Kombination mit Emotionen – zum Beispiel mit dem NEV – zu verwenden, um zusätzliche Erkenntnisse zu gewinnen. Wir stellen zum Beispiel fest, dass Promoters mit einem positiven NEV eine höhere Cross-Buying-Absicht haben als Promoters mit einem neutralen NEV und dass Detractors mit einem negativen NEV eine niedrigere Cross-Buying-Absicht haben als Detractors mit einem neutralen NEV.
Ein emotionales Profil für Detractors, Passives und Promoters liefert weitere Details. Abbildung 3 zeigt, dass sich Promoters hauptsächlich sicher (87 %), vertrauensvoll (83 %) und geschätzt (79 %) fühlen, während sich Detractors hauptsächlich enttäuscht (44 %), frustriert (40 %) und vernachlässigt (37 %) fühlen.
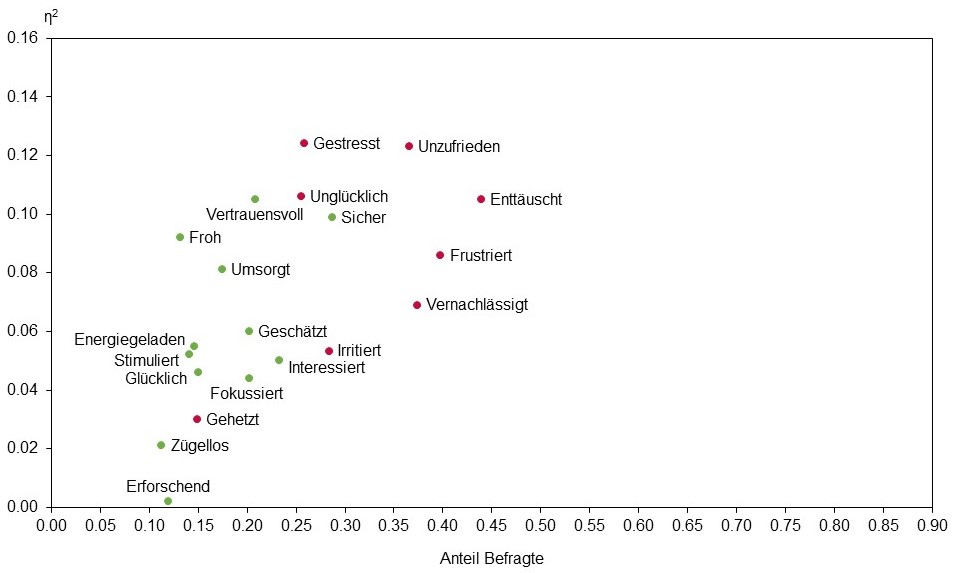
Um die Emotionen mit der höchsten Relevanz zu ermitteln, liefert eine Treiberanalyse weitere Ergebnisse. Abbildung 4 veranschaulicht dies für Detractors. Die horizontale Achse zeigt den Anteil der Befragten, die eine Emotion empfinden, die vertikale Achse zeigt die Relevanz dieser Emotion für die Cross-Buying-Absicht. Bei den Detractors hat z. B. “gestresst” die höchste Relevanz.
Abbildung 3: Emotionales Profil für Detractors, Passives, und Promoters
Abbildung 4: Treiberanalyse für Cross-Buying-Absichten für Detractors
Somit können Abbildung 3 und Abbildung 4 Teil eines Dashboards sein, das verschiedene CFMs kombiniert. Es ermöglicht eine detailliertere Analyse der verschiedenen NPS-Kategorien. Zusätzlich könnten weitere Split-Variablen (z. B. Vertriebskanäle oder Vertriebsregionen) hinzugefügt werden. Diese Erkenntnisse sind in der Werbung, aber auch bei persönlichen Interaktionen von Bedeutung. Die Mitarbeitenden in Pre-Sales, Sales und After-Sales sollten entsprechend geschult werden. Ausserdem könnte ein Monitoring der Emotionen auf der Grundlage verschiedener Datenquellen (z. B. Texte und Befragungen) eingerichtet werden.
Die Tatsache, dass der durchschnittliche Monatsumsatz kaum durch NPS oder NEV erklärt werden kann, lässt sich durch die Branche begründen. In der Mobilfunkbranche haben die Kund:innen Verträge mit Laufzeiten von 12 oder 24 Monaten, der durchschnittliche Monatsumsatz ist eher konstant. Anstatt die Ausgaben zu verändern, werden Kund:innen die Detractors sind oder einen negativen NEV haben, ihre Verträge eher nicht verlängern.
Limitationen
Wir sind uns bewusst, dass unsere Studie Limitationen hat:
Sie konzentriert sich auf eine Branche und auf ein Land. In anderen Branchen und anderen Ländern können Emotionen anders sein. Weitere Untersuchungen könnten daher die dem NEV zugrunde liegenden Emotionen anpassen beziehungsweise alternative Messinstrumente für Emotionen testen.
Wir haben die Zielgrössen durch subjektive Einschätzungen gemessen. Weitere Studien könnten objektive Masse verwenden, z. B. tatsächliches Wiederkaufverhalten, tatsächliches Cross-Buying-Verhalten und tatsächliche durchschnittliche Monatsumsätze, was jedoch den Zugang zu Transaktionsdaten erfordert.
Wir haben unsere Analyse auf der Ebene der Kund:innen durchgeführt. Weitere Untersuchungen könnten die Kombination von NPS und NEV auf Unternehmensebene untersuchen. Eine zeitliche Verzögerung bei den Zielgrössen könnte dann ebenfalls berücksichtigt werden.
Was die weitere Forschung betrifft, so sehen wir in verschiedenen Bereichen Potenzial:
Kund:innen schreiben Texte in E-Mails, in Social-Media-Posts oder in Foren. Dieser Text kann analysiert werden, um Emotionen zu erkennen. Weitere Forschungsarbeiten könnten die Ergebnisse auf Basis von Befragungen mit den Ergebnissen auf Basis von Texten vergleichen.
Ausserdem könnte, wie oben erwähnt, ein Monitoring von Emotionen eingerichtet werden. Emotionen könnten dann mit verschiedenen Touchpoints entlang der Customer Journey (Pre-Sales, Sales und After-Sales) verknüpft werden.
Die Unterschiede zwischen B2C und B2B sind ein weiterer Ansatzpunkt für zukünftige Forschung.
Schliesslich könnte die Rolle von Emotionen bei transaktionalen Befragungen näher untersucht werden. Hier könnten die Emotionen in Kombination mit dem CES gemessen werden. Auch könnten Emotionen gegenüber Mitarbeitenden von Emotionen gegenüber Unternehmen unterschieden werden.
Zusammenfassung
Net Promoter Score (NPS) ist eine der beliebtesten Customer Feedback Metrics (CFMs) – mit Vor- und Nachteilen. Bisherige Untersuchungen zeigen den Nachteil, dass er Zielgrössen wie Umsatzwachstum oder Kundenabwanderung nicht besser erklären kann als andere CFMs. Bisherige Untersuchungen haben jedoch meist keine Kombinationen von CFMs berücksichtigt. Wir argumentieren daher, dass NPS durch andere CFMs, z. B. Emotionen, ergänzt werden sollte. In einer empirischen Untersuchung in der Mobilfunkbranche nutzen wir den von Shaw (2007) vorgeschlagenen Net Emotional Value (NEV) zur Messung von Emotionen. Wir zeigen, dass eine Kombination aus NPS und NEV bei zwei von drei Zielgrössen zu einer besseren Erklärung führt. Wir veranschaulichen, wie Emotionsprofile und Treiberanalysen verwendet werden können, um konkrete Handlungsempfehlungen zu geben.
Dieser Beitrag ist eine Zusammenfassung des Artikels «Should Net Promoter Score be supplemented with other customer feedback metrics? An empirical investigation of Net Promoter Score and emotions in the mobile phone industry». Er ist verfügbar unter: https://doi.org/10.1177/14707853231219648
De Haan E, Verhoef PC and Wiesel T (2015) The predictive ability of different customer feedback metrics for retention. International Journal of Research in Marketing 32(2): 195 – 206.
Dixon M, Freeman K and Toman N (2010) Stop trying to delight your customers. Harvard Business Review 88(7/8): 116 – 122.
Keiningham TL, Cooil B, Aksoy L, Andreassen, TW and Weiner J (2007) The value of different customer satisfaction and loyalty metrics in predicting customer retention, recommendation, and share‐of‐wallet. Managing Service Quality 17(4): 361 – 384.
Morgan NA and Rego LL (2006) The value of different customer satisfaction and loyalty metrics in predicting business performance. Marketing Science 25(5): 426 – 439.
Reichheld FF (2003) The one number you need to grow. Harvard Business Review 81(12): 46 – 55. Shaw C (2007) The DNA of Customer Experience: How Emotions Drive Value. Houndmills: Palgrave Macmillan.
Van Doorn J, Leeflang PS and Tijs M (2013) Satisfaction as a predictor of future performance: A replication. International Journal of Research in Marketing 30(3): 314 – 318.
Prof. Dr. Steffen Müller
Dozent ZHAW School of Management and Law, Winterthur
In today’s dynamic digital landscape, marketers face a multitude of challenges when it comes to online advertising. One major hurdle is the phenomenon of banner blindness, where users have grown accustomed to online display ads and increasingly overlook them. Additionally, stringent regulations and mounting privacy concerns further complicate matters, making personalized ad targeting more challenging, which undermines overall effectiveness.
Amidst these challenges, the swift evolution of digital marketing has birthed a compelling solution: influencer marketing. As individuals dedicate more time to social media platforms, brands have recognized the potential of collaborating with influencers to engage audiences authentically and drive results.
However, despite the exponential growth of the influencer-marketing industry and the increasing number of firms leveraging influencers for promotional activities, a notable gap persists in comprehending the genuine return on investment (ROI) generated by these campaigns. This gap encompasses both the immediate revenue achieved and the associated costs.
In response, our comprehensive study investigates this critical aspect and illuminates the entire influencer marketing funnel (i.e., from followers on a social media platform, to reached followers, to engagement with the sponsored posting, and to actual revenue), offering invaluable insights to firms seeking to optimize their influencer marketing policy. By identifying influencers who deliver tangible ROI, firms can navigate the complexities of digital marketing with confidence and precision.
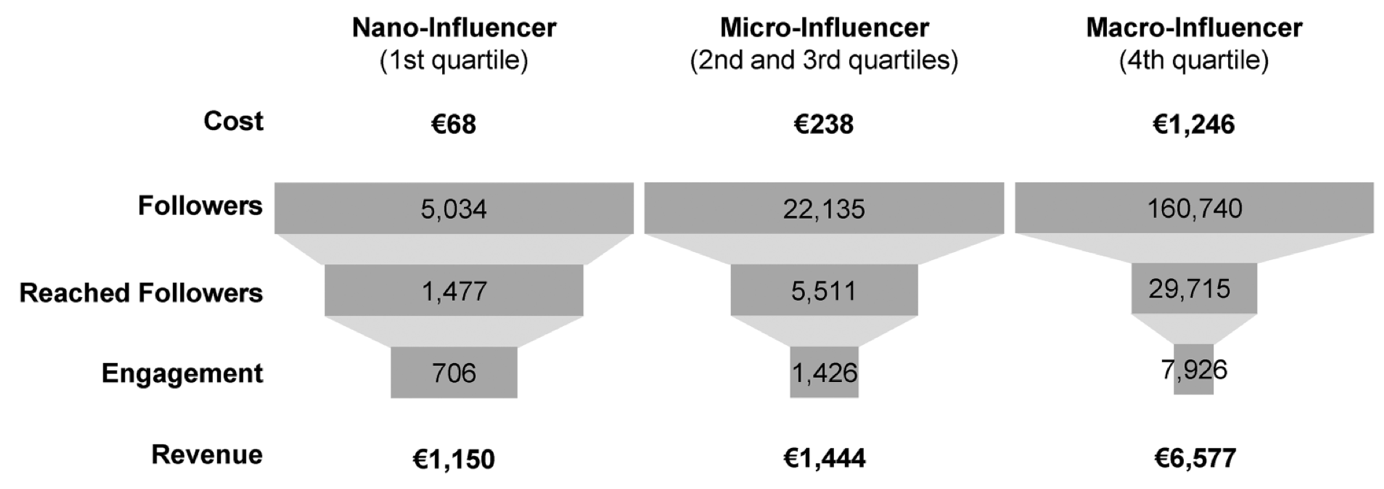
Our empirical/experimental evidence leads us to an intriguing conclusion: nano-influencers, those with a smaller following, are more cost-effective in revenue generation compared to their macro counterparts. This finding challenges the prevalent industry norm that attributes a higher value on influencers with more followers. We find that the engagement between influencers and their followers plays a crucial role in this dynamic. In essence, a more intimate connection between nano-influencers and their followers leads to more effective marketing outcomes. We find that around 1.5% of the usual nano-influencer’s followers would convert to buying, while it is only 0.2% for a macro-influencer.
Figure 1. Funnel Comparison of Nano-, Micro-, and Macro-Influencers.
Figure 1 shows a comparison of typical influencer-marketing funnels between nano-, micro- and macro-influencers. Note that of course these numbers might change given the platform and context. However, we expect the overall trend to persist: a nano-influencer outperforms a micro- and macro-influencer in each stage of the funnel with a higher percentage of the previous funnel step converting to the next funnel step. For example, for a nano-influencer around 700 out of 5,000 (14%) followers would typically engage, while for macro influencer 8,000 out of 160,000 (5%) followers would typically engage. This trend continues until the for a firm crucial step of converting followers of the paid influencer (and the sponsored post) into customers.
We analyze data from one of Europe’s leading direct-to-consumer firms, which includes influencer-specific discount codes shared on Instagram linked to nearly 1.9 million sold products, amounting to over €17 million in revenue. In addition, we analyze data from YouTube and TikTok as well as from three distinct field studies with 319 paid nano- and macro-influencers on Instagram, resulting in a combination of empirical and experimental evidence across platforms.
A key aspect of our study is examining the level of engagement on an influencer’s profile before a sponsored post. We follow social capital theory, which suggests that influencers with more followers might encounter lower engagement levels with their followers. And indeed, empirical data confirms this notion. We also use language style matching on more than 500,000 comments and replies to delve deeper into the relationship between influencers and their followers. Our findings indicate that nano-influencers align more closely with their followers’ communication styles, enhancing their relatability and effectiveness in influencer marketing.
These insights hold major implications for firms and marketers. The industry’s focus on macro-influencers needs a reevaluation in light of our findings. Brands should consider leveraging nano-influencers, especially for campaigns with a sales focus. This approach not only promises higher ROI but also fosters a more authentic connection with audiences. Nowadays, this is easily feasible through influencer-marketing tools that provide the infrastructure to manage hundreds of influencers at scale and automate processes such as example Kingfluencers or Rearchbird.
In conclusion, our study suggests that firms and marketers should consider the (ROI-)impact of nano-influencers. By doing so, they can unlock new potentials in influencer marketing, ensuring that their investments yield higher returns.
Das offizielle Inkrafttreten des KI-Gesetzes der EU (d.h. wenn der definitive Text fixiert ist und keine Veränderung mehr möglich ist) sollte bis Ende März 2024 erfolgen. Voraussetzung dafür ist eine formelle Annahme seitens des EU-Parlaments und des EU-Rats. Die Bestimmungen des Gesetzes werden nach einer zweijährigen Übergangsfrist angewendet, die dann bis 2026 laufen würde. Während dieser Zeit werden technische Umsetzungsstandards erarbeitet, welchen sich die betroffenen Firmen anpassen müssen. Zu beachten ist, dass bestimmte Verbote bereits nach sechs Monaten wirksam werden.
Was bedeutet das für Schweizer Unternehmen?
Schweizer Unternehmen müssen mit Anpassungen in den Verträgen mit ihren KI-Lieferanten rechnen. Um eine allfällige Unterstellung rechtzeitig zu identifizieren, müssen sich die Unternehmen bewusst werden, wo und wie sie KI einsetzen. Diese Unterstellung kann direkt aufgrund einer Tätigkeit in der EU oder indirekt aufgrund der Tätigkeit der Kundschaft gegeben sein.
Rechte und Pflichten
Welche Rechte und Pflichten führt das KI-Gesetz ein?
Klassifizierung der KI-Anwendung: Entwickler:innen und Verwender:innen von KI müssen klären, unter welche Risikokategorie sie fallen und ob sie KI in einer unzulässigen Weise verwenden. Diese Differenzierung kann in Einzelfällen, insbesondere bei Emotions-Erkennung oder Manipulation des Verhaltens, unklar sein, sodass unbedingt eine Risikoabwägung vorgenommen werden muss. Je nach Risikoart der angewandten KI muss sichergestellt werden, dass entweder Entwicklung, Anwendung und Überwachungsmassnahmen der KI korrekt dokumentiert sind oder die notwendige Transparenz gegenüber den Nutzer:innen sichergestellt wird, wenn KI in der Kundenbeziehung oder beim Erstellen von Texten und Bildern eingesetzt wird. Dazu muss gewährleistet sein, dass bereits bestehende Regelungen beim Einsatz der neuen Möglichkeiten der KI nicht unbeabsichtigt verletzt werden.
