Das Internet in der Tasche mit sich tragen – was vor 25 Jahren eine utopische Vorstellung war, ist heute trivial. Die Einführung des Smartphones hat unser Leben verändert, nicht zuletzt auch die Markt- und Meinungsforschung.
Mit immer besseren Internetverbindungen, grösseren Bildschirmen und einer schnellebigeren Gesellschaft mit permanenter Aufmerksamkeitsknappheit[5] stieg das Bedürfnis im letzten Jahrzehnt stark an, Umfragen auch auf Mobilgeräten anbieten und ausfüllen zu können. Diese erhöhte Nachfrage mobiler oder zumindest mobilkompatibler Umfragen schafft nicht nur neue Herausforderungen für das Design und die Handhabung von Onlineumfragen, sondern muss auch hinsichtlich Datenqualität differenziert betrachtet werden.
Anhand anonymisierter Meinungsdaten einer Kundenbefragung eines grossen Schweizer Retailers, die 2014 lanciert wurde und seither täglich neue Rückläufe verzeichnet, analysieren wir die Entwicklung der mobilen Teilnahmen und deren Auswirkung auf die Datenqualität.
Datenqualität – Was ist das eigentlich?
70 Millionen Suchergebnisse bei Google demonstrieren die Relevanz des Begriffs “Data Quality” eindrücklich. Während im Alltag der Begriff “Datenqualität” häufig mit der Richtigkeit (Präzision) von Daten gleichgesetzt wird, ist Datenqualität in der Markt- und Meinungsforschung komplexer. Hier stehen am Ende der Datenverarbeitung Auftraggebende oder Forschende als Consumer der Daten. Deshalb ist es besonders wichtig, zu verstehen, dass Datenqualität aus Consumer-Sicht oft über die Präzision von Werten hinausgeht und auch Aspekte wie beispielsweise Glaubwürdigkeit, Relevanz, Vollständigkeit, Interpretierbarkeit, Konsistenz und Zugänglichkeit von Daten für Consumer berücksichtigt[18]. Relevanz zum Beispiel umfasst, dass Daten für ihren beabsichtigten Zweck tatsächlich geeignet sind, denn eine schlechte Datenqualität kann zu fehlerhaften Entscheidungen und ineffizienten Geschäftsprozessen führen, während eine hohe Datenqualität eine fundierte Entscheidungsfindung, bessere Geschäftsprozesse und letztendlich bessere Geschäftsergebnisse unterstützt.
Datenqualität, die in der Literatur mit zahlreichen verschiedenen Modellen beschrieben wird[6], kann durch geeignete Massnahmen optimiert werden. Einerseits vor der Feldphase, mittels elaboriertem Sampling, stringenter Fragebogenkonzeption und Pretesting. Andererseits in der Analyse und der technischen Bereinigung der bereits gewonnenen Daten. Hinzu kommen Meta-Aspekte der Datenqualität wie Passung der Daten zur Forschungsfrage, Prozesstransparenz, faire Datengewinnung oder proaktiver Datenschutz, die Empowerment für Kundinnen und Kunden bewirken[10].
Fallstudie: Kundenbefragung eines grossen Schweizer Retailers
Unsere Analyse erhebt erstmals a) eine durchmischte, reale Zielgruppe (Kundinnen und Kunden eines Retailers) mit b) grosser Datenmenge c) für die Schweiz und hebt sich damit deutlich von bisherigen Studien ab. Sie orientiert sich methodologisch am Vorgehen von Schlosser und Mays[13], die 2018 den Einfluss von mobilen Teilnahmen auf die Datenqualität an einer Gruppe von 820 deutschen Studierenden untersuchten.
Unsere Analyse greift auf vollständig anonymisierte Daten der Kundenbefragung eines Schweizer Retailers zurück, die 2014 in einem Unternehmensbereich lanciert und anschliessend sukzessiv auf weitere Unternehmensbereiche ausgeweitet wurde. Stand Mai 2023 lagen 345’000 Umfragerückläufe mehrsprachig (de, fr, it) schweizweit vor. Der Fragebogen enthält 6 Fragen. Darunter befinden sich eine Frage zur Weiterempfehlungsbereitschaft, eine Tabelle mit 5 Items und elfstufiger Likert-Skala, eine Frage mit offener Textantwort und zwei Ja-Nein-Fragen. Für die Beantwortung stehen die im Internet verbreiteten Radiobuttons und Textfelder zur Verfügung. Die mittlere Bearbeitungszeit beläuft sich auf rund 2 Minuten. Es werden keine soziodemografischen Daten erhoben. Als Befragungssoftware wird die Umfrageplattform von onlineumfragen.com genutzt. Die Kundinnen und Kunden werden in einem mixed-mode Verfahren via E-Mail (ca. 95%) und SMS eingeladen (ca. 5%).
