Indem Unternehmen auf die Bedürfnisse und Interessen ihrer Kundschaft eingehen und ihnen personalisierte Angebote und Informationen zukommen lassen, können sie die Kundenzufriedenheit steigern und somit die Kundenbindung erhöhen.
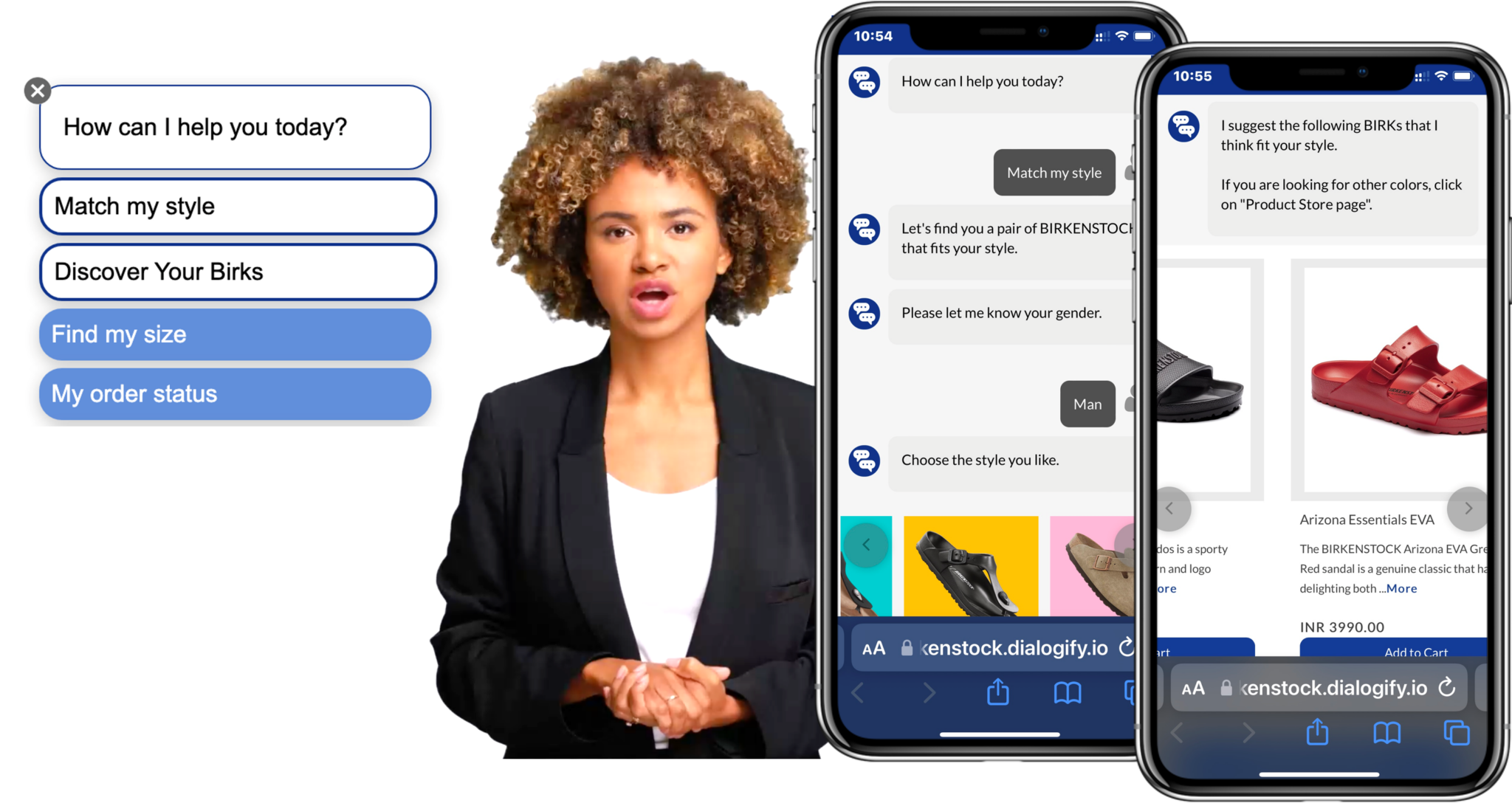
Ein Beispiel für die erfolgreiche Umsetzung von Conversational Marketing bietet das Unternehmen Birkenstock. Der bekannte Hersteller von Sandalen und Schuhen setzt auf virtuelle Produktberatung, um auch online seiner Kundschaft ein authentisches und personalisiertes Kauferlebnis zu bieten. Die virtuelle Beraterin namens Birki wurde in den Webshop des Unternehmens integriert und soll dem “Paradox of Choice” entgegenwirken. Kundinnen und Kunden können mit Birki interagieren und ihr ihre Bedürfnisse und Vorlieben mitteilen. Auf Basis dieser Informationen gibt Birki dann personalisierte Empfehlungen für passende Produkte.