Wie beginnt man?
Es ist für jede Firma essenziell, ihre KI-Nutzung zu evaluieren und dabei folgende drei Kernfragen zu beantworten:
Wo nutze ich KI?
Wer entscheidet über den Einsatz von KI?
Welche Folgen könnte KI für meine Kund:innen und Mitarbeitenden haben?
Mauro Quadroni RA und CTO bei AI Legal & Strategy Consulting AG
Als Marktforschungsunternehmen ist es für LINK von grösster Bedeutung, dass das Panel eine hohe Repräsentativität aufweist, die für valide und stabile Ergebnisse steht. Die Volvo Car Switzerland AG hat im Frühjahr 2021 eine schweizweite Studie mit 1’047 Befragten durch das LINK Panel in Auftrag gegeben. Im gleichen Zug beauftragte Volvo einen externen Partner – Crosswind – mit Geoanalysen, weshalb auch einige Fragebogeninhalte vorgängig auf diese Analysen abgestimmt wurden. Vor dem Start der Geoanalysen wurden die durch LINK erhobenen Umfragedaten durch Crosswind eingehend geprüft und mit externen Daten validiert.
Diese Validierung hatte das Ziel, sicherzustellen, dass die Ergebnisse der Geoanalysen durch Crosswind auch auf einer detaillierten geographischen Ebene, wie z.B. den Kantonen, verlässliche und belastbare Ergebnisse liefern. Da die Fallzahlen auf diesen Ebenen in der Regel sehr gering sind und oft gar keine Informationen in Form von Interviews vorliegen, beeinflussen einzelne Aussagen das Ergebnis stark. Die Repräsentativität ist daher von besonderer Bedeutung, da nur auf ihrer Basis auch bei geringer Fallzahl regional spezifische Erkenntnisse gewonnen werden können.
Die externe Validierung durch Crosswind hat bei der Auftraggeberin grosses Vertrauen in die Repräsentativität des LINK Panels geschaffen, wie Beat Fritschi, Business & Retailer Development Director bei Volvo betont: «Bei der durch Crosswind durchgeführten externen Validierung wurden Ergebnisse aus der Umfrage von LINK und öffentlich zugängliche Daten zum Fahrzeugmarkt gegenübergestellt. Das Resultat dieses Vergleichs hat gezeigt, dass die Ergebnisse der LINK-Umfrage auch auf sehr detaillierter räumlicher Ebene repräsentativ sind. Dies hat unser Vertrauen in die weiteren Umfrageergebnisse verstärkt.»
Hohe Repräsentativität durch aktiven Rekrutierungsansatz
LINK verfolgt verschiedene Massnahmen, um die Repräsentativität ihres Panels zu gewährleisten. Repräsentativität bedeutet, dass jedes Element der Grundgesamtheit (d.h. alle potenziell Befragten) eine eindeutig definierte und von Null verschiedene Wahrscheinlichkeit besitzt, in die Stichprobe aufgenommen zu werden («Zufallsauswahl»). Nur repräsentative Stichproben stellen ein wirklichkeitsgetreues Abbild der Grundgesamtheit dar und erlauben eine Verallgemeinerung des Ergebnisses auf die Grundgesamtheit (marktforschung.de).
LINK nutzt einen speziellen Rekrutierungsansatz, bei dem das Panel zu 100 % aktiv über telefonische Studien mit Festnetz- und Mobilnummern rekrutiert wird. Zum einen kann hiermit sichergestellt werden, dass es sich bei den Befragten um echte Personen handelt (direkte Verifizierung am Telefon), zum anderen kann so ein Grossteil der Bevölkerung erreicht werden. Jede Person hat folglich dieselbe Chance (oder zumindest eine bekannte Chance), ins Panel aufgenommen zu werden. Ausserdem ist die Hemmschwelle für Mehrfachanmeldungen höher und Mehrfachteilnehmende können einfacher ausgeschlossen werden.
Zusätzlich nutzt LINK verschiedene Massnahmen, um Verzerrungen durch Selektionsprozesse oder Nichtteilnahmen entgegenzuwirken – beispielsweise Speeder-Identifikation, Qualitäts-Flagging bei auffälligem Antwortverhalten oder Tracking wichtiger KPIs und Feedback zur Gestaltung angenehmer Fragebögen und Ausfülldauer.
Validierungsprozess anhand von Geodaten am Beispiel von LINK und Crosswind
Die externe Validierung anhand von Geodaten besteht darin, die Repräsentativität eines Panels aufgrund seiner räumlichen Verteilung zu überprüfen. Eine hohe Repräsentativität zeichnet sich dadurch aus, dass unter anderem auch im Rekrutierungsprozess unkontrollierte Merkmale korrekt beziehungsweise bevölkerungsrepräsentativ abgebildet werden. 1’000 Befragte stellen eine gute Grundlage dar, um auf nationaler Ebene sowie differenziert nach den Sprachregionen Deutschschweiz, Westschweiz und Tessin solide und belastbare Ergebnisse zu liefern. Bei geographischen Analysen auf detaillierteren räumlichen Skalenebenen wie der Kantons- oder der Bezirksebene verringern sich jedoch die Fallzahlen regional teilweise stark, wodurch sich Verzerrungen in der Stichprobe bzw. nicht zufriedenstellende Repräsentativität schneller auf die Validität eines regionalen Ergebnisses auswirken.
Im Folgenden wird der Ablauf der Validierung der Daten, die LINK im Rahmen der Umfrage für Volvo erhoben hat, aufgezeigt:
Zunächst wurde der Marktanteil pro Automarke am gesamten Fahrzeugbestand untersucht. Hierfür wurde als erste Kennzahl der reale Anteil jeder Automarke pro Kanton (Stand: September 2021) berechnet; dies auf der Grundlage der öffentlich zugänglichen Fahrzeugmarktdaten des Bundesamtes für Strassen ASTRA. Als zweite Kennzahl wurde der Anteil jeder Automarke pro Kanton der 1’047 Umfrageteilnehmenden betrachtet. Diese zweite Kennzahl zeigt also, wie hoch der effektive Marktanteil der Automarken unter den Umfrageteilnehmenden ist.
Die Übereinstimmung dieser beiden Kennzahlen (realer Marktanteil vs. Marktanteil laut Studienteilnehmenden) kann als Mass für die Repräsentativität der Umfrage interpretiert werden.
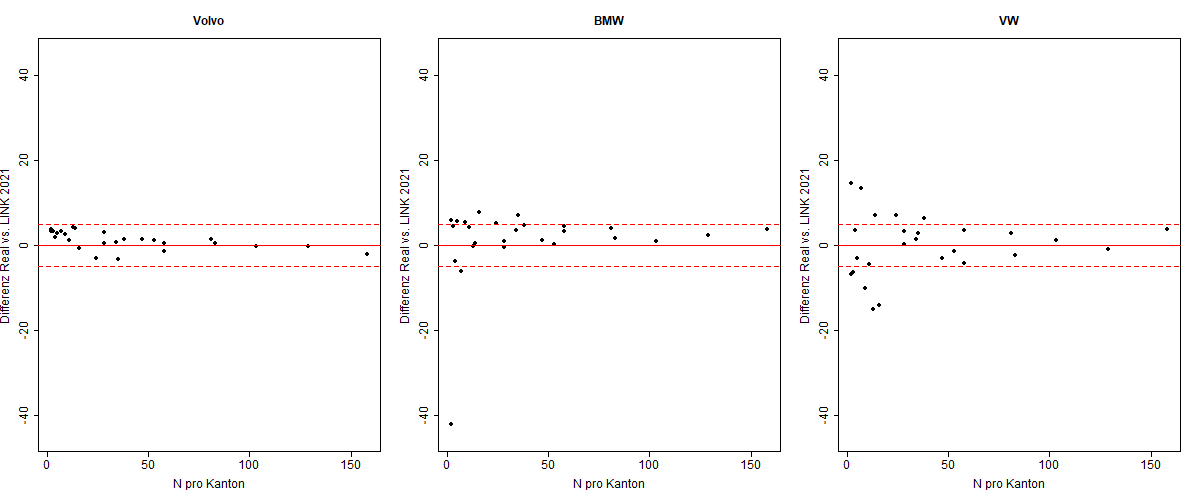
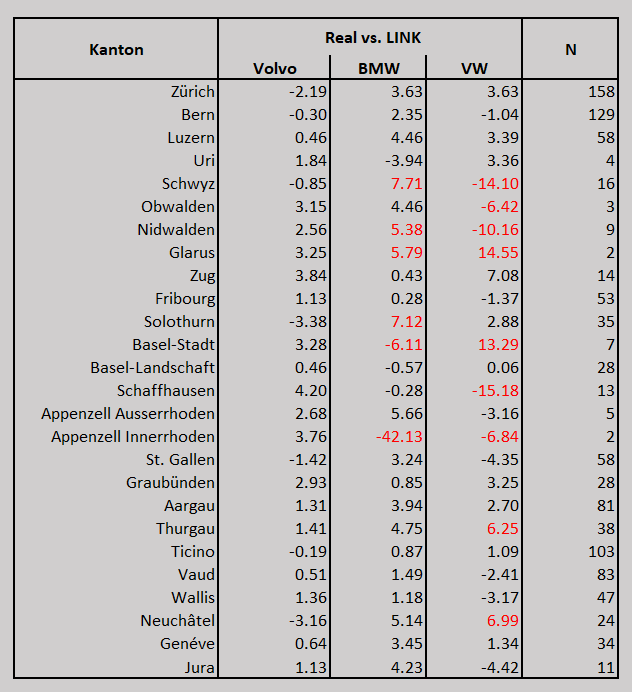
Für die Automarke Volvo beträgt die Abweichung weniger als 5 Prozentpunkte über alle Kantone hinweg, bei BMW und VW existiert eine Abweichung von höchstens 15 Prozentpunkten bei kleineren Fallzahlen. Den einzigen Ausreisser bildet BMW im Kanton Appenzell Innerrhoden, was mit einer Fallzahl von nur 2 Befragten jedoch leicht zu erklären ist. Ein Zusammenhang zwischen der Fallzahl und den Abweichungen wird in Abbildung 1 visualisiert. Ab einer Fallzahl von etwa 15 Befragten liegt die Differenz bei ca. 7 Prozentpunkten oder weniger, und ab ca. 40 Befragten bei 5 Prozentpunkten oder weniger.
Die Resultate der Validierung zeigen folglich, dass die Abweichungen verhältnismässig klein sind, auch bei kleinen Fallzahlen. Dies ist überraschend, insbesondere auch deshalb, da die Umfrage für die Analysen nicht gewichtet wurde. Dies stützt das Argument der Repräsentativität der Umfrage auf der räumlichen Skalenebene «Kanton».
Abbildung 1: Dargestellt ist auf der Y-Achse die Differenz pro Kanton zwischen realem Marktanteil und Anteil der Marken unter den Studienteilnehmenden und auf der X-Achse die Anzahl Befragte pro Kanton. Die rote durchgezogene Linie markiert 0 Prozentpunkte Abweichung. Die gestrichelte rote Line markiert +/- 5 Prozentpunkte Abweichung. Insgesamt zeigen die Ergebnisse eine sehr hohe Übereinstimmung zwischen Umfrageergebnissen und (öffentlich zugänglichen) realen Daten auf. Ausreisser entstehen vereinzelt durch sehr kleine Fallzahlen. Bereits ab einer Fallzahl von etwa 15 Befragten liegt die Differenz bei kleiner gleich 7 Prozentpunkten.
Bedeutung von regionaler Betrachtung der Markenloyalität für Volvo
Im nächsten Schritt nach der oben beschriebenen Validierung wurde erneut der Anteil der Automarken unter den 1’047 Studienteilnehmenden verwendet. Neu wurde diese Kennzahl nun aber der zusätzlich in der Umfrage erhobenen Markenpräferenz gegenübergestellt. Die Studienteilnehmenden gaben hier an, welche Automarken sie bei einer möglichen Neuanschaffung innerhalb der nächsten drei Jahre präferieren. Die Übereinstimmung des Marktanteils und der Markenpräferenz wurde als Markenloyalität interpretiert, da eine Übereinstimmung bedeutet, dass eine Person eine Automarke besitzt und diese auch künftig präferieren würde (oder nicht besitzt und auch zukünftig nicht präferiert). Eine differenzierte regionale Betrachtung der Markenloyalität und Markenpräferenz ist in Zeiten von Unsicherheit und schnellen Veränderungen im Automobilsektor von grosser Bedeutung. Durch die Studie kann die Markenloyalität auf den Prüfstand gestellt und ein besseres Verständnis für (potenzielle) Kundinnen und Kunden gewonnen werden.
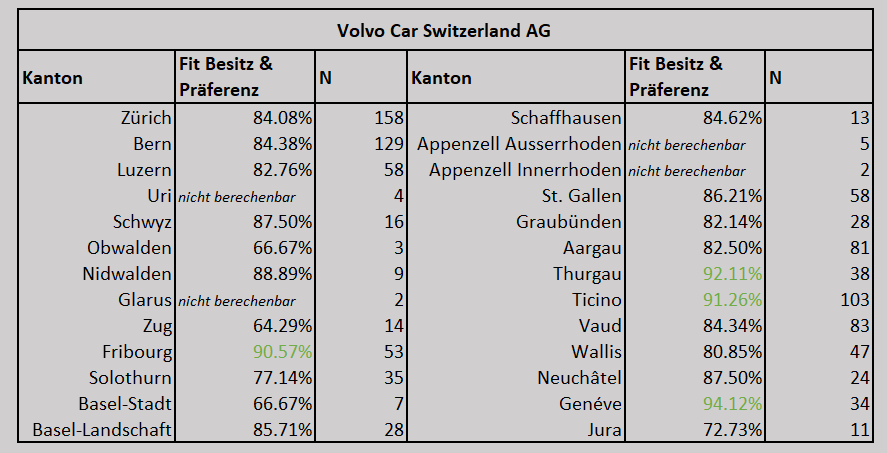
Die Resultate in Tabelle 1 zeigen, dass die Markenloyalität für Volvo regional variiert und im Durchschnitt bei 83 % liegt, wobei sie in Zug mit 64 % am niedrigsten und in Genf mit 94 % am höchsten ist. Diese Resultate sprechen einerseits für eine hohe Markenloyalität der Volvo-Kundinnen und -Kunden (auch im Vergleich zu anderen Marken, was in diesem Artikel jedoch nicht weiter beleuchtet wird), betonen aber andererseits auch, in welchen Regionen mit niedriger Markenloyalität Potenziale oder Notwendigkeiten für eine Neupositionierung bestehen. Eine Möglichkeit kann in der veränderten Nutzung der Vertriebskanäle und somit in der Kundenansprache bestehen. In der Umfrage wurde hierzu unter anderem die Bereitschaft der Befragten für einen Direktvertrieb durch den Online-Kauf von Neuwagen erhoben. Mit den Ergebnissen konnte Volvo ihre Strategie zum Direktvertrieb überprüfen, weiterentwickeln und bereits mit ersten Erfolgen (erste Online-Bestellungen von Neuwagen) in die Tat umsetzen.
Tabelle 1: Gezeigt wird der Anteil der Übereinstimmung bei den Befragten von Markenpräferenz und Besitz dieser Marke (Erst- und/oder Zweitwagen) pro Kanton (Fit Besitz & Präferenz) – auch Markenloyalität. Nicht berechenbar ist dieser Wert, wenn in einem Kanton für keine der Befragten Informationen zu Markenpräferenz und/oder Besitz existieren, z.B. durch das Ankreuzen der Antwortoption «weiss nicht / keine Angabe». Wie gut der Besitz von Volvo zur Markenpräferenz von Volvo passt, variiert regional. Meist liegt die Markenloyalität um die 80%.
Repräsentativität LINK Panel und neue Erkenntnisse durch Geoanalysen von Crosswind
Abschliessend lässt sich durch die gezeigten Resultate festhalten, dass die Volvo Car Switzerland AG dank den Umfrageergebnissen in Kombination mit den Geoanalysen neue Erkenntnisse hinsichtlich der aktuellen Marktgegebenheiten und der Präferenzen ihrer Kundinnen und Kunden gewinnen konnte. Die regional differenzierten Einsichten konnten zur Weiterentwicklung und Schärfung der Markenstrategie zur künftigen Netz-Entwicklung sowie für die (geografische) Optimierung ihrer Vertriebskanäle genutzt werden.