Entwicklung der Relevanz mobiler Teilnahmen 2014 bis 2023
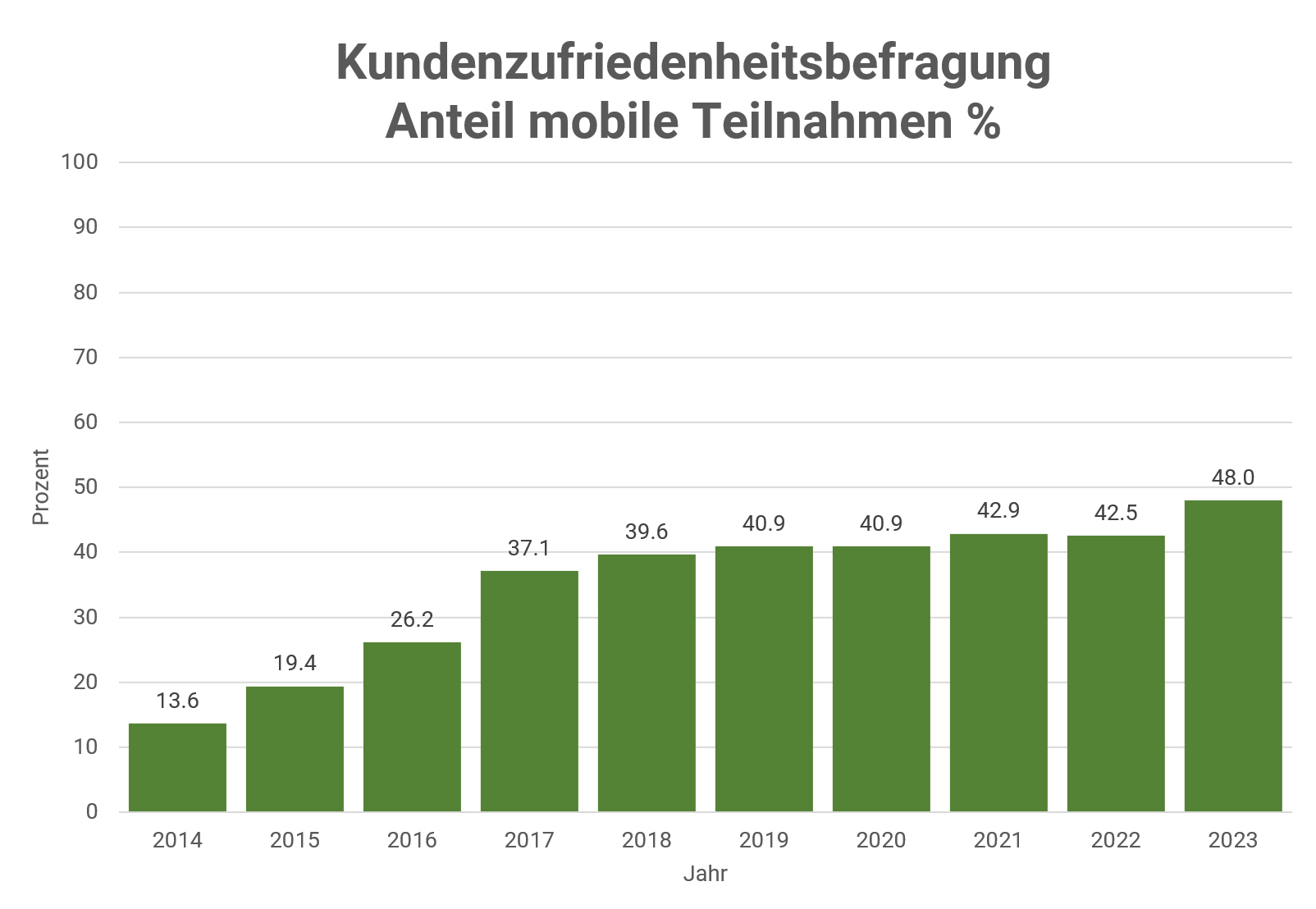
In unserem Sample stieg der Anteil der mobi-len Teilnahmen, gemessen über Browser Agent Strings und Bildschirmgrösse, seit 2014 stetig. Mobile Teilnahmen haben sich in der Zeit von 2014 bis 2023 mehr als verdreifacht.
Eine Abschwächung der Entwicklung in den letzten fünf bis sechs Jahren könnte mit einer Sättigung der Zielgruppe zu tun haben: Wer potenziell mobil teilnehmen möchte, verfügt nun auch über die Möglichkeit.
Auswirkungen des mobilen Modus auf die Datenqualität
Um Datenqualität in konkreten Aspekten zu messen, wurde ein Subsample aus insgesamt 46’581 aktuellen Teilnahmen herangezogen. Die Eingrenzung erfolgte nach Datum jünger als 01.01.2022. Folgende Kriterien der Datenqualität wurden untersucht:
- Reaktionszeit zur Umfrage-Einladung
- Bearbeitungszeit für eine Frage
- Bearbeitungszeit ganze Umfrage
- Abschlussrate
- Item nonresponse
- Straightliner
- Extrem Response Style (ERS)
- Länge der Antworten auf offene Fragen
Benötigen mobile Teilnehmende mehr Zeit?
Zunächst wurde die Reaktionszeit zur Umfrage-Einladung ermittelt. Sie wurde über die Differenz des Zeitstempels der Einladung zur Umfrage (Versandzeitpunkt Einladungs-E-Mail) zum Zeitstempel des Aufrufs der Umfrage (Klick auf Umfragelink) berechnet und auf Ausreisser bereinigt, indem nur Teilnahmen, die innert 7 Tagen ab Einladung erfolgten, berücksichtigt wurden.
Da die Teilnehmenden auf Mobilgeräten daran gewöhnt sind, ihr Mobiltelefon ständig bei sich zu tragen und erreichbar zu sein, gehen wir davon aus, dass diese Befragten schneller reagieren als Befragte, die die Einladung über ihren PC erhalten (Hypothese 1).
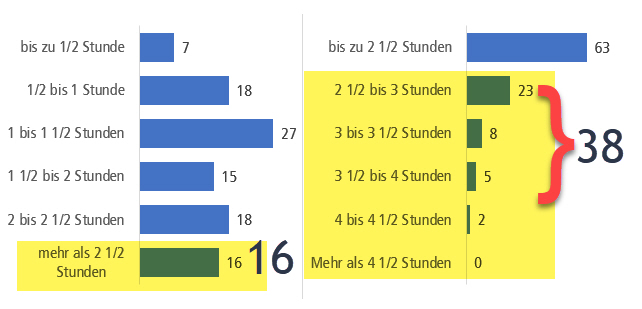
Auf Mobilgeräten betrug die mittlere Reaktionszeit 13 Stunden (M=13.15; SD=25.43; nmob=23’685), auf Nichtmobilgeräten 22.75 Stunden (M=22.75; SD=34.26; npc=20’481), die Abweichung ist gemäss Welch-Test t(37137)=32.86 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.32 entspricht einem mittleren Effekt.
Wurden zusätzlich Teilnahmen zwischen 7 und 14 Tagen nach Einladung berücksichtigt, ergab sich mobil eine mittlere Reaktionszeit von 17.5 Stunden (M=17.53; SD=40.11; nmob=24’169), auf Nichtmobilgeräten 31 Stunden (M=31.09; SD=53.81; npc=21‘335), die Abweichung ist gemäss Welch-Test t(38947)=30.08 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.29 zeigt einen knapp mittleren Effekt.
Die Teilnahmen durch Personen, die Mobilgeräte für die Umfrage nutzen, erfolgen also im Mittel rund 9.6 (resp. 13.6) Stunden früher und damit deutlich näher am Zeitpunkt der Einladung (Hypothese 1 bestätigt). Dies könnte je nach Umfrage einen Einfluss auf Themen wie Erinnerungsleistung, Teilnahmemotivation oder die Emotionalität der Rückmeldungen haben.