Der Einsatz von Birki hat zu einer Steigerung der Konversionsrate und einer Reduktion von Warenkorbabbrüchen geführt. Zudem sammelt das Unternehmen wertvolle Daten und Insights über die Bedürfnisse und Vorlieben seiner Kundschaft, die in Zukunft für gezielte Werbekampagnen und personalisierte Angebote genutzt werden können.
Das Beispiel von Birkenstock zeigt, wie Conversational Marketing erfolgreich in die E-Commerce-Strategie eines Unternehmens integriert werden kann: Indem auf die Bedürfnisse und Interessen der Kundinnen und Kunden eingegangen wird, können Unternehmen die Customer Experience verbessern und somit auch ihre Verkaufszahlen steigern.
Fokus auf Personalisierung ist essenziell
Dabei ist der Fokus auf die Personalisierung besonders wichtig, weil Kunden auf relevante Nachrichten von Unternehmen gut reagieren. Unternehmen konzentrieren sich verstärkt auf die sogenannten Micro Moments, da diese Momente innerhalb der Customer Journey die generelle Wahrnehmung massgeblich beeinflussen. Das Thema Dialogmarketing wird verstärkt in die Multichannel- bzw. Omnichannel-Strategien der Unternehmen sowie in ihre Customer Experience-Konzepte integriert. Der automatisierte Kundendialog ist dabei eine passende strategische Option für Unternehmen.
Conversational Commerce, also z.B. der Einsatz von virtuellen Beratern im Online-Handel, hat in den letzten Jahren stark zugenommen. Immer mehr Marken erkennen die Bedeutung von personalisierter Beratung und Fachwissen, um den Umsatz im E-Commerce zu steigern.
Das Beispiel Birkenstock zeigt, dass der Einsatz von virtuellen Beratern ein effektiver Weg ist, um das Kundenerlebnis zu verbessern und den Umsatz zu steigern. Der virtuelle Berater sollte gut gestaltet und auf die Kundenbedürfnisse abgestimmt sein. Zudem sollten Unternehmen sicherstellen, dass sie die Datenschutzbestimmungen einhalten und die Transparenz gewährleisten, um das Vertrauen ihrer Kunden zu gewinnen und langfristige Beziehungen aufzubauen.
Einsatz von Chatbots als weitere Möglichkeit
Eine weitere Option, um Conversational Marketing umzusetzen, ist der Einsatz von Chatbots auf Basis von künstlicher Intelligenz. Hier kommt ChatGPT ins Spiel, ein leistungsstarkes Framework, welches von OpenAI entwickelt wurde. ChatGPT kann nicht nur Texte verstehen und darauf reagieren, sondern auch eine Vielzahl von Aufgaben automatisch ausführen, wie beispielsweise das Buchen von Terminen oder das Beantworten von häufig gestellten Fragen. Darüber hinaus kann ChatGPT kontinuierlich lernen und sich verbessern, indem es die Interaktionen mit der Kundschaft analysiert und auf dieser Basis seine Antworten und Empfehlungen anpasst. Unternehmen können somit eine personalisierte und effektive Kundenkommunikation aufbauen und gleichzeitig Zeit und Kosten sparen.
Abbildung 1: Conversational commerce
Fazit
Unternehmen sind gefordert, sich mit neuen Technologien auseinanderzusetzen und die ersten Schritte in Richtung konkreter Use Cases zu machen. Das Potenzial ist enorm, aber auch das Risiko, wenn sich Unternehmen dieser Trends nicht annehmen.
Der Autor Dominic Bolliger ist Co-Founder von DiALOGiFY, der Next-Level Conversational Cloud Software – Powered by ChatGPT. DiALOGiFY unterstützt Marken und Unternehmen dabei, kundenzentrierte Interaktionen entlang der Customer Journey einzusetzen.