Grundlage dafür ist die sehr gute Repräsentativität des LINK Panels, was die Validierung der Umfrageergebnisse gezeigt hat: Trotz kleiner Stichprobengrösse werden auch nicht kontrollierbare Merkmale wirklichkeitsnahe (räumlich) abgebildet.
Tabelle 2: Differenz in Prozentpunkten Marktanteil Real vs. Marktanteil LINK pro Kanton
Dr. Verena Mack Senior Research Consultant Marketing Research LINK
Während in der Marktforschung reine Online-Interviews, sogenannte Computer-Assisted Web Interviews (CAWI), längst Standard sind, hat sich der Anteil an Online-Interviews in der Sozialforschung in den letzten Jahren vergleichsweise langsam erhöht. Oftmals dominieren hier noch Computer-Assisted Telephone Interviews (CATI), Computer-Assisted Personal Interviews (CAPI), Paper and Pencil Interviews (PAPI) oder verschiedene Mixed-Mode-Ansätze. Dennoch haben gerade in der Schweiz auch einige wichtige Erhebungen in der Sozialforschung wie die Schweizerische Arbeitskräfteerhebung die primäre Erhebungsmethode zu Online-Interviews geändert. Obwohl Online-Interviews gegenüber allen anderen Erhebungsmethoden einen deutlichen Kostenvorteil bieten, setzen viele Behörden noch auf andere Erhebungsmethoden. Dieser Artikel soll aufzeigen, woran dies liegt und wie die mit einem Wechsel verbundenen Herausforderungen adressiert werden können.
Selektionseffekte
Alle genannten Erhebungsmethoden bringen Vor- und Nachteile mit sich. Online-Interviews sind meist die günstigste Erhebungsmethode, während CAPI im Normalfall die kostspieligste Erhebungsmethode darstellt. Die beiden anderen Methoden sind dazwischen anzusiedeln. Während Online-Interviews natürlicherweise nur die Onlinebevölkerung erreichen, erreicht CATI nur Menschen mit Telefon. Mit PAPI und CAPI kann fast die ganze Bevölkerung erreicht werden.
Obwohl grundsätzlich die meisten Erhebungen den Anspruch haben, eine Stichprobe zu generieren, die repräsentativ für eine gewisse Population ist, kann keine der Erhebungsmethoden dies garantieren, solange die Teilnahme an der Erhebung freiwillig ist. Da eine Teilnahmeverweigerung durch die Eingeladenen erfolgt, ist diese nicht zufällig; die Selbstselektion der Teilnehmenden führt damit zu Verzerrungen der Nettostichprobe. Man versucht solche Verzerrungen auszugleichen, indem man gewisse Bevölkerungsteile überproportional einlädt, die Stichproben gewichtet oder einen Mix der Methoden anwendet.
Erhebungsmethodeneffekte
Zusätzlich verzerren die verschiedenen Methoden die Antworten der Teilnehmenden unterschiedlich. Sowohl CATI als auch CAPI sind Methoden, bei denen eine interviewende Person in die Erhebung involviert ist. Studien haben gezeigt, dass dies zu sogenannten Interviewer-Effekten führt, d.h. Teilnehmende antworten eher zurückhaltender und eher im Sinne eines gesellschaftlich gewünschten Ideals. In beiden Methoden tendieren Teilnehmende zudem dazu, zuletzt genannte Antworten überproportional häufig zu wählen. Bei selbstadministrierten Erhebungen wie Online-Interviews und PAPI ist dies genau umgekehrt. Zudem gibt es bei diesen Methoden keine Interviewer-Effekte.
Tabelle 1: Ausschöpfung nach Treatmentgruppen in Welle 2 in Prozent der Nettostichprobe der ersten Welle Quelle: Eigene Darstellung nach Voorpostel et al. (2020).
Bedeutung der Verzerrungen
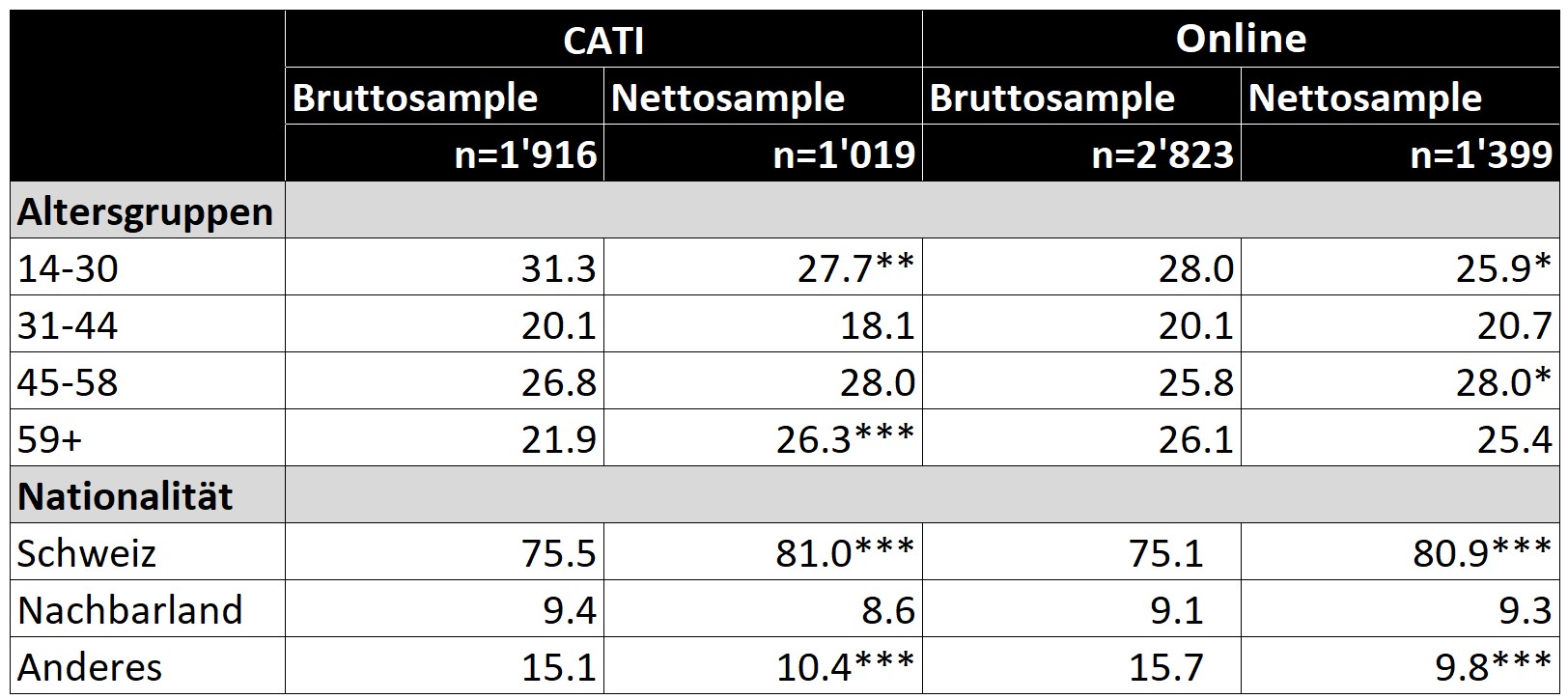
Für die richtige Methodenwahl ist es entscheidend, die Grössenordnungen der Verzerrungen zu kennen. Einige Studien nutzen Mixed-Mode-Erhebungen, bei denen sich die Datensätze der unterschiedlichen Teil-Erhebungen vergleichen lassen. Allerdings lassen sich daraus in den meisten Fällen keine sinnvollen Schlüsse ziehen, da die Selektion der Befragungsmethode den Teilnehmenden überlassen wird. So überlagern sich Effekte von Erhebungsmethode und Selektion, die ex-post nicht mehr unterschieden werden können. Zur Unterscheidung dieser beiden Effekte bei einem Erhebungsmethodenwechsel gibt es trotz der hohen Relevanz in der Schweiz kaum Forschung. Eine der wenigen Ausnahmen bildet die Studie von Voorpostel et al. (2020), die in einem experimentellen Design die Umstellung des Schweizer Haushalt-Panel (SHP) von CATI auf Online-Interviews als primäre Erhebungsmethode untersuchten. Für das Experiment wurden drei unterschiedlich grosse zufällige Bruttostichproben gezogen, eine für CATI, eine für einen Mixed-Mode und eine für eine Onlinebefragung. Zur leichteren Lesbarkeit wird hier nicht weiter auf den Mixed-Mode eingegangen. Voorpostel et al. (2020) finden zwar für Online-Interviews mit 38.5% eine initial geringere Teilnahmebereitschaft bei der Rekrutierung als bei CATI mit 48.7%, aber für beide Methoden eine ähnliche Panelsterblichkeit (vgl. Tabelle 1).
Wenig überraschend sind beide Nettostichproben nicht komplett repräsentativ für die Bevölkerung. Tabelle 2 zeigt das Ergebnis zweiseitiger z-Tests, ob die jeweiligen Anteile der Nettostichproben denjenigen der Bruttostichproben entsprechen. In beiden Nettostichproben ist die jüngste Altersgruppe untervertreten. Individuen über 58 Jahre sind in der CATI-Stichprobe übervertreten, während in der Online-Stichprobe diese Altersgruppe keinen signifikanten Unterschied zum Bruttosample aufweist. Bei der Nationalität sind beide Nettostichproben sehr ähnlich verzerrt.
Tabelle 2: Stichprobenanteile nach Treatmentgruppen in Welle 1 (in Prozent) *p<0.10, **p<0.05, ***p<0.01. Quelle: Eigene Darstellung nach Voorpostel et al. (2020).
Die Online-Interview-Teilnehmenden weisen zwar in allen Wellen und Interviewteilen eine höhere Rate an nicht beantworteten Items auf, aber bei den meisten Variablen resultiert kein Unterschied zwischen den beiden Stichproben. Dies könnte unter anderem auf eine zufällige Antwortwahl der zusätzlich Antwortenden in der CATI-Stichprobe hindeuten.
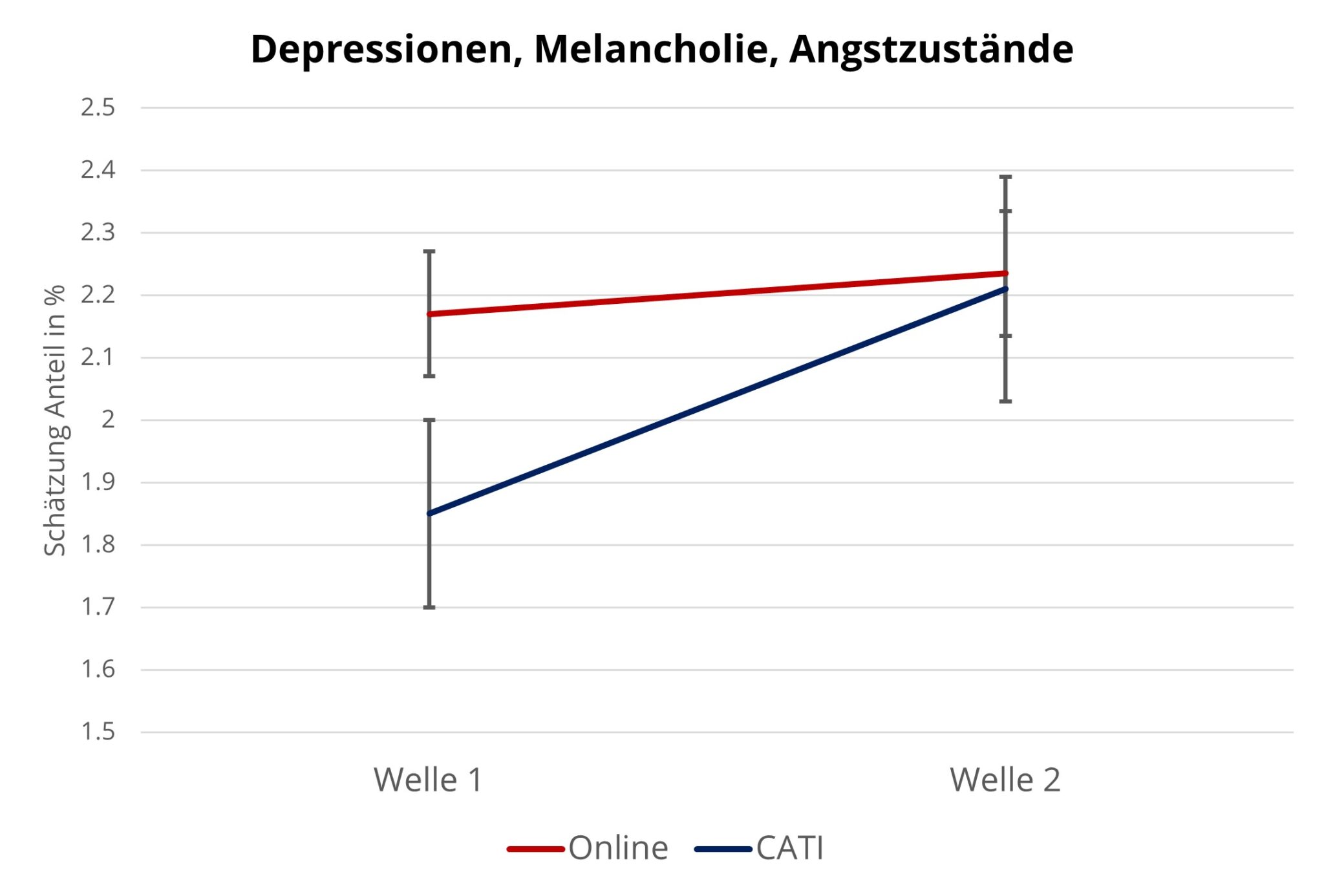
Der Interviewer-Effekt bei CATI tritt hingegen zum Beispiel bei Gesundheitsfragen in Welle 1 deutlich zu Tage, wie Abbildung 3 zeigt. Interessanterweise verschwindet er aber in Welle 2, d.h. wenn die Teilnehmenden ein zweites Mal befragt werden. Da die Analysemethode versucht, den Selektionseffekt zu kontrollieren, ist es unwahrscheinlich, dass das Verschwinden des Interviewer-Effekts rein aufgrund einer Selektion in der zweiten Welle geschieht. Vielmehr könnte ein Gewöhnungseffekt dieses Phänomen erklären. Also beeinflussen solche Gewöhnungseffekte die intertemporale Vergleichbarkeit von Studien, bei denen Individuen in mehreren Wellen befragt werden, selbst wenn die Methode konstant bleibt.
Abbildung 3: Interviewer-Effekt bei Gesundheitsfragen Quelle: Eigene Darstellung nach Voorpostel et al. (2020)
Entwicklung Verzerrungen
Während die Effekte auf die Antworten der Teilnehmenden konstant sind, verändern sich die Selektionseffekte mit der Zeit. Die Erreichbarkeit per Festnetztelefon ist in den letzten Jahrzehnten stark gesunken. Es wird versucht, diese sinkende Erreichbarkeit durch Anrufe an zufällig generierte Mobiltelefonnummern auszugleichen. Diese Methode weist allerdings einen sehr hohen Anteil an Teilnahmeverweigerungen auf. Zudem ist es meist nicht möglich, kosteneffizient spezifische Zielgruppen anzusteuern, da auch keine geographische Eingrenzung möglich ist.
Die Online-Erreichbarkeit hingegen hat in den letzten Jahren insbesondere bei älteren Menschen deutlich zugenommen (vgl. Abbildung 4). Es bleibt aber auch hier ein vergleichsweise hoher Anteil an Teilnahmeverweigerungen.
Abbildung 4: Entwicklung Online-Erreichbarkeit Anmerkung: Aus methodischen Gründen können die Ergebnisse ab Herbst 2012 nicht mit älteren Studien verglichen werden. Ein Vergleich mit den kommenden Jahren ist dagegen möglich. Quelle: Eigene Darstellung nach Bundesamt für Statistik
Herausforderungen der Umstellung auf Online-Interviews
Die Onlineerreichbarkeit hat auch bei vielen Behörden dazu geführt, die Umstellung von Erhebungen auf Online-Interviews oder Mixed-Modes zumindest zu prüfen. Dies ist jedoch längst nicht bei allen der Fall. Für das Beibehalten alter Erhebungsmethoden werden hauptsächlich zwei Gründe aufgeführt: Erstens sei die Erreichbarkeit mittels Online-Interviews in spezifischen Bevölkerungsgruppen noch nicht ausreichend gut. Diese Nichterreichbarkeit sinkt beispielsweise bei älteren Personengruppen seit einigen Jahren deutlich. Bei anderen Methoden wie CATI steigt zugleich die Nichterreichbarkeit gewisser Bevölkerungsgruppen. Das Argument der schwereren Erreichbarkeit mancher Bevölkerungsgruppen durch Online-Interviews schwächt sich folglich immer weiter ab und wird sich vermutlich eher ins Gegenteil kehren. Zweitens sind viele Erhebungen in der Sozialforschung Wellenerhebungen über lange Zeiträume. Bei diesen steht die Entwicklung gewisser Themen im Fokus. Wenn man nun die Erhebungsmethode ändert, ist es aufgrund der genannten Selektions- und Methodeneffekte wahrscheinlich, dass sich die Ergebnisse ändern, da alle Methoden gewisse Verzerrungen mit sich bringen. Die Erhaltung der intertemporalen Vergleichbarkeit dient daher oftmals als Grund für das Beibehalten der ursprünglichen Erhebungsmethode. Dieses Argument greift allerdings zu kurz, da sich Selektionseffekte wie oben beschrieben über die Zeit verändern. Folglich ist die intertemporale Vergleichbarkeit auch bei konstanter Erhebungsmethode nur eine scheinbare.