Die mittlere Beantwortungszeit für eine Frage wurde als Differenz zwischen dem Zeitpunkt der abgeschlossenen Anzeige im Browser und dem Klicken auf den Button “Speichern – nächste Frage” bei einer Tabellenfrage bestehend aus 5 Items mit elfstufiger Likert-Skala zur Zufriedenheit bestimmter Aspekte des Einkaufserlebnisses gemessen. Die Frage wurde mobil und nicht mobil methodologisch identisch präsentiert und nur im Seitenverhältnis der Tabelle, der Breite und der Schriftgrösse im Sinne einer responsiven Darstellung mobil optimiert. Für die mobilen Teilnahmen rechnen wir mit einer erhöhten Beantwortungszeit für komplexere Tabellenfragen[4], da diese mobil schwieriger zu erfassen sind, die mobile Befragungssituation oft konzentriertes Beantworten erschwert, Fragen etwas weniger leicht zu lesen sind und die technische Erfassung der Antworten (Touchscreen) etwas anspruchsvoller und fehleranfälliger ist (Hypothese 2).
Das arithmetische Mittel der Bearbeitungszeit wurde auf Ausreisser bereinigt (Zeit > 10 Sekunden und < 180 Sekunden) und liegt bei den mobilen Teilnahmen bei 40 Sekunden (M=40.09; SD=23.01; nmob=20’333), bei den nicht mobilen Geräten bei 36 Sekunden (M=35.70; SD=20.53; npc=19’402).
Die Abweichung ist gemäss Welch-Test t(39555)=20.09 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.2 zeigt einen kleinen, aber vorhandenen Effekt. Die Bearbeitungszeit ist auf Nichtmobilgeräten etwas geringer (Hypothese 2 bestätigt).
Die Bearbeitungszeit für die ganze Umfrage wurde aus der Differenz der Anzeige der ersten Frage am Bildschirm und des Klickens auf den Button “Speichern” bei der letzten Frage berechnet.
Weil das Ausfüllen einer Umfrage über Mobilgeräte mühsamer und störanfälliger sein kann und auch die mobile Befragungssituation in der Regel mehr Ablenkungen ausgesetzt ist, könnte die Gesamtbearbeitungszeit mobil höher ausfallen. Andererseits könnte durch genau diese situativen Faktoren die Motivation, die Umfrage elaboriert “in Ruhe” und genau auszufüllen, abgeschwächt sein, und es findet vermehrt eine schnellere, oberflächlichere kognitive Verarbeitung statt, speziell bei Fragen, die sich nicht mit dem individuellen inhaltlichen Feedback-Kern decken und eher als Ballast empfunden werden. Daher vermuten wir in Abwägung dieser Überlegung für die mobilen Teilnahmen eine etwas kürzere Gesamtbearbeitungszeit (Hypothese 3).
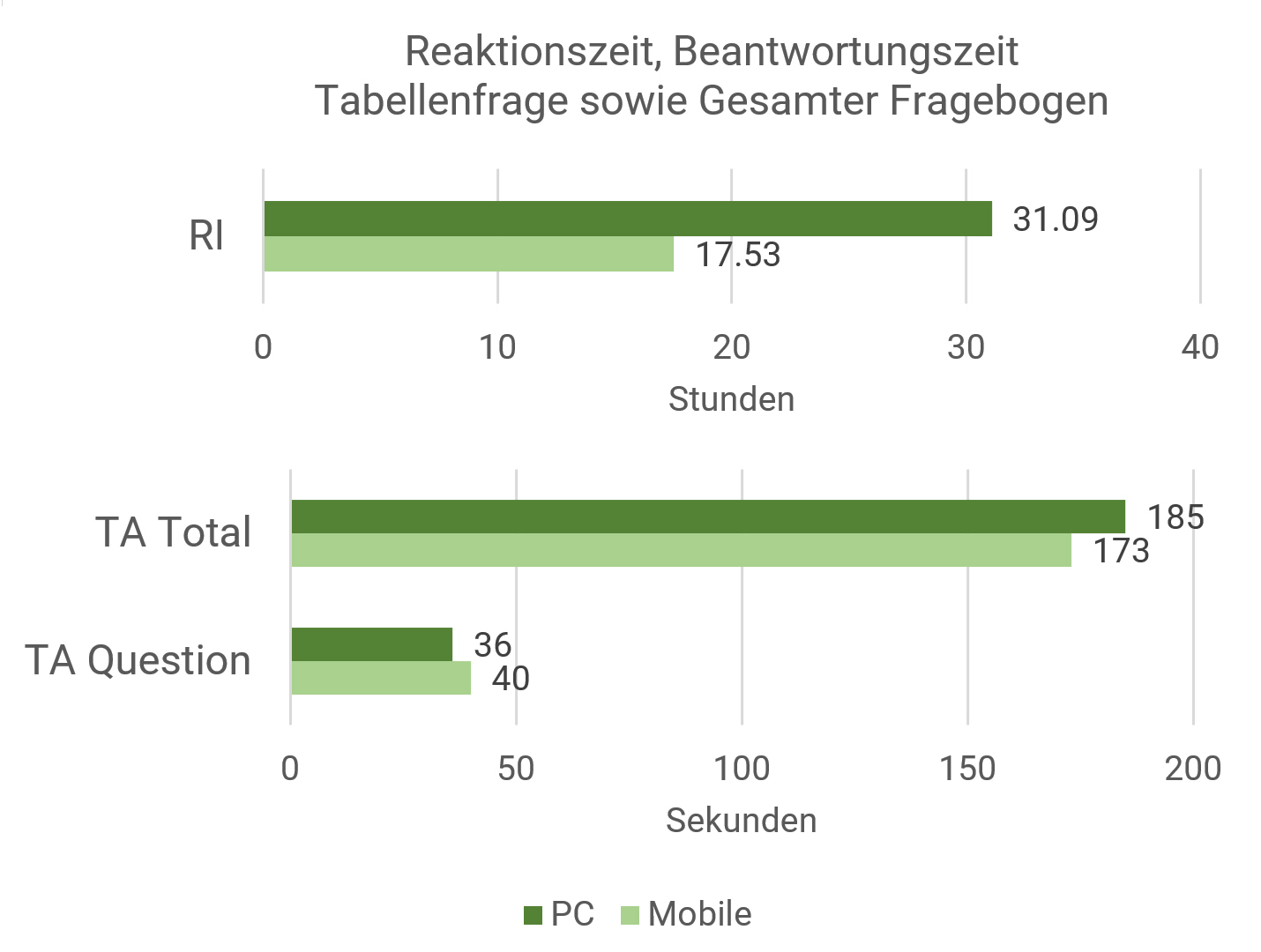
Das arithmetische Mittel der Gesamtbearbeitungszeit wurde auf Ausreisser bereinigt (Zeit > 10 Sekunden und < 300 Sekunden) und liegt bei den mobilen Teilnahmen bei 118 Sekunden (M=118.17; SD=63.68; nmob=17’435), bei den nicht mobilen Geräten bei 116 Sekunden (M=115.73; SD=65.40; npc=16’915).