Die Zukunft
Langfristig werden sich Online-Interviews in der Sozialforschung weiter etablieren. Die Selektionseffekte bei Online-Interviews schwinden, während sie bei anderen Methoden grösser werden. In manchen Bereichen, wo Offliner wichtig sind, wird es zumindest eine Zeit lang noch notwendig sein, die Erhebungen als Mixed-Mode durchzuführen. Hier eignet sich allerdings die Kombination PAPI/Online-Interviews aus methodischer Sicht deutlich besser als CATI/Online-Interviews, da PAPI und Online-Interviews beide selbstadministriert und somit frei von Interviewer-Effekten sind. Doch keine Sorge, Telefone werden ihren Nutzen für die Sozialforschung nicht verlieren, können sie doch als mobiler Zugang zu Online-Befragungen und als Mobilitätstracking-Device dienen.
Referenz Voorpostel, M., Kuhn, U., Tillmann, R., Monsch, G. A., Antal, E., Ryser, V. A., … & Dasoki, N. (2020). Introducing web in a refreshment sample of the Swiss Household Panel: Main findings from a pilot study. Fors Working Series paper, 2.
Der Autor Dr. Marcus Roller ist Leiter Sozialforschung bei intervista. Er ist promovierter Ökonom und spezialisiert auf quantitative Forschungsmethoden. Er hat an den Universitäten Basel und Bern zu quantitativen Methoden gelehrt und forscht weiterhin zu ökonometrischen Fragestellungen.
Dynamic Pricing findet in vielen Branchen mehr und mehr Verbreitung. Dabei werden die Preise in Abhängigkeit verschiedener Nachfrageparameter fortlaufend angepasst. Insbesondere in der Tourismusbranche ist Dynamic Pricing mittlerweile üblich – z.B. bei Fluggesellschaften oder bei Hotels. Jedoch gibt es immer noch zahlreiche Hotels, auch in der Schweiz, die nicht auf Dynamic Pricing setzen. Gründe hierfür sind unter anderem Unsicherheiten bezüglich geeigneter Softwarelösungen, aber auch bezüglich der Kundenreaktionen.
An diesen Unsicherheiten setzte ein gemeinsames Forschungsprojekt der ZHAW School of Management and Law und der RoomPriceGenie AG an. Die RoomPriceGenie AG bietet eine Softwarelösung für Dynamic Pricing an.
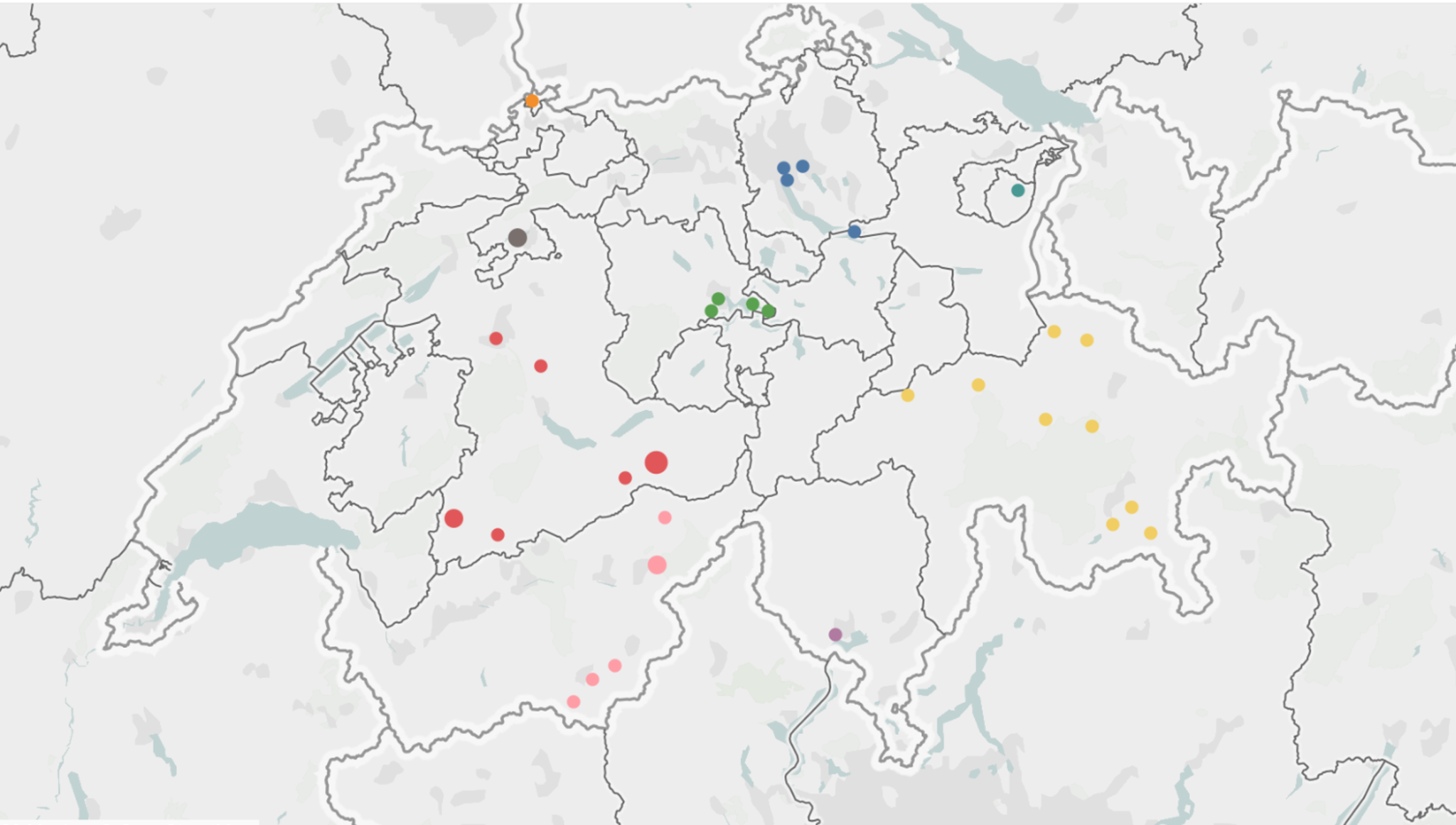
Abbildung 1: Teilnehmende Hotels
Gemeinsam wurden 37 Hotels gewonnen, an diesem Forschungsprojekt teilzunehmen und im Projektzeitraum 2021 und 2022 Dynamic Pricing einzuführen. Abbildung 1 zeigt die geografische Verteilung der teilnehmenden Hotels, wobei die Farben die Kantone kennzeichnen und die Grösse der Kreise die Anzahl der teilnehmenden Hotels je Standort symbolisiert. Es nahmen sowohl Hotels in Städten als auch Hotels in Bergregionen am Projekt teil.
Die Effekte der Einführung von dynamischem Pricing wurden aus drei Perspektiven gemessen: • Perspektive 1: Veränderung der internen Kompetenzen; • Perspektive 2: Veränderung der Gästezufriedenheit; • Perspektive 3: Veränderung der finanziellen Performance.
Perspektive 1: Veränderung der internen Kompetenzen
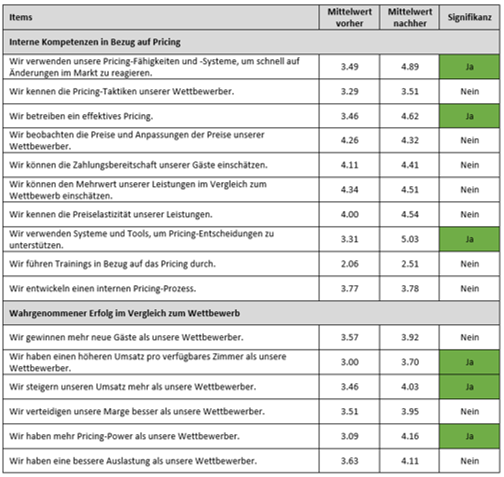
Die teilnehmenden Hotels wurden zu Beginn des Projekts gebeten, einen Fragebogen auszufüllen, in dem ihre internen Kompetenzen in Bezug auf Pricing sowie ihr wahrgenommener Erfolg im Vergleich zum Wettbewerb anhand etablierter Skalen abgefragt wurden. Nach der Einführung der Softwarelösung und mindestens sechs Monaten Erfahrung mit Dynamic Pricing wurden sie nochmals aufgefordert, ihre Beurteilung abzugeben. Anhand dieser Vorher-Nachher-Messung bei insgesamt 33 Hotels – vertreten durch jeweils eine Person aus dem Management – zeigte sich, dass sich die internen Kompetenzen in Bezug auf Pricing signifikant von 3.6 auf 4.2 (Skala 1-6) verbessert hatten. Ebenfalls erhöhte sich der wahrgenommene Erfolg im Vergleich zum Wettbewerb von 3.4 auf 4.0 (Skala 1-6). Betrachtet man die einzelnen Items, zeigt sich in Tabelle 1 insbesondere eine Verbesserung bei den folgenden Aspekten: • «Wir verwenden unsere Pricing-Fähigkeiten und -Systeme, um schnell auf Änderungen im Markt zu reagieren.» • «Wir betreiben ein effektives Pricing.» • «Wir verwenden Systeme und Tools, um Pricing-Entscheidungen zu unterstützen.» • «Wir haben einen höheren Umsatz pro verfügbares Zimmer als unsere Wettbewerber.» • «Wir steigern unseren Umsatz mehr als unsere Wettbewerber.» • «Wir haben mehr Pricing-Power als unsere Wettbewerber.»
Tabelle 1: Vorher-Nachher-Messung in Bezug auf die internen Kompetenzen
Doch wie sind die Effekte bei den Gästen? Dies steht nachfolgend im Vordergrund.
Perspektive 2: Veränderung der Gästezufriedenheit
Auch in Bezug auf die Veränderung der Gästezufriedenheit wurde eine Vorher-Nachher-Messung durchgeführt. Die Hotels wurden gebeten, eine einheitliche Gästebefragung zu versenden und mindestens 30 Antworten zu generieren – und zwar vor und nach der Einführung von Dynamic Pricing. Insgesamt 16 Hotels lieferten eine ausreichende Datengrundlage mit insgesamt jeweils mehr als 1’000 Gästeantworten vor und nach der Einführung der Softwarelösung.
Dabei zeigten sich folgende Ergebnisse, wobei eine Gewichtung stattfand, um alle 16 Hotels gleichermassen zu berücksichtigen: • Die Gesamtzufriedenheit veränderte sich nicht signifikant von 5.21 auf 5.27 (Skala 1-6). • Die wahrgenommene Preisfairness veränderte sich nicht signifikant von 5.00 auf 4.93 (Skala 1-6). • Die Weiterempfehlungsabsicht veränderte sich nicht signifikant von 8.82 auf 8.73 (Skala 1-10).
Somit hat die Einführung von Dynamic Pricing keinen Effekt auf die Gästezufriedenheit. Dies liegt unter anderem daran, dass bereits vor der Einführung von Dynamic Pricing 74.5% der befragten Personen glaubten, dass die Preise dynamisch gebildet werden. Nach der Einführung von Dynamic Pricing lag dieser Anteil bei 78.1%. Auch der Net Promoter Score (NPS) blieb nahezu konstant (60.6% vs. 58.4%). Somit zeigen sich im Hinblick auf die Veränderung der internen Kompetenzen (Perspektive 1) und im Hinblick auf die Veränderung der Gästezufriedenheit (Perspektive 2) Ergebnisse, die für die Einführung von Dynamic Pricing sprechen. Doch können die Hotels auch von einer positiven Veränderung der finanziellen Performance profitieren?
Perspektive 3: Veränderung der finanziellen Performance
Um dies zu untersuchen, wurden die folgenden branchenüblichen Kennzahlen herangezogen: • Zimmerbelegung bzw. Occupancy (in %) • Durchschnittsrate bzw. Average Daily Rate (in CHF) • Umsatz pro verfügbares Zimmer bzw. Revenue Per Available Room (in CHF)
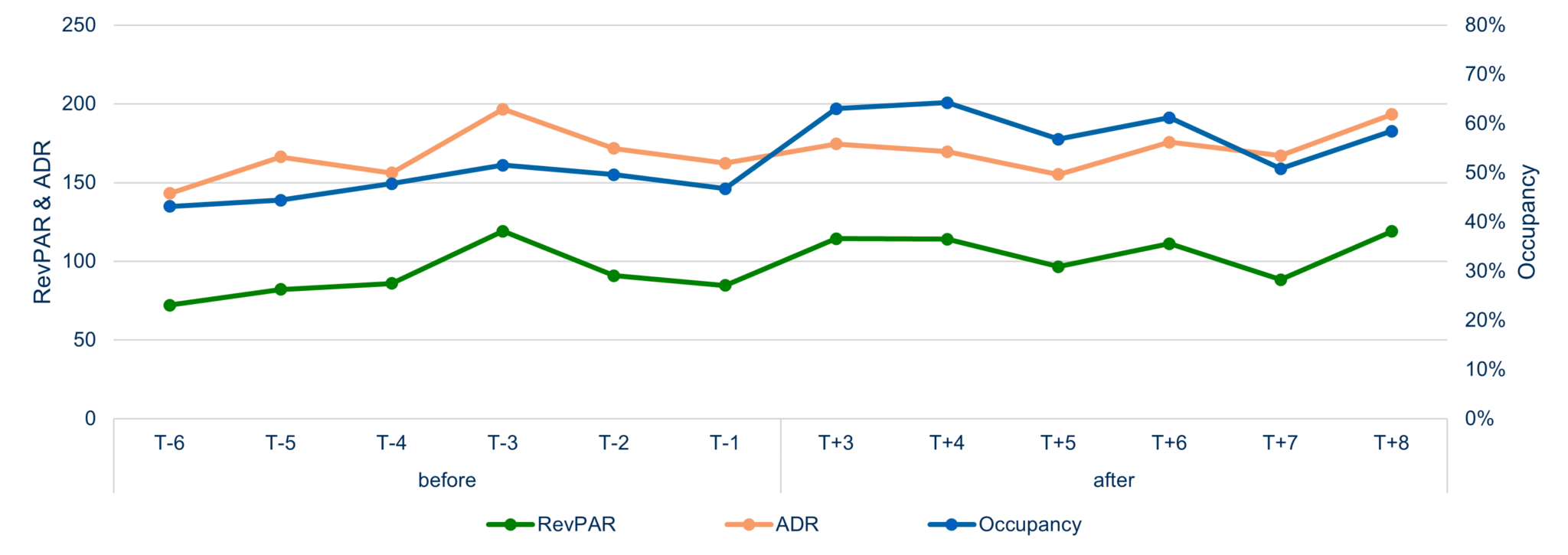
Insgesamt 21 Hotels lieferten diese Kennzahlen für einen Zeitraum von mindestens 6 Monaten vor der Einführung von Dynamic Pricing und von mindestens 8 Monaten nach der Einführung von Dynamic Pricing. Die ersten beiden Monate nach der Einführung der Softwarelösung wurden in der Analyse nicht berücksichtigt, da die Buchungen für Aufenthalte in diesem Zeitraum meist noch vorher getätigt wurden. Eine aggregierte Analyse zeigt folgende Ergebnisse: • Die Zimmerbelegung stieg von 47% auf 59%. • Die Durchschnittsrate stieg von 166 CHF auf 173 CHF. • Der Umsatz pro verfügbares Zimmer stieg von 89 CHF auf 107 CHF.
Abbildung 2: Vorher-Nachher-Messung in Bezug auf die finanzielle Performance
Abbildung 2 verdeutlicht diese Ergebnisse. Im Hinblick auf diesen Vorher-Nachher-Vergleich ist jedoch anzumerken, dass es sich um ein einfaches Design ohne Kontrollgruppe handelt, welches weitere externe Effekte nicht vollständig ausschliessen kann.