Die Abweichung ist gemäss Welch-Test t(34237)=3.50 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.038 zeigt einen sehr kleinen Effekt. Die Bearbeitungszeit ist auf Mobilgeräten somit minimal länger.
Ein spannendes Bild zeigt sich bei einer weniger starken Bereinigung von Ausreissern (Zeit > 10 Sekunden und < 3600 Sekunden). Dann liegt die Gesamtbearbeitungszeit bei den mobilen Teilnahmen bei 173 Sekunden (M=172.50; SD=237.03; nmob=19’619), bei den nicht mobilen Geräten bei 185 Sekunden (M=184.69; SD=256.90; npc=19’518). Diese Abweichung ist gemäss Welch-Test t(38851)=4.88 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.05 zeigt einen kleinen Effekt, aber nun dauern die PC-Teilnahmen länger. Dies könnte damit zusammenhängen, dass es auf PCs eine höhere Anzahl an Teilnehmenden gibt, die die Umfrage unterbrechen und nach einer Pause (z.B. Mittagspause, Telefongespräch, etc.) fortsetzen. Damit ergeben sich schnell sehr lange (aber nicht andauernd von Aktivität geprägte) Bearbeitungszeiten. Unter Ausschluss von Gesamtbearbeitungszeiten über 5 Minuten sind mobile Teilnahmen also geringfügig langsamer und weisen weniger Pausen auf (Hypothese 3 teilweise abgelehnt). Weshalb bei Einschluss von Gesamtbearbeitungszeiten bis zu einer Stunde die PC-Teilnahmen länger dauern, müsste weiter untersucht werden und könnte auch mit einem höheren Anteil an älteren und weniger IT-affinen Personen in der PC-Gruppe zusammenhängen, sowie auch damit, dass am PC generell etwas längere Texte bei Textantworten erfasst werden – jedoch werden diese oft auch schneller getippt (siehe Hypothese 8).
Brechen mobile Teilnehmende häufiger ab?
Weiter wurde die Abschlussrate berechnet. Sie bezeichnet die Anzahl der Teilnehmenden, die den Fragebogen bis zum Schluss ausgefüllt haben (letzte Frage wurde beantwortet).
Da das Ausfüllen der Umfrage über mobile Geräte weniger bequem sein kann, in “mobilen Situationen” oftmals vermehrt Ablenkungen auftreten und eine Umfrage auch nebenbei beantwortet werden könnte[1][3][8], sollte die Abbruchquote in der Mobil-Gruppe höher sein als in der PC-Gruppe (Hypothese 4).
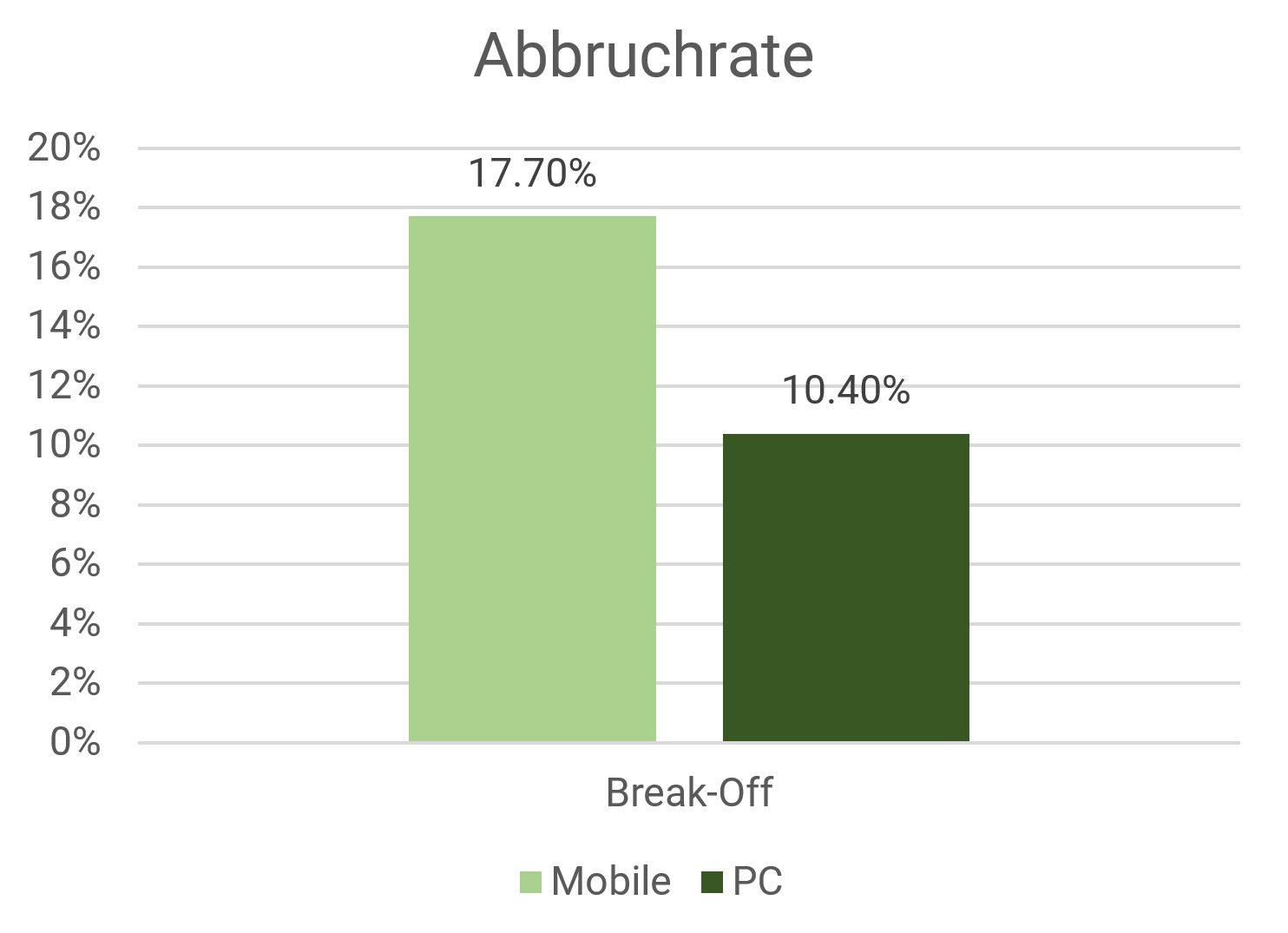
Auf Mobilgeräten betrug mit einer Stichprobengrösse von nmob=24’613 die Complete-Rate 82.3% (ncomp_mob=20’259), sowie mit npc=21’968 auf Nichtmobilgeräten 89.6% (ncomp_pc=19’679). Die Abweichung hat ein Odds Ratio[16] von 0.5412 mit p<0,001 (entspricht Cohen’s d von rund 0.33 als mittlerer Effekt[2]), der Unterschied ist gemäss Fisher‘s Exact Test signifikant mit p<0,001. Die Abschlussrate ist also auf Mobilgeräten rund 7,3 Prozentpunkte tiefer. Umgekehrt betrachtet wurde eine Abbruchquote (Break-Off Rate) von mobil 17.7% gegenüber nicht mobil 10.4% beobachtet. Dies entspricht einer doch deutlichen Erhöhung um zwei Drittel (Hypothese 4 bestätigt).
Antworten mobile Teilnehmende weniger aufmerksam?
Der Begriff Item Non-Response beschreibt das Nichtbeantworten von Fragen, oder – bei Pflichtfragen, die bei Auslassen nochmals gestellt werden wie in unserem Fragebogen – die Auswahl einer Ausweichkategorie wie zum Beispiel “weiss nicht” oder “keine Antwort” bei Single- und Multiple-Choice-Fragen oder Tabellen mit Likert-Skalen. Untersucht haben wir dazu die im Fragebogen enthaltene Tabellenfrage mit 5 Items/Zeilen, die eine elfstufige Likert-Skala von höchst zufrieden bis höchst unzufrieden sowie die Ausweichkategorie “nicht beurteilbar” anbietet. Unsere Berechnung zeigt, wie oft die Ausweichkategorie ausgewählt wurde.
Aus denselben Gründen wie bei Hypothese 4 vermuten wir, dass die Häufigkeit von Item Non-Response mobil höher ist als am PC (Hypothese 5). Limitierend für diese Studie ist anzumerken, dass Pflichtfragen eingesetzt wurden und daher das Kriterium “Item Non-Response” keine eigentlichen Nicht-Antworten erfasst, sondern lediglich die Nutzung der Ausweichkategorie, und diese zudem mit “nicht beurteilbar” statt typischerweise “weiss nicht/keine Antwort” beschriftet ist.
Auf Mobilgeräten betrug mit einer Gesamtantwortanzahl von nmob=107’131 der Anteil an “nicht beurteilbar”-Antworten 3.39% (nw_mob=3’626), auf Nichtmobilgeräten mit npc=101’225 Antworten 4.48% (nw_pc=4’535).
Diese Abweichung hat ein Odds Ratio[16] von 1.3385 mit p<0,001 (entspricht Cohen’s d von 0.16 als schwacher Effekt[2]), der Unterschied ist gemäss Fisher‘s Exact Test signifikant mit p<0,001. Der Prozentsatz an “nicht beurteilbar”-Antworten ist entgegen unserer Vermutung auf Mobilgeräten damit um rund einen Viertel tiefer (absolut 1.09%). Die Hypothese 5 wird damit vorläufig abgelehnt.
Dies könnte auf eine höhere Datenqualität hinweisen, könnte aber auch daran liegen, dass die Ausweichkategorie mobil auf Grund des kleinen Bildschirms der Position ganz rechts als marginal wahrgenommen wird, oder dass Teilnehmende auf Mobilgeräten zu bequem sind, die vorhandene Ausweichkategorie überhaupt erst auszuwählen, und daher sogenannte Trash-Antworten hinterlegen und die Ausweichkategorie schlichtweg nicht akkurat benutzen. Zum Beispiel, indem eine Spalte mit immer gleichen Antworten ausgewählt wird (“herunterkreuzeln” ohne nachzudenken).
Um diese Art der Verschmutzung genauer zu untersuchen, wurden nachfolgend auch einige Typen von Straightlining untersucht. Es handelt sich dabei um ein Null-Varianz-Antwortverhalten, bei dem ein immer gleicher Skalenpunkt unabhängig von der Skalenbreite, -ausrichtung und Frageformulierung für alle Zeilen einer Skalentabelle gewählt wird, was häufig bei unmotivierten Teilnehmenden auftritt[7]. Straightlining kann unter gewissen Umständen dennoch valide sein, zum Beispiel wenn eine Item-Batterie eine hohe interne Konsistenz aufweist und alle Items in dieselbe Richtung formuliert sind[12]. Bei unserem Vergleich zwischen mobilen und nicht mobilen Teilnahmen ist dies besonders spannend, da in beiden Gruppen die Zahl der validen Straightliner konstant sein müsste (da sich die eigentliche Meinung, auch wenn sie über die 5 Items hinweg einheitlich ist, von mobil und nicht mobil teilnehmenden Personen bei so grossen Stichproben nicht unterscheiden dürfte) und lediglich die Zahl der auf Grund der Geräteverschiedenheit unterschiedlich agierenden Teilnehmenden, also die nicht validen Straightliner, variieren dürfte. Dieses sozusagen geräteinduzierte Straightlining stellt eine Datenverschmutzung dar.
Wir vermuten, dass mobile Teilnehmende häufiger Straightlining aufweisen als Teilnehmende am PC (Hypothese 6).
Auf Mobilgeräten (Stichprobengrösse von nmob=21’500) betrug der Anteil an Teilnehmenden mit Straightlining 35.47% (nst_mob=7627), auf Nichtmobilgeräten (Stichprobengrösse mit npc=20’252) 31.19% (nst_pc=6316), diese Abweichung hat ein Odds Ratio[16] von 1.2131 mit p<0,001 (entspricht Cohen’s d von rund 0.10 als schwacher Effekt[2]), der Unterschied ist gemäss Fisher‘s Exact Test mit p<0,001 signifikant. Straightlining ist damit bei Mobilgeräten etwas häufiger problematisch, insbesondere, wenn man davon ausgeht, dass valides Straightlining (bewusstes, elaboriertes Entscheiden für immer dieselbe Skalenausprägung in allen Zeilen der Tabellenfragen) bei beiden Vergleichsgruppen theoretisch gleich häufig sein müsste. Eine allfällig doch vorhandene Differenz müsste demnach ausschliesslich den Anteil “verschmutzter Daten” auf Grund von demotivational bedingtem Straightlining widerspiegeln. Damit dürfte der tatsächliche Effekt grösser sein als der gemessene Effekt. Beispielsweise würden nach Abzug von angenommen 30% validen Straightliner für die nicht validen Straightliner mobil 5.47% und nicht mobil 1.19% “übrig bleiben”, also schon fast 5 mal mehr (Hypothese 6 bestätigt).