Limitationen und Implikationen
Diese Limitation sollte in zukünftigen Untersuchungen berücksichtigt werden. Eine Möglichkeit wäre, weitere Hotels für ein Forschungsprojekt zu akquirieren, die jedoch zunächst auf die Einführung von Dynamic Pricing verzichten und als Kontrollgruppe dienen. Alternativ könnten Benchmarks von vergleichbaren Hotels herangezogen werden, die in diesem Forschungsprojekt nicht verfügbar waren. Trotz dieser Einschränkung ermutigen die Ergebnisse dazu, Dynamic Pricing einzuführen. Hotels können sowohl ihre internen Kompetenzen als auch ihre finanzielle Performance verbessern, ohne dass sich die Gästezufriedenheit verändert. Dies liegt vor allem daran, dass die Gäste bereits erwarten, dass die Preise dynamisch gebildet werden.
In anderen Branchen, in denen Dynamic Pricing weniger verbreitet ist, können die Effekte anders ausfallen, da dann z.B. die wahrgenommene Preisfairness sinken kann, was sich wiederum auf weitere Einstellungs- und Verhaltensgrössen auswirken kann. Dann kann der vorgestellte Ansatz ein hilfreiches Instrument sein, um einen Piloten durchzuführen und die Effekte auf Basis der drei vorgestellten Perspektiven zu messen.
Kontakt Prof. Dr. Steffen Müller
Dozent, Fachstelle Behavioral Insights & Pricing ZHAW School of Management & Law
Prof. Dr. Steffen Müller Dozent, Fachstelle Behavioral Insights & Pricing ZHAW School of Management & Law Dr. Nina Heim Dozentin, Fachstelle Behavioral Insights & Pricing ZHAW School of Management & Law Vera Lenggenhager Wissenschaftliche Mitarbeiterin, Fachstelle Behavioral Insights & Pricing ZHAW School of Mgm & Law Dr. Ari Andricopoulos CEO, RoomPriceGenie AG
Ein falsch gewähltes Kampagnensujet, ein ungünstig formulierter Tweet oder eine strategische Änderung der Markenausrichtung – schon öffnet sich die Büchse der Pandora für einen potenziellen Imageschaden. Doch wie lange hält ein solcher Imageschaden an? Wann ist die Marke wieder auf wünschenswertem Niveau?
Oder von der erfreulichen Seite betrachtet: Die neue Kampagne ist ein wahrer Erfolg, die Kund:innen sind glücklich, neue Konsument:innen und neue Käufer:innen sind gewonnen. Wie lange kann eine Marke von einer erfolgreichen Kampagne profitieren?
Natürlich liefern Absatzzahlen oftmals Informationen über die aktuelle Performance einer Marke. Jedoch ist die reine Betrachtung von Verkaufs- und Marktanteilen meist auch mit Wissenslücken verbunden, da sie oft mit Promotionen einhergehen, welche auch kontraproduktiv für das Markenimage sein können. Daher hat LINK in Kooperation mit der Universität Luzern und dem Institut für Marketing & Analytics (IMA) im September 2021 den Swiss Brand Observer (SBO) lanciert. Insgesamt erhebt der SBO 26 relevante Grössen zur Markenwahrnehmung (z.B. KPIs zum Purchase Funnel, Image-Dimensionen, Zufriedenheit und Weiterempfehlung) und ergänzt diese mit der aktuellen Online- und Offlinewerbewahrnehmung. Somit ergibt sich ein umfassendes, kundenbezogenes Abbild der Marke – und dies wochenaktuell. Die Wahrnehmung medialer Ereignisse – sei es in Form von Kampagnen oder Medienberichten – kann praktisch live mitverfolgt werden. Einerseits wird evaluiert, ob diese wahrgenommen werden, und andererseits inwiefern diese einen möglichen Einfluss auf andere Markenattribute haben. Dies ist insbesondere für die jeweiligen Geschäftsbereiche Marketing, Strategie und Branding relevant, um die eigene Marke besser zu beobachten, zu steuern und zu entwickeln. Zudem haben Kundinnen und Kunden nicht nur Einblick in ihre eigene Marke, sondern auch in alle anderen erhobenen Marken im SBO. Dies erlaubt ihnen, ihre Analysen nicht nur in ihrem «engen» Konkurrenzfeld zu betrachten, sondern sie haben nun die Möglichkeit, sich jeweils mit dem «Best In Class» zu vergleichen.
Ein wissenschaftlich validiertes Brand Tracking
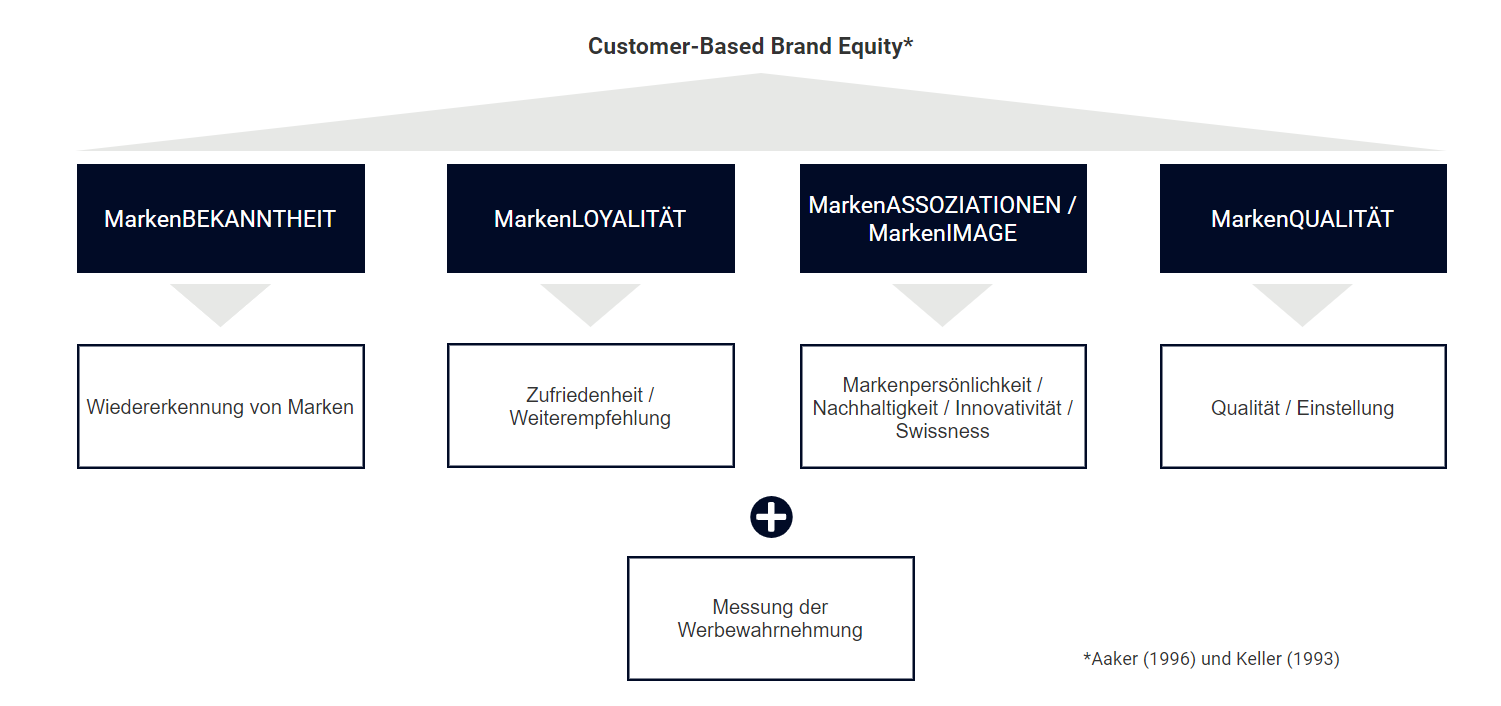
Dem SBO liegt ein in der Schweiz einzigartiges Studiendesign zu Grunde: LINK hat dieses in Kooperation mit der Universität Luzern und dem Institut für Marketing & Analytics konzipiert. Der SBO basiert auf dem seit vielen Jahren etablierten Customer-Based Brand Equity-Ansatz (CBBE), welcher von vier Dimensionen ausgeht (Aaker, 1996 | Keller, 1993):
Die Dimension Markenbekanntheit bezeichnet die Verankerung der Marke bei Konsumentinnen und Konsumenten, welche wiederum auch die Wahrnehmung und Einstellung zur Marke beeinflussen kann (Aaker, 1996). Hingegen bezeichnet die Markenloyalität das positive Denken über die Marke und ob infolgedessen die Marke wiederholt genutzt wird (Keller, 1993). Loyale Konsumentinnen und Konsumenten sind auch bereit, einen Aufpreis für diese Marke zu bezahlen (Mehrzahlungsbereitschaft). Image-Komponenten einer Marke werden wiederum in der Dimension Markenassoziationen/Markenimage erhoben. Aus diesen ziehen Konsument:innen resp. Kund:innen ihren emotionalen Nutzen (Markenpersönlichkeit) und Assoziationen werden in den Köpfen geschärft, damit die Zielgruppe die Marke von anderen Marken differenzieren kann. Dies ist unabdingbar für eine Marke, wenn sie nachhaltig erfolgreich sein will (Aaker, 1996). Abgrenzend zu den Assoziationen/zum Image bezeichnet die Markenqualität die Wahrnehmung der Qualität einer Marke bezogen auf deren produktbezogene, funktionale und erlebnishafte Eigenschaften (Keller 1993). Auch neuere Forschungsarbeiten zeigen, dass CBBE-Grössen auf Kundenakquisition, Kundenbindung oder Erhöhung der Gewinnmargen einen Einfluss haben (Stahl et al., 2012 | Slotegraaf & Pauwels, 2008). Zudem wurde der SBO in einer kürzlichen Untersuchung empirisch validiert (Naan et al., 2023).
Grafik 1: «Customer-Based Brand Equity» als Grundlage für die Konzeptualisierung des Swiss Brand Observers
Um genügend valide Datenpunkte für eine Marke zu erhalten, erhebt LINK wöchentlich in acht Segmenten insgesamt n=2’000 Interviews resp. n=250 Interviews pro Woche im qualitativ hochwertigen LINK Panel. Dies summiert sich auf über 104’000 Interviews total und über 13’000 Interviews pro Marke im Jahr. Somit ist es möglich, die Markenperformance über das ganze Jahr genau zu analysieren und schnell zu handeln, sofern (un)erwünschte Bewegungen ersichtlich werden.
Damit die eigene Marke, das Konkurrenzumfeld oder der jeweilige «Best In Class» Brand einfach und schnell analysiert werden kann, sind die Daten in einem intuitiven Dashboard – mit diversen Filtermöglichkeiten wie Alter, Geschlecht, Mediennutzung etc. – abrufbar. «So besteht erstmals die Möglichkeit, Marketingausgaben der zeitlichen Entwicklung gegenüberzustellen und die Massnahmeneffektivität in einem modernen Ansatz zu analysieren. Gleichzeitig schafft das Tool Transparenz, da das dynamische Wettbewerbsumfeld bei den meisten Marken bisher weniger miteinbezogen wurde», erklärt dazu Prof. Dr. Reto Hofstetter, Professor für digitales Marketing am IMA. Ein weiterer Vorteil des Dashboards: Historische Daten seit September 2021 sind inkludiert und neue Daten werden mit wenig Aufwand hochgeladen.
Was Credit Suisse und Toblerone (nicht) gemeinsam haben
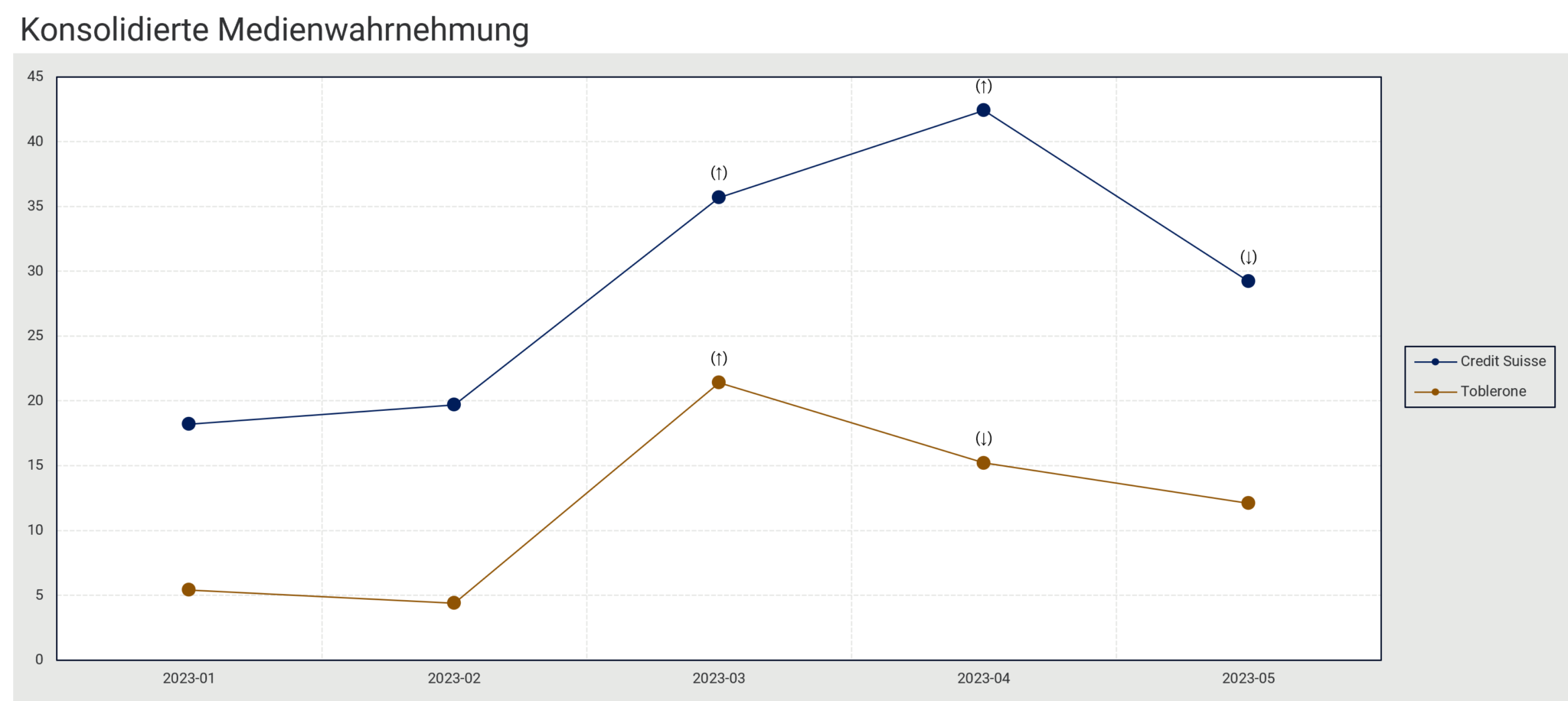
Ein konkretes Beispiel aus dem Swiss Brand Observer aus den Monaten Januar 2023 bis und mit Mitte Mai 2023 (Stichtag: 14. Mai 2023): Wir erkennen in Grafik 2 einen signifikanten Anstieg (dargestellt mit einem Pfeil nach oben) der konsolidierten Medienwahrnehmung (Konsolidierung der Online- und Offline-Werbewahrnehmung + Medienberichte) sowohl bei Credit Suisse als auch bei Toblerone im März 2023.
Grafik 2: Auszug aus dem Swiss Brand Observer (15-79 Jahre, gesamte Schweiz inkl. Tessin). Konsolidierte Medienwahrnehmung bezeichnet die Konsolidierung von Online- und Offline-Werbewahrnehmung sowie Wahrnehmung von Medienberichten.
Was ist passiert? Die effektive Übernahme der CS durch die UBS wurde im März offiziell, und auch Toblerone geriet in das Fadenkreuz der Medien, da publik wurde, dass nun sowohl das Matterhorn als auch die Aufschrift «of Switzerland» aufgrund des neuen Produktionsstandorts Slowakei schwinden müssen. Der wahrgenommene mediale Anstieg der CS erreichte im April seinen Höhepunkt und sank im Mai wieder signifikant, während bei Toblerone ein kontinuierlicher Rückgang der Werbewahrnehmung festzustellen ist.
Doch was bedeuten solche negativen Schlagzeilen für eine Marke? Bei beiden Marken lassen sich zwei komplett verschiedene Szenarien erkennen.