Der Begriff Extreme Response Style (ERS) bezeichnet ein spezifisches Antwortverhalten, bei dem in Tabellenfragen mit Likert-Skalen die Extrempunkte übermässig oder ausschliesslich genutzt werden. Wir klassifizieren für diese Studie Teilnehmende, die ausschliesslich Skalenendpunkte genutzt haben und mindestens eine Zeile mit einer diametral anders gepolten Antwort ausgewählt haben (z.b. 4 mal “höchst zufrieden” und 1 mal “höchst unzufrieden”, 3 mal “höchst zufrieden” und 2 mal “höchst unzufrieden”, 2 mal “höchst zufrieden” und 3 mal “höchst unzufrieden” etc.).
Wir vermuten, dass ESR auf Grund der Seltenheit des Phänomens bei mobilen Teilnahmen nicht signifikant häufiger auftritt als am PC (Hypothese 7).
Auf Mobilgeräten (Stichprobengrösse von nmob=21’500) betrug der Anteil an Teilnehmenden mit ESR 0.35% (nesr_mob=75), auf Nichtmobilgeräten (Stichprobengrösse mit npc=20’252) 0.38% (nesr_pc=77), diese Abweichung hat ein Odds Ratio[16] von 1.3993 mit p=0,62, der Unterschied ist gemäss Fisher‘s Exact Test nicht signifikant. Es gibt damit keinen signifikanten (allenfalls nur zufälligen) Unterschied in der Häufigkeit von Extreme Response Style (ESR) zwischen Mobil- und Nichtmobilgeräten (Hypothese 7 bestätigt).
Sind mobile Textantworten kürzer?
Die Länge der Textantworten auf offene Fragen kann ebenfalls ein Qualitätskriterium sein, weil durch kürzere Antworten oft weniger substanzielle oder ungenauere Aussagen für Auftraggebende herausgearbeitet werden können.
Bei mobilen Teilnahmen gehen wir aufgrund der umständlicheren Eingabetechnologie, der eingeschränkten Platzverhältnisse und der mobilen Befragungssituation, die weniger elaborierte und zeitlich limitierte Reflexion begünstigen, von deutlich kürzeren Eingaben aus (Hypothese 8). Dies wurde bereits von Mavletova[9] sowie Toepoel and Lugtig[17] berichtet.
Das ausreisserbereinigte arithmetische Mittel der Textlängen grösser als 0 und kleiner als 500 Zeichen auf die Frage “Was (…) hat Sie am meisten gefreut (…) oder verärgert?” liegt bei den mobilen Teilnahmen bei 71.57 Zeichen (M=71.57; SD=78.20; nmob=16’156), bei den nicht mobilen Geräten bei 100.95 Zeichen (M=100.95; SD=97.34; nmob=15’427).
Die Abweichung ist gemäss Welch-Test t(29572)=29.48 signifikant mit p<0,001 und die Effektstärke mit Cohen’s d=0.33 zeigt einen mittleren Effekt. Die Teilnehmenden, die nicht mobil geantwortet haben, hinterlegten also deutlich längere Texte (Hypothese 8 bestätigt).
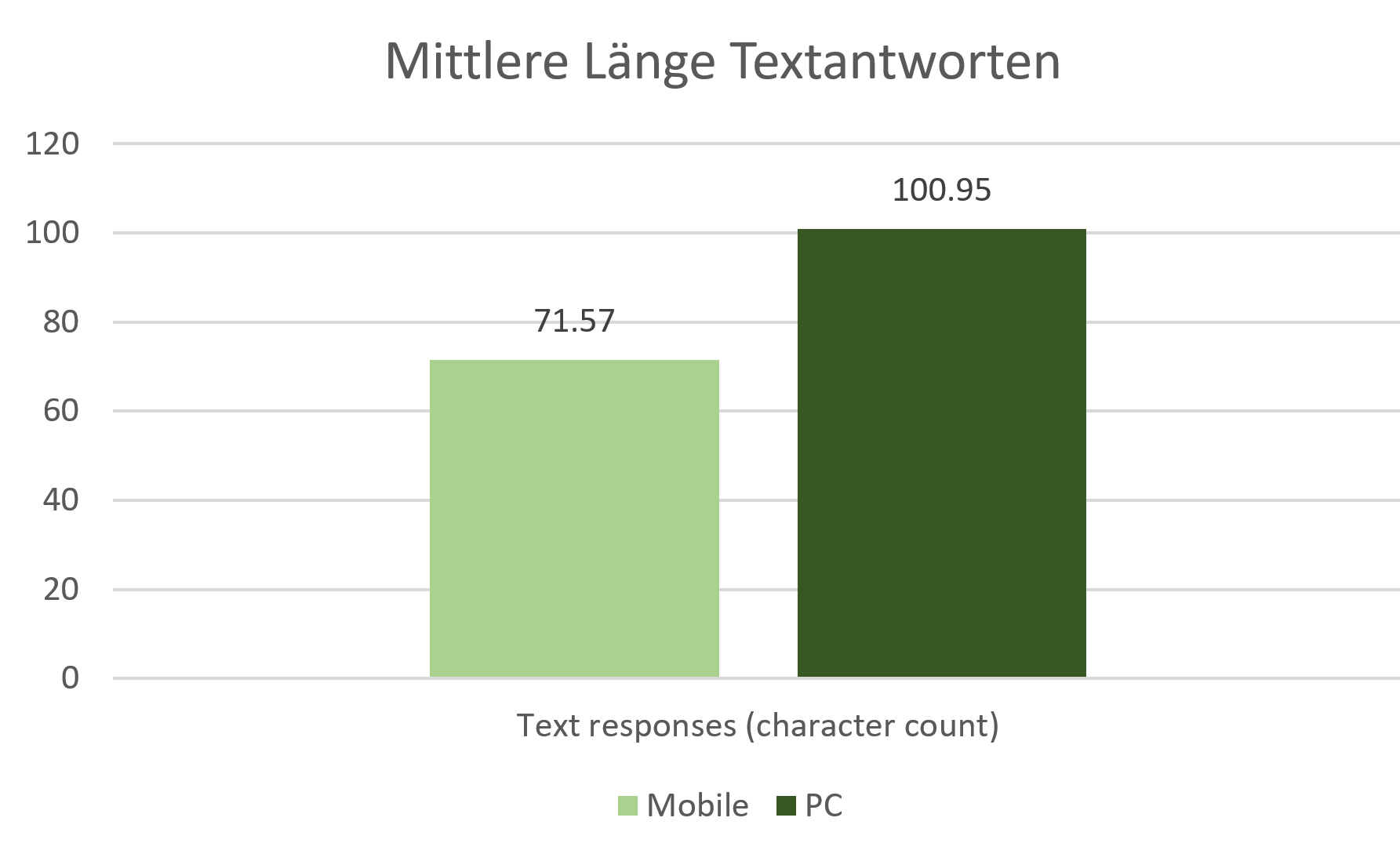
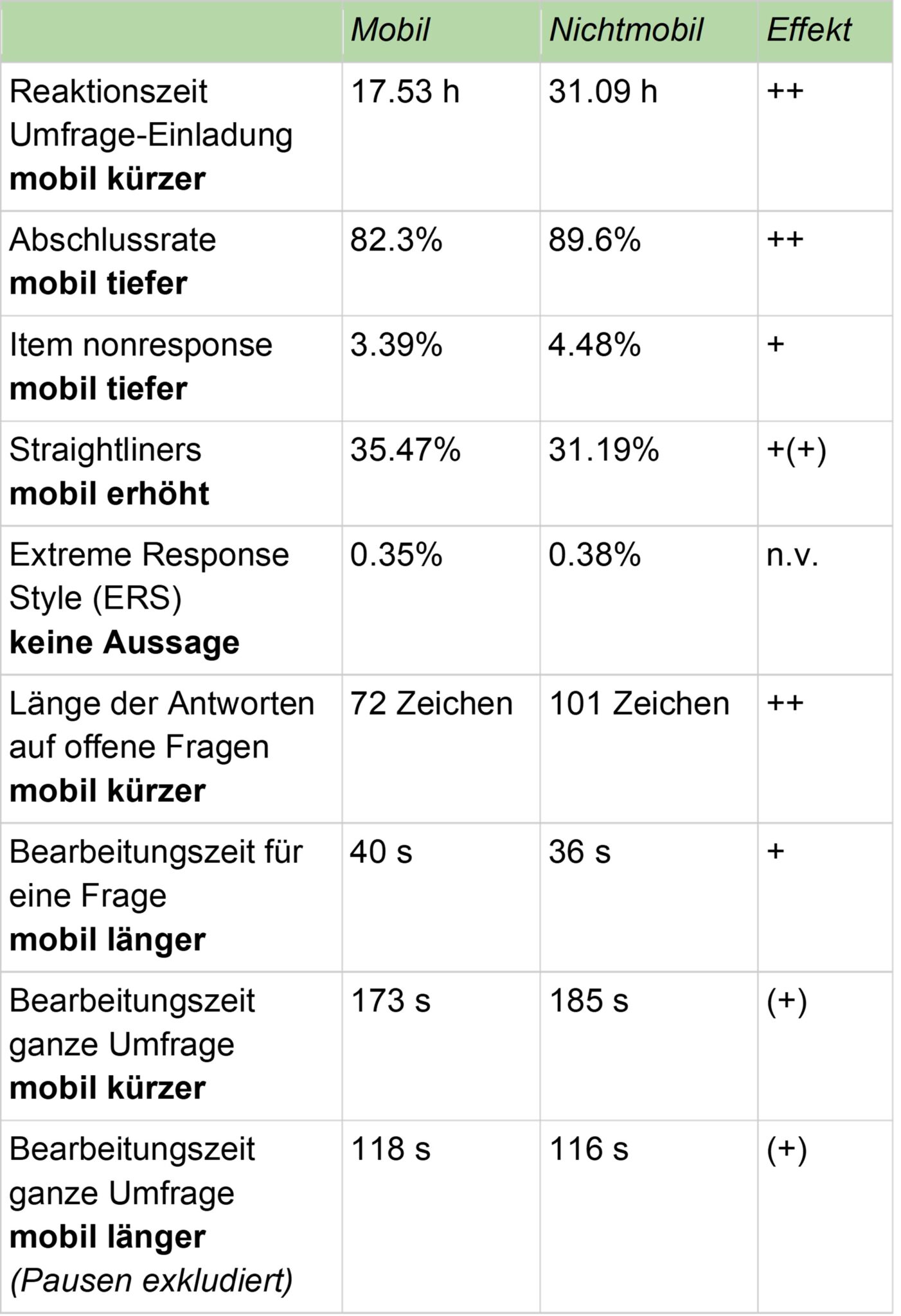
Tabelle 1: Zusammenfassung der Ergebnisse und Effektstärke
Fazit und Empfehlungen für die Praxis?
Datenqualität in Onlineumfragen wurde im Vergleich zwischen mobilen und nicht mobilen Teilnahmen bisher wenig untersucht, wobei Ergebnisse vorangehender Studien mit einem erstmals sehr grossen Sample aus einer aktuellen Schweizer Kundenbefragung in einer realen für die Marktforschung relevanten Zielgruppe im Retail-Sektor weitgehend bestätigt werden.
Mobile Teilnahmen zeichnen sich in der vorliegenden Untersuchung im Unterschied zu nicht mobilen Teilnahmen aus durch…
- eine erhöhte Abbruchrate (=tiefere Abschlussrate),
- eine höhere Datenverschmutzung durch nicht valides Straightlining,
- deutlich kürzere offene Textantworten mit möglicherweise weniger substanziellen oder detaillierten Aussagen,
- eine schnellere Reaktionszeit auf Umfrageeinladungen,
- etwas weniger häufige Auswahl der Ausweichkategorie “nicht beurteilbar” in Likert-Skalen (was in Bezug auf Datenqualität unklar ist, da Teilnehmende unter Umständen mobil vorziehen, Trash-Antworten zu hinterlegen, anstatt akkurat die Ausweichkategorie zu benutzen, oder diese technisch auf Mobilgeräten zu wenig salient platziert ist),
- uneindeutige Ergebnisse zur Antwortdauer auf einzelne Fragen und des gesamten Fragebogens, wobei auf nicht mobilen Geräten mehr Pausen gemacht werden.
Grössere Unterschiede zwischen mobilen und nicht mobilen Teilnahmen bezüglich Datenqualität sind mit zunehmender Verbreitung technisch hochstehender Smartphones und Tablets und responsiven Fragebögen grundsätzlich nicht zu erwarten, da die noch vor wenigen Jahren beschriebenen Eingabehürden (schlechte Prozessorgeschwindigkeit, sehr kleine Screens, Usability, mangelhafte Netze[11]) weitgehend aus dem Weg geräumt wurden.