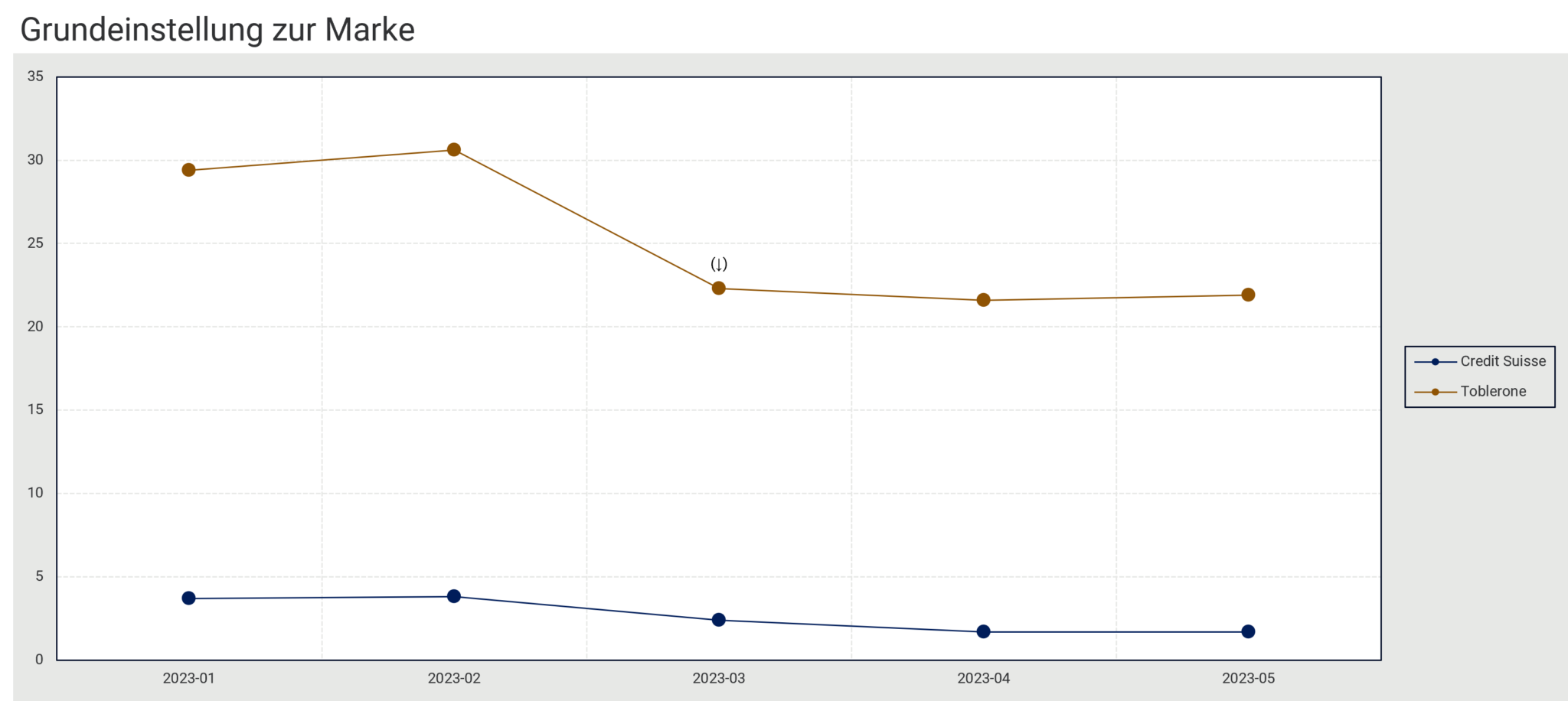
Hierfür wird das Beispiel der Markengrösse Grundeinstellung zur Marke (besonders positive Wahrnehmung) genutzt (Grafik 3). Während vor der medialen Berichterstattung ca. 30 % der Schweizer Bevölkerung Toblerone als besonders positiv wahrgenommen haben, sinkt dieser Anteil signifikant auf 22 % und bleibt bis Mitte Mai unverändert – trotz des signifikanten Rückgangs der Werbewahrnehmung. Bei der CS sehen wir zwar ebenfalls einen leichten Rückgang der Grundeinstellung zur Marke, jedoch war das Niveau bereits vor der Bekanntgabe der Übernahme durch die UBS vergleichsweise tief, sprich: Die CS performt zwar etwas schlechter als zuvor, jedoch ist das (negative) absolute Potenzial für Toblerone in dieser Dimension viel grösser. Da auch andere KPIs wie die Qualitätswahrnehmung oder Mehrzahlungsbereitschaft für beide Marken in diesem Zeitraum zurückgehen, haben beide Brands offensichtlich aktuell grössere Schwierigkeiten darin, ihre Marktposition bzw. -penetration auf dem Niveau vor März zu halten. Im Swiss Brand Observer kann des Weiteren verfolgt werden, ob diese Performance-Rückgänge langfristiger Natur sind und wie gross der Verlust an Markenattraktivität ist.
Grafik 3: Repräsentativer Auszug aus dem Swiss Brand Observer (15-79 Jahre, gesamte Schweiz inkl. Tessin). Die Grundeinstellung zur Marke bezeichnet die positive Wahrnehmung einer Marke.
Fazit
Für Marketeers, Brand Manager:innen sowie Strateg:innen ist es heute unabdingbar, schnell auf Veränderungen reagieren zu können – sowohl bei positiven als auch bei negativen Wahrnehmungen der Marke. Im Omnichannel-Zeitalter sind Marken einer bis dato nicht dagewesenen Wahrnehmungsintensität unterworfen, sei es durch Werbung, Medienberichte oder in den sozialen Medien. Je nach medialem Ereignis kann sich folglich in einem Fall beispielsweise die Grundeinstellung zur Marke ändern, während die Qualitätswahrnehmung stabil bleibt.
Der Swiss Brand Observer knüpft genau hier an: Veränderungen wahrnehmen und gleichzeitig verstehen, auf welche Veränderungen reagiert werden sollte. Ein jährliches Tracking wird diesem Anspruch oftmals nicht gerecht, und selbst ad hoc Projekte direkt nach einer negativen Berichterstattung sind ebenfalls zeitlich eingeschränkt, da das unmittelbare «Zuvor» nicht erfasst und das «Danach» lediglich während der Feldzeit evaluiert wird. Die Wissenslücke, wie lange ein Brand an einem potenziellen Imageschaden leidet oder wie lange eine Marke von einer gelungenen Kampagne profitiert, kann mittels eines kontinuierlichen Brandtrackers wie dem Swiss Brand Observer also geschlossen werden.
Literaturverzeichnis weiter unten
Laura Colledani
Head of Healthcare Research and Data Products LINK
Die Autorin Laura Colledani ist Head of Healthcare Research and Data Products bei LINK und hat sich auf Datenprodukte, Markenbeobachtung sowie Consulting und Insight-Storytelling spezialisiert. Dank ihrer umfangreichen Expertise generiert sie immer wieder neue innovative Lösungen und wertvolle Erkenntnisse für die Entwicklung von Marken.
Literaturverzeichnis Aaker, D.A. (1996). Measuring brand equity across products and markets. California Management Review, 38 (3). Keller, K.L. (1993). Conceptualizing, measuring, and managing customer-based brand equity. Journal of Marketing, 57 (1). Naan, L., Finken, D., Zogaj A., Reiser, S., & Hofstetter, R. (2023). What Do Consumers Think About Your Brand? Just Ask!. Marketing Review St. Gallen, 1/2023. Slotegraaf, R., & Pauwels, K. (2008). The impact of brand equity and innovation on the long-term effectiveness of promotions. Journal of Marketing Research, 45 (3). Stahl, F., Heitmann, M., Lehmann, D. R., & Neslin, S. A. (2012). The impact of brand equity on customer acquisition, retention, and profit margin. Journal of Marketing, 76 (4).
Das Internet in der Tasche mit sich tragen – was vor 25 Jahren eine utopische Vorstellung war, ist heute trivial. Die Einführung des Smartphones hat unser Leben verändert, nicht zuletzt auch die Markt- und Meinungsforschung.
Mit immer besseren Internetverbindungen, grösseren Bildschirmen und einer schnellebigeren Gesellschaft mit permanenter Aufmerksamkeitsknappheit[5] stieg das Bedürfnis im letzten Jahrzehnt stark an, Umfragen auch auf Mobilgeräten anbieten und ausfüllen zu können. Diese erhöhte Nachfrage mobiler oder zumindest mobilkompatibler Umfragen schafft nicht nur neue Herausforderungen für das Design und die Handhabung von Onlineumfragen, sondern muss auch hinsichtlich Datenqualität differenziert betrachtet werden.
Anhand anonymisierter Meinungsdaten einer Kundenbefragung eines grossen Schweizer Retailers, die 2014 lanciert wurde und seither täglich neue Rückläufe verzeichnet, analysieren wir die Entwicklung der mobilen Teilnahmen und deren Auswirkung auf die Datenqualität.
Datenqualität – Was ist das eigentlich?
70 Millionen Suchergebnisse bei Google demonstrieren die Relevanz des Begriffs “Data Quality” eindrücklich. Während im Alltag der Begriff “Datenqualität” häufig mit der Richtigkeit (Präzision) von Daten gleichgesetzt wird, ist Datenqualität in der Markt- und Meinungsforschung komplexer. Hier stehen am Ende der Datenverarbeitung Auftraggebende oder Forschende als Consumer der Daten. Deshalb ist es besonders wichtig, zu verstehen, dass Datenqualität aus Consumer-Sicht oft über die Präzision von Werten hinausgeht und auch Aspekte wie beispielsweise Glaubwürdigkeit, Relevanz, Vollständigkeit, Interpretierbarkeit, Konsistenz und Zugänglichkeit von Daten für Consumer berücksichtigt[18]. Relevanz zum Beispiel umfasst, dass Daten für ihren beabsichtigten Zweck tatsächlich geeignet sind, denn eine schlechte Datenqualität kann zu fehlerhaften Entscheidungen und ineffizienten Geschäftsprozessen führen, während eine hohe Datenqualität eine fundierte Entscheidungsfindung, bessere Geschäftsprozesse und letztendlich bessere Geschäftsergebnisse unterstützt.
Datenqualität, die in der Literatur mit zahlreichen verschiedenen Modellen beschrieben wird[6], kann durch geeignete Massnahmen optimiert werden. Einerseits vor der Feldphase, mittels elaboriertem Sampling, stringenter Fragebogenkonzeption und Pretesting. Andererseits in der Analyse und der technischen Bereinigung der bereits gewonnenen Daten. Hinzu kommen Meta-Aspekte der Datenqualität wie Passung der Daten zur Forschungsfrage, Prozesstransparenz, faire Datengewinnung oder proaktiver Datenschutz, die Empowerment für Kundinnen und Kunden bewirken[10].
Fallstudie: Kundenbefragung eines grossen Schweizer Retailers
Unsere Analyse erhebt erstmals a) eine durchmischte, reale Zielgruppe (Kundinnen und Kunden eines Retailers) mit b) grosser Datenmenge c) für die Schweiz und hebt sich damit deutlich von bisherigen Studien ab. Sie orientiert sich methodologisch am Vorgehen von Schlosser und Mays[13], die 2018 den Einfluss von mobilen Teilnahmen auf die Datenqualität an einer Gruppe von 820 deutschen Studierenden untersuchten.
Unsere Analyse greift auf vollständig anonymisierte Daten der Kundenbefragung eines Schweizer Retailers zurück, die 2014 in einem Unternehmensbereich lanciert und anschliessend sukzessiv auf weitere Unternehmensbereiche ausgeweitet wurde. Stand Mai 2023 lagen 345’000 Umfragerückläufe mehrsprachig (de, fr, it) schweizweit vor. Der Fragebogen enthält 6 Fragen. Darunter befinden sich eine Frage zur Weiterempfehlungsbereitschaft, eine Tabelle mit 5 Items und elfstufiger Likert-Skala, eine Frage mit offener Textantwort und zwei Ja-Nein-Fragen. Für die Beantwortung stehen die im Internet verbreiteten Radiobuttons und Textfelder zur Verfügung. Die mittlere Bearbeitungszeit beläuft sich auf rund 2 Minuten. Es werden keine soziodemografischen Daten erhoben. Als Befragungssoftware wird die Umfrageplattform von onlineumfragen.com genutzt. Die Kundinnen und Kunden werden in einem mixed-mode Verfahren via E-Mail (ca. 95%) und SMS eingeladen (ca. 5%).