Eine zentrale Ausnahme ist die zu erwartende geringere Textmenge und die damit möglicherweise weniger elaborierten und ausführlichen Angaben bei Fragen mit offenen Textfeldern, die gerade bei Fragebögen mit einer gewissen qualitativen Orientierung die Datenqualität ganz wesentlich beeinträchtigen können.
Eine in mobilen Teilnahmen erhöhte Zahl an Straightliner – wie in dieser Studie gezeigt – kann durch ausgeklügelte Methoden[7][10] auch nachträglich in Survey Daten bereinigt werden.
Zusammenfassend empfehlen wir, obenstehende Implikationen für zukünftige geplante Umfragen regelmässig zu reflektieren sowie potenzielle Vor- und Nachteile transparent zu kommunizieren. Darüber hinaus empfehlen wir für alle Onlineumfragen intensives Pretesting in gemischten Zielgruppen (mobil und nicht mobil), eine entsprechende und gezielte Analyse der Pretest-Daten vor Feldstart auf für das Projekt wesentliche und in diesem Artikel beschriebene Parameter hin sowie das vorsorgliche Einbinden fachlicher Beratung durch Experten, gerade bei sensitiven Projekten.
Literaturverzeichnis weiter unten

Raffael Meier
Mitgründer/CTO von onlineumfragen.com
raffael.meier@onlineumfragen.com
+41 44 500 5137

Die Autoren
Raffael Meier, MA, MSc – Mitgründer/CTO von onlineumfragen.com und Pionier der deutschsprachigen Onlineumfragetechnologie. Er befasst sich mit gesellschaftlichen und methodologischen Aspekten von Daten und berät Kundinnen und Kunden mit dem Ziel «Empowerment»
Nina Gwerder, MA – Lead Consultant bei onlineumfragen.com und spezialisiert auf die Beratung namhafter nationaler und internationaler Unternehmen rund um das Thema Onlineumfragen und deren effektive Auswertung
Download Artikel
Swiss Insights News #4

Institute Member von
SWISS INSIGHTS
Alle SWISS INSIGHTS News finden Sie hier: SWISS INSIGHTS NEWS
Literaturverzeichnis
[1] Bosnjak, M., Poggio, T., Becker, K.R., Funke, F., Wachenfeld, A., & Fischer, B. (2013). Online survey participation via mobile devices. Conference Paper, The American Association for Public Opinion Research (AAPOR) 68th Annual Conference, 2013, Boston, MA.
[2] Borenstein, M., Hedges, L.V., Higgins, J.P.T., & Rothstein, H.R. (2009). Converting Among Effect Sizes. In Introduction to Meta-Analysis (eds M. Borenstein, L.V. Hedges, J.P.T. Higgins and H.R. Rothstein).
[3] de Brujine, M., & Wijbant, A. (2013) Comparing survey results obtained via mobile devices and computers: An experiment with a mobile web survey on a heterogeneous group of mobile devices versus a computer-assisted web survey. Social Science Computer Review, 31, S.482-504.
[4] Couper, M. P., & Peterson, G. (2016). Why do web surveys take longer on smartphones? Social Science Computer Review. First published on February 11, 2016. doi:10.1177/0894439316629932
[5] Franck, G. (1998). Ökonomie der Aufmerksamkeit. Ein Entwurf. Dtv, München 2007, ISBN 978-3-423-34401-2.
[6] Haug, A. (2021). Understanding the differences across data quality classifications: a literature review and guidelines for future research. Industrial Management and Data Systems, 121(12), 2651–2671. https://doi.org/10.1108/IMDS-12-2020-0756
[7] Jandura, O. (2018). Fake Data? Zur Trennung von sauberen und verschmutzten Daten bei selbstadministrierten Befragungsmodi. In Rössler P. & Rossman, C. (Hrsg.), Kumulierte Evidenzen. Wiesbaden: Springer VS, S. 207-223.
[8] Mavletova, A. (2013). Data Quality in PC and mobile web surveys. Social Science Computer Review, 31, S.725-743.
[9] Mavletova, A., & Couper, M. P. (2015). A meta-analysis of breakoff rates in mobile web sur-veys. In D. Toninelli, R. Pinter, & P. de Pedraza (Eds.), Mobile research methods: Opportunities and challenges of mobile research methodologies (pp. 81–98). London, England: Ubiquity Press.
[10] Meier, R., & Gwerder, N. (2022). Dirty Data in Online Surveys. Wie Datenqualität vor und nach der Feldphase verbessert werden kann. In Swiss Data Insights Association (Hrsg.), Swiss Insights Report 2022. Swiss Insights. https://swiss-insights.ch/wp-content/uploads/2023/01/Annual-Report-2022-klein.pdf
[11] Peytchev, A., & Hill, C.A. (2010). Experiments in mobile web survey design. Similarities to other modes and unique considerations. Social Science Computer Review, 28, S.319-355.
[12] Reunig, K., & Plutzer E. (2020). Valid vs. Invalid Straightlining: The Complex Relationship Between Straightlining and Data Quality. Survey Research Methods, 14(5), S.439-459
[13] Schlosser, S., & Mays, A. (2018). Mobile and Dirty: Does Using Mobile Devices Affect the Data Quality and the Response Process of Online Surveys?, Social Science Computer Review, 36(2), S.212-230. DOI: 10.1177/0894439317698437
[14] Schwarz, N. (2007). Cognitive aspects of survey methodology. Appl. Cognit. Psychol., 21: 277-287. https://doi.org/10.1002/acp.1340
[15] Schwarz, N. (1999). Self-reports: How the questions shape the answers. American Psychologist, 54(2), 93–105. https://doi.org/10.1037/0003-066X.54.2.93
[16] Sheskin, DJ (2004). Handbook of parametric and nonparametric statistical procedures. 3rd ed. Boca Raton: Chapman & Hall /CRC.
[17] Toepoel, V., & Lugtig, P. (2014). What happens if you offer a mobile option to your web panel? Evidence from a probability-based panel of internet users. Social Science Computer Review, 32, 544–560.
[18] Wang, R.Y., & Strong, D.M. (1996). Beyond Accuracy: What Data Quality Means to Data Consumers. Journal of Management Information Systems, 12(4), S.5-33.
[19] Wells, T., Bailey, J.T., & Link, M.W. (2014). Comparison of smartphone and online computer survey administration. Social Science Computer Review, 32, S.238-255.