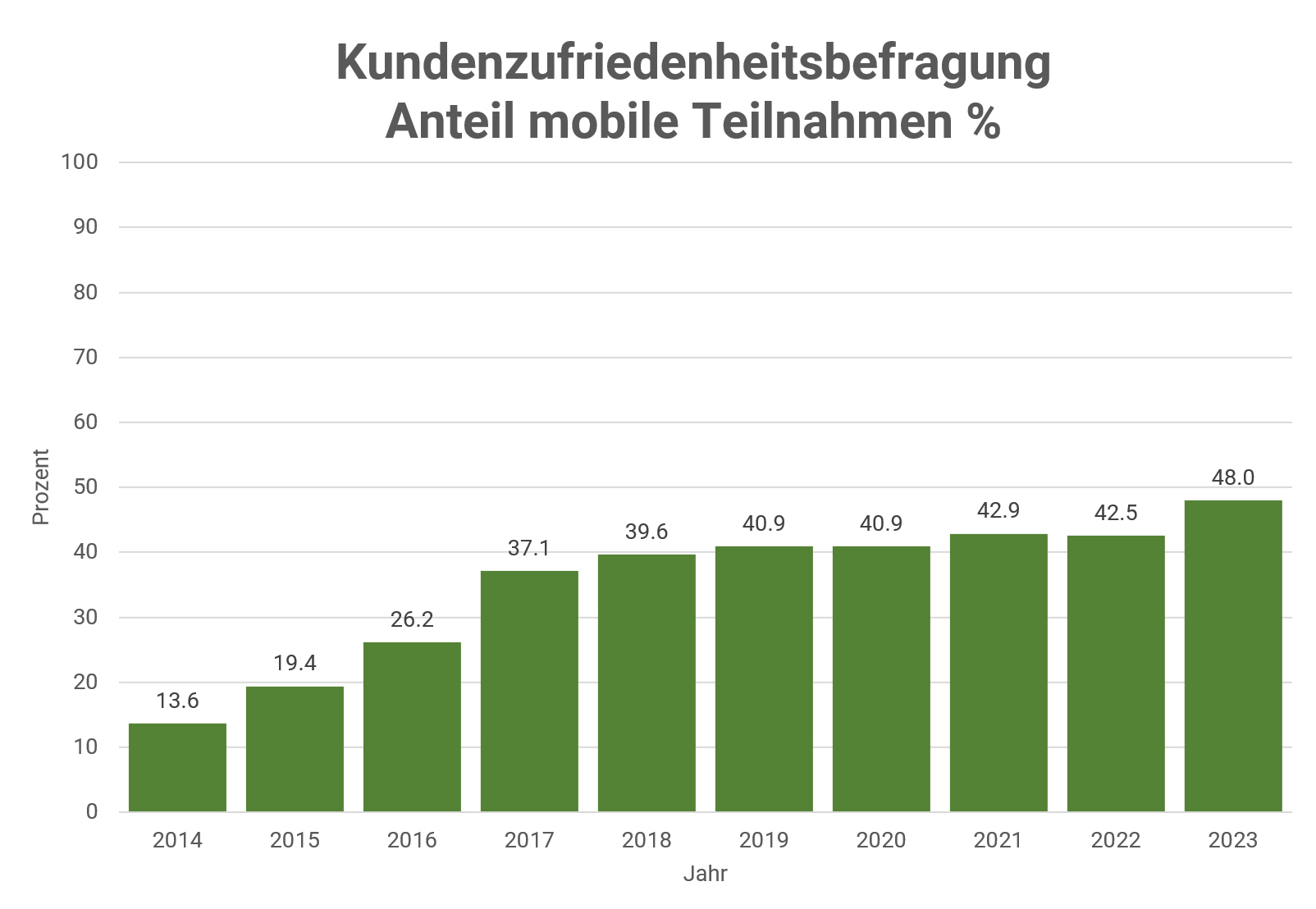
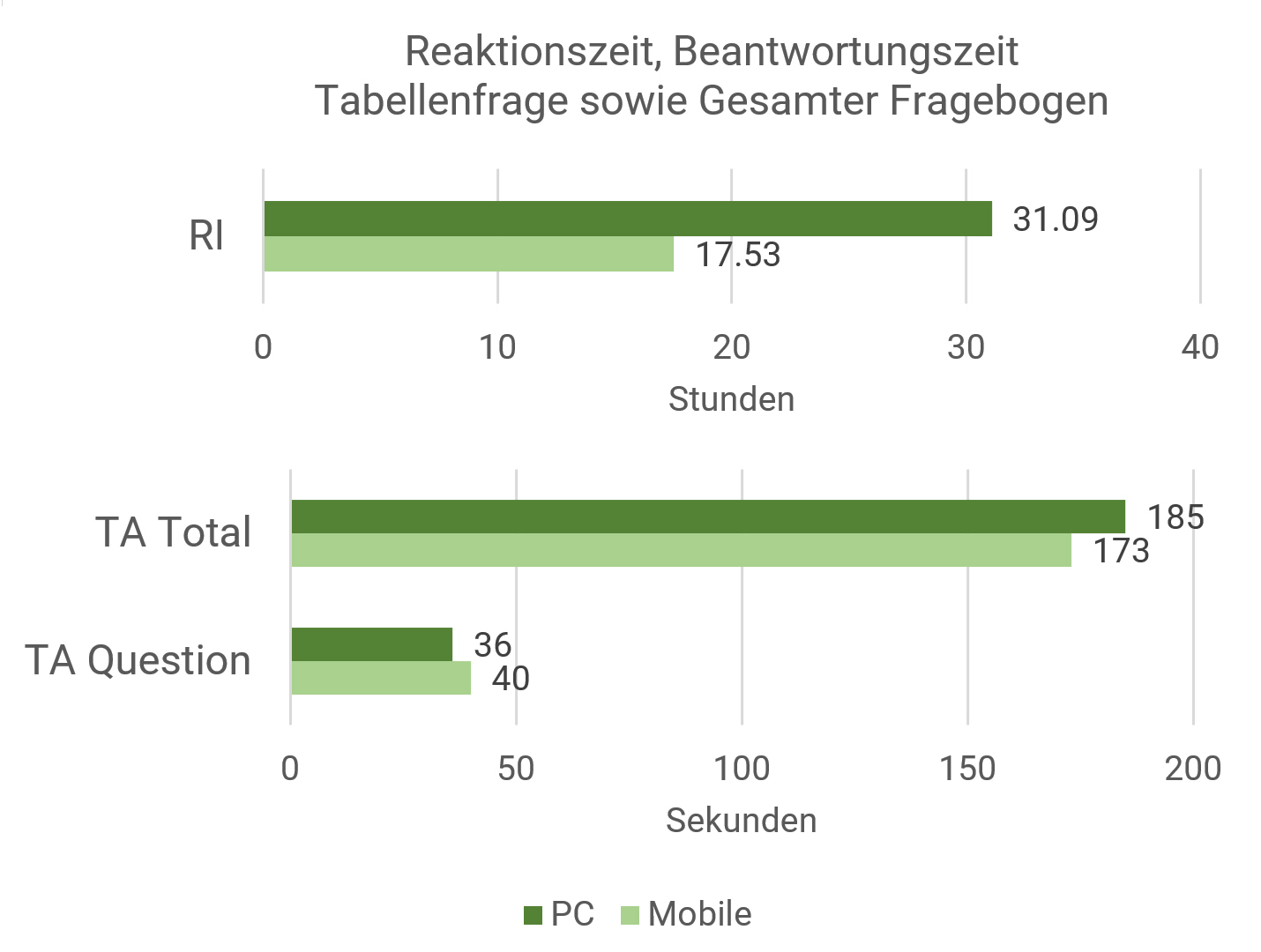
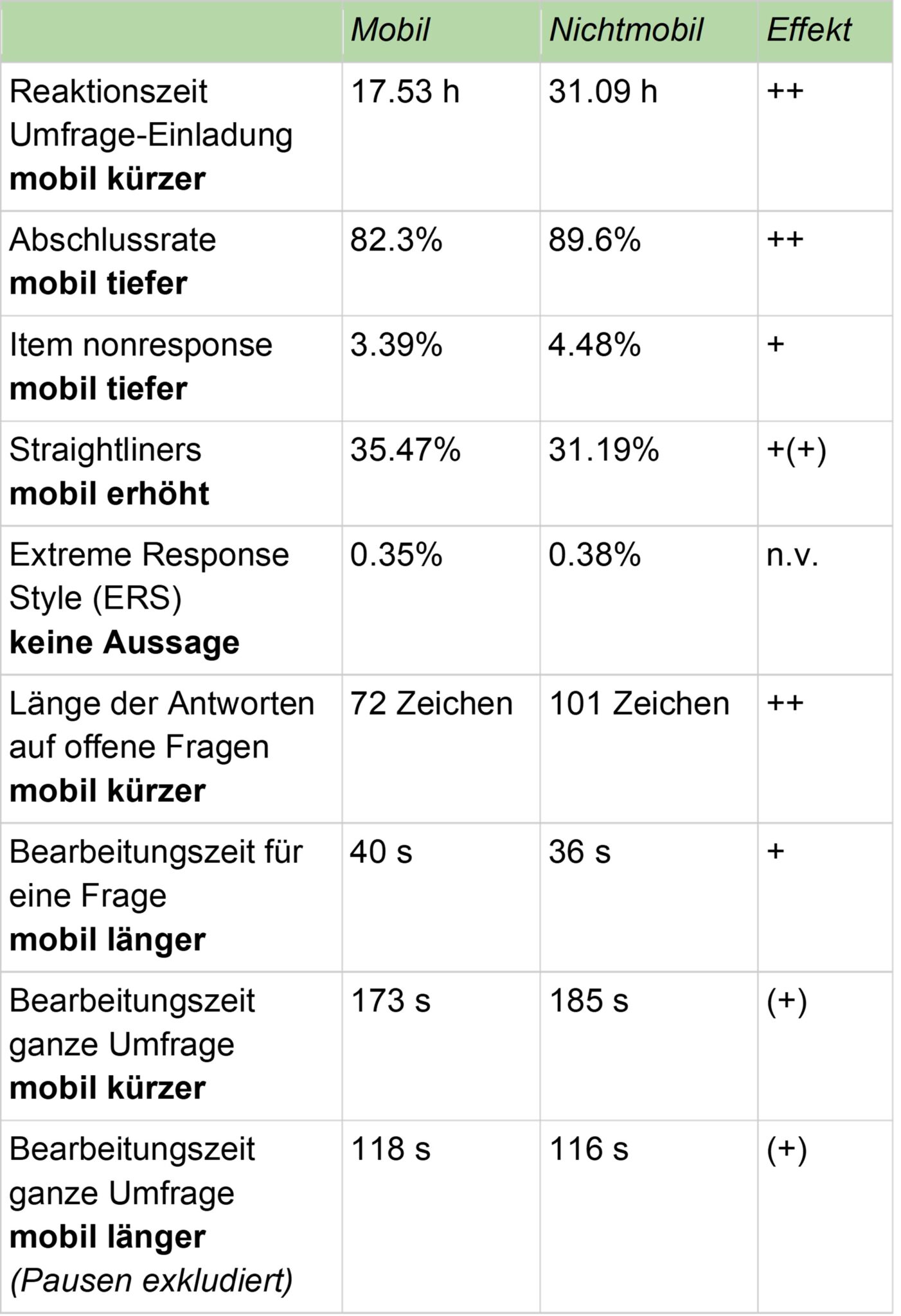
Entwicklung der Relevanz mobiler Teilnahmen 2014 bis 2023
In unserem Sample stieg der Anteil der mobi-len Teilnahmen, gemessen über Browser Agent Strings und Bildschirmgrösse, seit 2014 stetig. Mobile Teilnahmen haben sich in der Zeit von 2014 bis 2023 mehr als verdreifacht.
Eine Abschwächung der Entwicklung in den letzten fünf bis sechs Jahren könnte mit einer Sättigung der Zielgruppe zu tun haben: Wer potenziell mobil teilnehmen möchte, verfügt nun auch über die Möglichkeit.
Bild 1: Anteil mobile Teilnahmen Kundenzufriedenheitsbefragung im Retail-Sektor, 2014 bis 2023
Auswirkungen des mobilen Modus auf die Datenqualität
Um Datenqualität in konkreten Aspekten zu messen, wurde ein Subsample aus insgesamt 46’581 aktuellen Teilnahmen herangezogen. Die Eingrenzung erfolgte nach Datum jünger als 01.01.2022. Folgende Kriterien der Datenqualität wurden untersucht:
Reaktionszeit zur Umfrage-Einladung
Bearbeitungszeit für eine Frage
Bearbeitungszeit ganze Umfrage
Abschlussrate
Item nonresponse
Straightliner
Extrem Response Style (ERS)
Länge der Antworten auf offene Fragen
Benötigen mobile Teilnehmende mehr Zeit?
Zunächst wurde die Reaktionszeit zur Umfrage-Einladung ermittelt. Sie wurde über die Differenz des Zeitstempels der Einladung zur Umfrage (Versandzeitpunkt Einladungs-E-Mail) zum Zeitstempel des Aufrufs der Umfrage (Klick auf Umfragelink) berechnet und auf Ausreisser bereinigt, indem nur Teilnahmen, die innert 7 Tagen ab Einladung erfolgten, berücksichtigt wurden.
Da die Teilnehmenden auf Mobilgeräten daran gewöhnt sind, ihr Mobiltelefon ständig bei sich zu tragen und erreichbar zu sein, gehen wir davon aus, dass diese Befragten schneller reagieren als Befragte, die die Einladung über ihren PC erhalten (Hypothese 1).
Auf Mobilgeräten betrug die mittlere Reaktionszeit 13 Stunden (M=13.15; SD=25.43; nmob=23’685), auf Nichtmobilgeräten 22.75 Stunden (M=22.75; SD=34.26; npc=20’481), die Abweichung ist gemäss Welch-Test t(37137)=32.86 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.32 entspricht einem mittleren Effekt.
Wurden zusätzlich Teilnahmen zwischen 7 und 14 Tagen nach Einladung berücksichtigt, ergab sich mobil eine mittlere Reaktionszeit von 17.5 Stunden (M=17.53; SD=40.11; nmob=24’169), auf Nichtmobilgeräten 31 Stunden (M=31.09; SD=53.81; npc=21‘335), die Abweichung ist gemäss Welch-Test t(38947)=30.08 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.29 zeigt einen knapp mittleren Effekt.
Die Teilnahmen durch Personen, die Mobilgeräte für die Umfrage nutzen, erfolgen also im Mittel rund 9.6 (resp. 13.6) Stunden früher und damit deutlich näher am Zeitpunkt der Einladung (Hypothese 1 bestätigt). Dies könnte je nach Umfrage einen Einfluss auf Themen wie Erinnerungsleistung, Teilnahmemotivation oder die Emotionalität der Rückmeldungen haben.
Die mittlere Beantwortungszeit für eine Frage wurde als Differenz zwischen dem Zeitpunkt der abgeschlossenen Anzeige im Browser und dem Klicken auf den Button “Speichern – nächste Frage” bei einer Tabellenfrage bestehend aus 5 Items mit elfstufiger Likert-Skala zur Zufriedenheit bestimmter Aspekte des Einkaufserlebnisses gemessen. Die Frage wurde mobil und nicht mobil methodologisch identisch präsentiert und nur im Seitenverhältnis der Tabelle, der Breite und der Schriftgrösse im Sinne einer responsiven Darstellung mobil optimiert. Für die mobilen Teilnahmen rechnen wir mit einer erhöhten Beantwortungszeit für komplexere Tabellenfragen[4], da diese mobil schwieriger zu erfassen sind, die mobile Befragungssituation oft konzentriertes Beantworten erschwert, Fragen etwas weniger leicht zu lesen sind und die technische Erfassung der Antworten (Touchscreen) etwas anspruchsvoller und fehleranfälliger ist (Hypothese 2).
Das arithmetische Mittel der Bearbeitungszeit wurde auf Ausreisser bereinigt (Zeit > 10 Sekunden und < 180 Sekunden) und liegt bei den mobilen Teilnahmen bei 40 Sekunden (M=40.09; SD=23.01; nmob=20’333), bei den nicht mobilen Geräten bei 36 Sekunden (M=35.70; SD=20.53; npc=19’402).
Die Abweichung ist gemäss Welch-Test t(39555)=20.09 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.2 zeigt einen kleinen, aber vorhandenen Effekt. Die Bearbeitungszeit ist auf Nichtmobilgeräten etwas geringer (Hypothese 2 bestätigt).
Die Bearbeitungszeit für die ganze Umfrage wurde aus der Differenz der Anzeige der ersten Frage am Bildschirm und des Klickens auf den Button “Speichern” bei der letzten Frage berechnet.
Weil das Ausfüllen einer Umfrage über Mobilgeräte mühsamer und störanfälliger sein kann und auch die mobile Befragungssituation in der Regel mehr Ablenkungen ausgesetzt ist, könnte die Gesamtbearbeitungszeit mobil höher ausfallen. Andererseits könnte durch genau diese situativen Faktoren die Motivation, die Umfrage elaboriert “in Ruhe” und genau auszufüllen, abgeschwächt sein, und es findet vermehrt eine schnellere, oberflächlichere kognitive Verarbeitung statt, speziell bei Fragen, die sich nicht mit dem individuellen inhaltlichen Feedback-Kern decken und eher als Ballast empfunden werden. Daher vermuten wir in Abwägung dieser Überlegung für die mobilen Teilnahmen eine etwas kürzere Gesamtbearbeitungszeit (Hypothese 3).
Das arithmetische Mittel der Gesamtbearbeitungszeit wurde auf Ausreisser bereinigt (Zeit > 10 Sekunden und < 300 Sekunden) und liegt bei den mobilen Teilnahmen bei 118 Sekunden (M=118.17; SD=63.68; nmob=17’435), bei den nicht mobilen Geräten bei 116 Sekunden (M=115.73; SD=65.40; npc=16’915).
Die Abweichung ist gemäss Welch-Test t(34237)=3.50 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.038 zeigt einen sehr kleinen Effekt. Die Bearbeitungszeit ist auf Mobilgeräten somit minimal länger.
Ein spannendes Bild zeigt sich bei einer weniger starken Bereinigung von Ausreissern (Zeit > 10 Sekunden und < 3600 Sekunden). Dann liegt die Gesamtbearbeitungszeit bei den mobilen Teilnahmen bei 173 Sekunden (M=172.50; SD=237.03; nmob=19’619), bei den nicht mobilen Geräten bei 185 Sekunden (M=184.69; SD=256.90; npc=19’518). Diese Abweichung ist gemäss Welch-Test t(38851)=4.88 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.05 zeigt einen kleinen Effekt, aber nun dauern die PC-Teilnahmen länger. Dies könnte damit zusammenhängen, dass es auf PCs eine höhere Anzahl an Teilnehmenden gibt, die die Umfrage unterbrechen und nach einer Pause (z.B. Mittagspause, Telefongespräch, etc.) fortsetzen. Damit ergeben sich schnell sehr lange (aber nicht andauernd von Aktivität geprägte) Bearbeitungszeiten. Unter Ausschluss von Gesamtbearbeitungszeiten über 5 Minuten sind mobile Teilnahmen also geringfügig langsamer und weisen weniger Pausen auf (Hypothese 3 teilweise abgelehnt). Weshalb bei Einschluss von Gesamtbearbeitungszeiten bis zu einer Stunde die PC-Teilnahmen länger dauern, müsste weiter untersucht werden und könnte auch mit einem höheren Anteil an älteren und weniger IT-affinen Personen in der PC-Gruppe zusammenhängen, sowie auch damit, dass am PC generell etwas längere Texte bei Textantworten erfasst werden – jedoch werden diese oft auch schneller getippt (siehe Hypothese 8).
Weiter wurde die Abschlussrate berechnet. Sie bezeichnet die Anzahl der Teilnehmenden, die den Fragebogen bis zum Schluss ausgefüllt haben (letzte Frage wurde beantwortet).
Da das Ausfüllen der Umfrage über mobile Geräte weniger bequem sein kann, in “mobilen Situationen” oftmals vermehrt Ablenkungen auftreten und eine Umfrage auch nebenbei beantwortet werden könnte[1][3][8], sollte die Abbruchquote in der Mobil-Gruppe höher sein als in der PC-Gruppe (Hypothese 4).
Auf Mobilgeräten betrug mit einer Stichprobengrösse von nmob=24’613 die Complete-Rate 82.3% (ncomp_mob=20’259), sowie mit npc=21’968 auf Nichtmobilgeräten 89.6% (ncomp_pc=19’679). Die Abweichung hat ein Odds Ratio[16] von 0.5412 mit p<0,001 (entspricht Cohen’s d von rund 0.33 als mittlerer Effekt[2]), der Unterschied ist gemäss Fisher‘s Exact Test signifikant mit p<0,001. Die Abschlussrate ist also auf Mobilgeräten rund 7,3 Prozentpunkte tiefer. Umgekehrt betrachtet wurde eine Abbruchquote (Break-Off Rate) von mobil 17.7% gegenüber nicht mobil 10.4% beobachtet. Dies entspricht einer doch deutlichen Erhöhung um zwei Drittel (Hypothese 4 bestätigt).
Bild 3: Abbruchrate Mobil vs. PC
Antworten mobile Teilnehmende weniger aufmerksam?
Der Begriff Item Non-Response beschreibt das Nichtbeantworten von Fragen, oder – bei Pflichtfragen, die bei Auslassen nochmals gestellt werden wie in unserem Fragebogen – die Auswahl einer Ausweichkategorie wie zum Beispiel “weiss nicht” oder “keine Antwort” bei Single- und Multiple-Choice-Fragen oder Tabellen mit Likert-Skalen. Untersucht haben wir dazu die im Fragebogen enthaltene Tabellenfrage mit 5 Items/Zeilen, die eine elfstufige Likert-Skala von höchst zufrieden bis höchst unzufrieden sowie die Ausweichkategorie “nicht beurteilbar” anbietet. Unsere Berechnung zeigt, wie oft die Ausweichkategorie ausgewählt wurde.
Aus denselben Gründen wie bei Hypothese 4 vermuten wir, dass die Häufigkeit von Item Non-Response mobil höher ist als am PC (Hypothese 5). Limitierend für diese Studie ist anzumerken, dass Pflichtfragen eingesetzt wurden und daher das Kriterium “Item Non-Response” keine eigentlichen Nicht-Antworten erfasst, sondern lediglich die Nutzung der Ausweichkategorie, und diese zudem mit “nicht beurteilbar” statt typischerweise “weiss nicht/keine Antwort” beschriftet ist.
Auf Mobilgeräten betrug mit einer Gesamtantwortanzahl von nmob=107’131 der Anteil an “nicht beurteilbar”-Antworten 3.39% (nw_mob=3’626), auf Nichtmobilgeräten mit npc=101’225 Antworten 4.48% (nw_pc=4’535).
Diese Abweichung hat ein Odds Ratio[16] von 1.3385 mit p<0,001 (entspricht Cohen’s d von 0.16 als schwacher Effekt[2]), der Unterschied ist gemäss Fisher‘s Exact Test signifikant mit p<0,001. Der Prozentsatz an “nicht beurteilbar”-Antworten ist entgegen unserer Vermutung auf Mobilgeräten damit um rund einen Viertel tiefer (absolut 1.09%). Die Hypothese 5 wird damit vorläufig abgelehnt.
Dies könnte auf eine höhere Datenqualität hinweisen, könnte aber auch daran liegen, dass die Ausweichkategorie mobil auf Grund des kleinen Bildschirms der Position ganz rechts als marginal wahrgenommen wird, oder dass Teilnehmende auf Mobilgeräten zu bequem sind, die vorhandene Ausweichkategorie überhaupt erst auszuwählen, und daher sogenannte Trash-Antworten hinterlegen und die Ausweichkategorie schlichtweg nicht akkurat benutzen. Zum Beispiel, indem eine Spalte mit immer gleichen Antworten ausgewählt wird (“herunterkreuzeln” ohne nachzudenken).
Um diese Art der Verschmutzung genauer zu untersuchen, wurden nachfolgend auch einige Typen von Straightlining untersucht. Es handelt sich dabei um ein Null-Varianz-Antwortverhalten, bei dem ein immer gleicher Skalenpunkt unabhängig von der Skalenbreite, -ausrichtung und Frageformulierung für alle Zeilen einer Skalentabelle gewählt wird, was häufig bei unmotivierten Teilnehmenden auftritt[7]. Straightlining kann unter gewissen Umständen dennoch valide sein, zum Beispiel wenn eine Item-Batterie eine hohe interne Konsistenz aufweist und alle Items in dieselbe Richtung formuliert sind[12]. Bei unserem Vergleich zwischen mobilen und nicht mobilen Teilnahmen ist dies besonders spannend, da in beiden Gruppen die Zahl der validen Straightliner konstant sein müsste (da sich die eigentliche Meinung, auch wenn sie über die 5 Items hinweg einheitlich ist, von mobil und nicht mobil teilnehmenden Personen bei so grossen Stichproben nicht unterscheiden dürfte) und lediglich die Zahl der auf Grund der Geräteverschiedenheit unterschiedlich agierenden Teilnehmenden, also die nicht validen Straightliner, variieren dürfte. Dieses sozusagen geräteinduzierte Straightlining stellt eine Datenverschmutzung dar.
Wir vermuten, dass mobile Teilnehmende häufiger Straightlining aufweisen als Teilnehmende am PC (Hypothese 6).
Auf Mobilgeräten (Stichprobengrösse von nmob=21’500) betrug der Anteil an Teilnehmenden mit Straightlining 35.47% (nst_mob=7627), auf Nichtmobilgeräten (Stichprobengrösse mit npc=20’252) 31.19% (nst_pc=6316), diese Abweichung hat ein Odds Ratio[16] von 1.2131 mit p<0,001 (entspricht Cohen’s d von rund 0.10 als schwacher Effekt[2]), der Unterschied ist gemäss Fisher‘s Exact Test mit p<0,001 signifikant. Straightlining ist damit bei Mobilgeräten etwas häufiger problematisch, insbesondere, wenn man davon ausgeht, dass valides Straightlining (bewusstes, elaboriertes Entscheiden für immer dieselbe Skalenausprägung in allen Zeilen der Tabellenfragen) bei beiden Vergleichsgruppen theoretisch gleich häufig sein müsste. Eine allfällig doch vorhandene Differenz müsste demnach ausschliesslich den Anteil “verschmutzter Daten” auf Grund von demotivational bedingtem Straightlining widerspiegeln. Damit dürfte der tatsächliche Effekt grösser sein als der gemessene Effekt. Beispielsweise würden nach Abzug von angenommen 30% validen Straightliner für die nicht validen Straightliner mobil 5.47% und nicht mobil 1.19% “übrig bleiben”, also schon fast 5 mal mehr (Hypothese 6 bestätigt).
Der Begriff Extreme Response Style (ERS) bezeichnet ein spezifisches Antwortverhalten, bei dem in Tabellenfragen mit Likert-Skalen die Extrempunkte übermässig oder ausschliesslich genutzt werden. Wir klassifizieren für diese Studie Teilnehmende, die ausschliesslich Skalenendpunkte genutzt haben und mindestens eine Zeile mit einer diametral anders gepolten Antwort ausgewählt haben (z.b. 4 mal “höchst zufrieden” und 1 mal “höchst unzufrieden”, 3 mal “höchst zufrieden” und 2 mal “höchst unzufrieden”, 2 mal “höchst zufrieden” und 3 mal “höchst unzufrieden” etc.).
Wir vermuten, dass ESR auf Grund der Seltenheit des Phänomens bei mobilen Teilnahmen nicht signifikant häufiger auftritt als am PC (Hypothese 7).
Auf Mobilgeräten (Stichprobengrösse von nmob=21’500) betrug der Anteil an Teilnehmenden mit ESR 0.35% (nesr_mob=75), auf Nichtmobilgeräten (Stichprobengrösse mit npc=20’252) 0.38% (nesr_pc=77), diese Abweichung hat ein Odds Ratio[16] von 1.3993 mit p=0,62, der Unterschied ist gemäss Fisher‘s Exact Test nicht signifikant. Es gibt damit keinen signifikanten (allenfalls nur zufälligen) Unterschied in der Häufigkeit von Extreme Response Style (ESR) zwischen Mobil- und Nichtmobilgeräten (Hypothese 7 bestätigt).
Sind mobile Textantworten kürzer?
Die Länge der Textantworten auf offene Fragen kann ebenfalls ein Qualitätskriterium sein, weil durch kürzere Antworten oft weniger substanzielle oder ungenauere Aussagen für Auftraggebende herausgearbeitet werden können.
Bei mobilen Teilnahmen gehen wir aufgrund der umständlicheren Eingabetechnologie, der eingeschränkten Platzverhältnisse und der mobilen Befragungssituation, die weniger elaborierte und zeitlich limitierte Reflexion begünstigen, von deutlich kürzeren Eingaben aus (Hypothese 8). Dies wurde bereits von Mavletova[9] sowie Toepoel and Lugtig[17] berichtet.
Das ausreisserbereinigte arithmetische Mittel der Textlängen grösser als 0 und kleiner als 500 Zeichen auf die Frage “Was (…) hat Sie am meisten gefreut (…) oder verärgert?” liegt bei den mobilen Teilnahmen bei 71.57 Zeichen (M=71.57; SD=78.20; nmob=16’156), bei den nicht mobilen Geräten bei 100.95 Zeichen (M=100.95; SD=97.34; nmob=15’427).
Die Abweichung ist gemäss Welch-Test t(29572)=29.48 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.33 zeigt einen mittleren Effekt. Die Teilnehmenden, die nicht mobil geantwortet haben, hinterlegten also deutlich längere Texte (Hypothese 8 bestätigt).
Bild 4: Arithmetisches Mittel (ausreisserbereinigt) Länge Textantworten Mobil vs. PC
Tabelle 1: Zusammenfassung der Ergebnisse und Effektstärke
Fazit und Empfehlungen für die Praxis?
Datenqualität in Onlineumfragen wurde im Vergleich zwischen mobilen und nicht mobilen Teilnahmen bisher wenig untersucht, wobei Ergebnisse vorangehender Studien mit einem erstmals sehr grossen Sample aus einer aktuellen Schweizer Kundenbefragung in einer realen für die Marktforschung relevanten Zielgruppe im Retail-Sektor weitgehend bestätigt werden.
Mobile Teilnahmen zeichnen sich in der vorliegenden Untersuchung im Unterschied zu nicht mobilen Teilnahmen aus durch…
eine erhöhte Abbruchrate (=tiefere Abschlussrate),
eine höhere Datenverschmutzung durch nicht valides Straightlining,
deutlich kürzere offene Textantworten mit möglicherweise weniger substanziellen oder detaillierten Aussagen,
eine schnellere Reaktionszeit auf Umfrageeinladungen,
etwas weniger häufige Auswahl der Ausweichkategorie “nicht beurteilbar” in Likert-Skalen (was in Bezug auf Datenqualität unklar ist, da Teilnehmende unter Umständen mobil vorziehen, Trash-Antworten zu hinterlegen, anstatt akkurat die Ausweichkategorie zu benutzen, oder diese technisch auf Mobilgeräten zu wenig salient platziert ist),
uneindeutige Ergebnisse zur Antwortdauer auf einzelne Fragen und des gesamten Fragebogens, wobei auf nicht mobilen Geräten mehr Pausen gemacht werden.
Grössere Unterschiede zwischen mobilen und nicht mobilen Teilnahmen bezüglich Datenqualität sind mit zunehmender Verbreitung technisch hochstehender Smartphones und Tablets und responsiven Fragebögen grundsätzlich nicht zu erwarten, da die noch vor wenigen Jahren beschriebenen Eingabehürden (schlechte Prozessorgeschwindigkeit, sehr kleine Screens, Usability, mangelhafte Netze[11]) weitgehend aus dem Weg geräumt wurden.
Eine zentrale Ausnahme ist die zu erwartende geringere Textmenge und die damit möglicherweise weniger elaborierten und ausführlichen Angaben bei Fragen mit offenen Textfeldern, die gerade bei Fragebögen mit einer gewissen qualitativen Orientierung die Datenqualität ganz wesentlich beeinträchtigen können.
Eine in mobilen Teilnahmen erhöhte Zahl an Straightliner – wie in dieser Studie gezeigt – kann durch ausgeklügelte Methoden[7][10] auch nachträglich in Survey Daten bereinigt werden.
Zusammenfassend empfehlen wir, obenstehende Implikationen für zukünftige geplante Umfragen regelmässig zu reflektieren sowie potenzielle Vor- und Nachteile transparent zu kommunizieren. Darüber hinaus empfehlen wir für alle Onlineumfragen intensives Pretesting in gemischten Zielgruppen (mobil und nicht mobil), eine entsprechende und gezielte Analyse der Pretest-Daten vor Feldstart auf für das Projekt wesentliche und in diesem Artikel beschriebene Parameter hin sowie das vorsorgliche Einbinden fachlicher Beratung durch Experten, gerade bei sensitiven Projekten.
Die Autoren Raffael Meier, MA, MSc – Mitgründer/CTO von onlineumfragen.com und Pionier der deutschsprachigen Onlineumfragetechnologie. Er befasst sich mit gesellschaftlichen und methodologischen Aspekten von Daten und berät Kundinnen und Kunden mit dem Ziel «Empowerment»
Nina Gwerder, MA – Lead Consultant bei onlineumfragen.com und spezialisiert auf die Beratung namhafter nationaler und internationaler Unternehmen rund um das Thema Onlineumfragen und deren effektive Auswertung
Literaturverzeichnis [1] Bosnjak, M., Poggio, T., Becker, K.R., Funke, F., Wachenfeld, A., & Fischer, B. (2013). Online survey participation via mobile devices. Conference Paper, The American Association for Public Opinion Research (AAPOR) 68th Annual Conference, 2013, Boston, MA. [2] Borenstein, M., Hedges, L.V., Higgins, J.P.T., & Rothstein, H.R. (2009). Converting Among Effect Sizes. In Introduction to Meta-Analysis (eds M. Borenstein, L.V. Hedges, J.P.T. Higgins and H.R. Rothstein). [3] de Brujine, M., & Wijbant, A. (2013) Comparing survey results obtained via mobile devices and computers: An experiment with a mobile web survey on a heterogeneous group of mobile devices versus a computer-assisted web survey. Social Science Computer Review, 31, S.482-504. [4] Couper, M. P., & Peterson, G. (2016). Why do web surveys take longer on smartphones? Social Science Computer Review. First published on February 11, 2016. doi:10.1177/0894439316629932 [5] Franck, G. (1998). Ökonomie der Aufmerksamkeit. Ein Entwurf. Dtv, München 2007, ISBN 978-3-423-34401-2. [6] Haug, A. (2021). Understanding the differences across data quality classifications: a literature review and guidelines for future research. Industrial Management and Data Systems, 121(12), 2651–2671. https://doi.org/10.1108/IMDS-12-2020-0756 [7] Jandura, O. (2018). Fake Data? Zur Trennung von sauberen und verschmutzten Daten bei selbstadministrierten Befragungsmodi. In Rössler P. & Rossman, C. (Hrsg.), Kumulierte Evidenzen. Wiesbaden: Springer VS, S. 207-223. [8] Mavletova, A. (2013). Data Quality in PC and mobile web surveys. Social Science Computer Review, 31, S.725-743. [9] Mavletova, A., & Couper, M. P. (2015). A meta-analysis of breakoff rates in mobile web sur-veys. In D. Toninelli, R. Pinter, & P. de Pedraza (Eds.), Mobile research methods: Opportunities and challenges of mobile research methodologies (pp. 81–98). London, England: Ubiquity Press. [10] Meier, R., & Gwerder, N. (2022). Dirty Data in Online Surveys. Wie Datenqualität vor und nach der Feldphase verbessert werden kann. In Swiss Data Insights Association (Hrsg.), Swiss Insights Report 2022. Swiss Insights. https://swiss-insights.ch/wp-content/uploads/2023/01/Annual-Report-2022-klein.pdf [11] Peytchev, A., & Hill, C.A. (2010). Experiments in mobile web survey design. Similarities to other modes and unique considerations. Social Science Computer Review, 28, S.319-355. [12] Reunig, K., & Plutzer E. (2020). Valid vs. Invalid Straightlining: The Complex Relationship Between Straightlining and Data Quality. Survey Research Methods, 14(5), S.439-459 [13] Schlosser, S., & Mays, A. (2018). Mobile and Dirty: Does Using Mobile Devices Affect the Data Quality and the Response Process of Online Surveys?, Social Science Computer Review, 36(2), S.212-230. DOI: 10.1177/0894439317698437 [14] Schwarz, N. (2007). Cognitive aspects of survey methodology. Appl. Cognit. Psychol., 21: 277-287. https://doi.org/10.1002/acp.1340 [15] Schwarz, N. (1999). Self-reports: How the questions shape the answers. American Psychologist, 54(2), 93–105. https://doi.org/10.1037/0003-066X.54.2.93 [16] Sheskin, DJ (2004). Handbook of parametric and nonparametric statistical procedures. 3rd ed. Boca Raton: Chapman & Hall /CRC. [17] Toepoel, V., & Lugtig, P. (2014). What happens if you offer a mobile option to your web panel? Evidence from a probability-based panel of internet users. Social Science Computer Review, 32, 544–560. [18] Wang, R.Y., & Strong, D.M. (1996). Beyond Accuracy: What Data Quality Means to Data Consumers. Journal of Management Information Systems, 12(4), S.5-33. [19] Wells, T., Bailey, J.T., & Link, M.W. (2014). Comparison of smartphone and online computer survey administration. Social Science Computer Review, 32, S.238-255.