In der Vergangenheit wurden Daten zum Reise- und Bewegungsverhalten der Bevölkerung häufig über Befragungen oder Tagebuchstudien erhoben. Aber das Vorgehen ist wenig effizient, für die Studienteilnehmenden oft aufwändig und die Genauigkeit der Angaben ist nicht immer hoch. So werden von den Studienteilnehmenden allenfalls zurückgelegte Wege oder Etappen nicht korrekt erinnert, verwechselt oder bewusst nicht angegeben.
intervista bietet eine technologisch fundierte Methodik, die nicht nur angenehmer für Studienteilnehmende, sondern auch effizienter und smarter ist: die kontinuierliche automatische Messung von Reise- und Bewegungsdaten durch Smartphone-basiertes Geolocation-Tracking. Diese passive Verhaltensmessung generiert dank des technischen Setups fortlaufend umfangreiche Datensets und bietet eine hohe Präzision. Gleichzeitig ermöglicht sie den Studienteilnehmenden die bessere Experience. Wie das konkret funktioniert, möchten wir kurz erklären.
Footprints Research: Methodik und Technologie
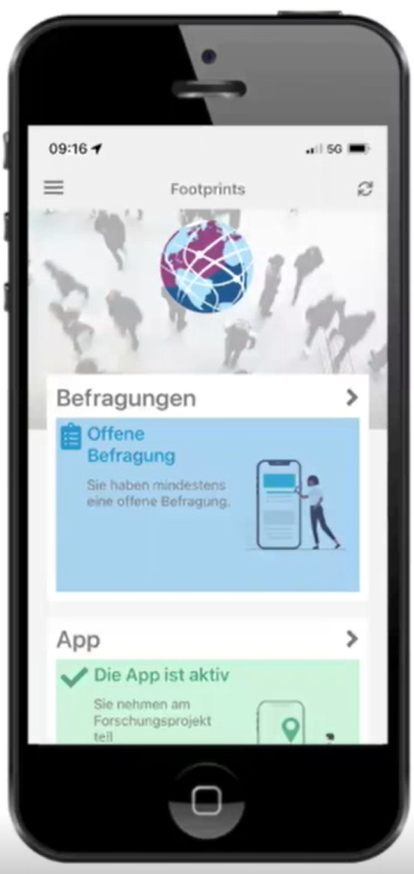
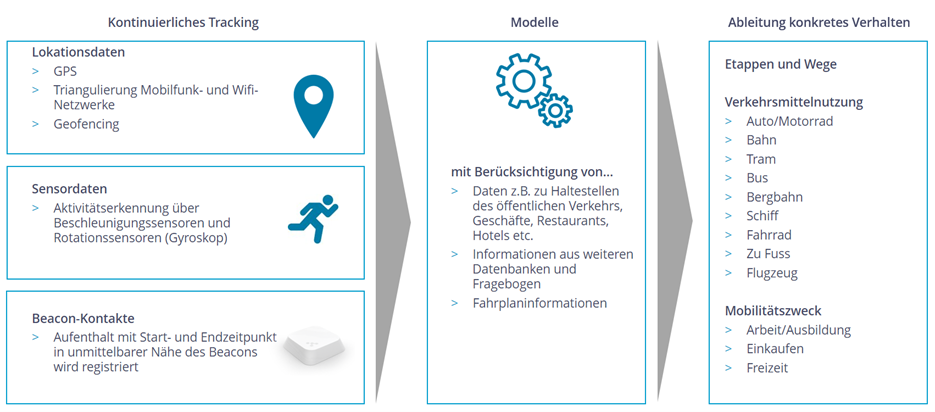
Im Kern des smarten Verfahrens steht die von intervista entwickelte Smartphone App «Footprints Research». Die App registriert kontinuierlich die Aufenthaltsorte, die Daten der Bewegungs- und Rotationssensoren des Gerätes sowie Kontakte mit Beacons.
Mit den Tracking-Daten wird mit Modellen konkretes Verhalten ermittelt wie zurückgelegte Etappen und Wege, die Verkehrsmittelnutzung, der Mobilitätszweck und Besuche von Points-of-Interest (z.B. Supermärkte, Museen, Sportstadien, Restaurants etc.).
Abbildung 1: Footprints Research App
Abbildung 2: Messtechnologie und Datenaufbereitung
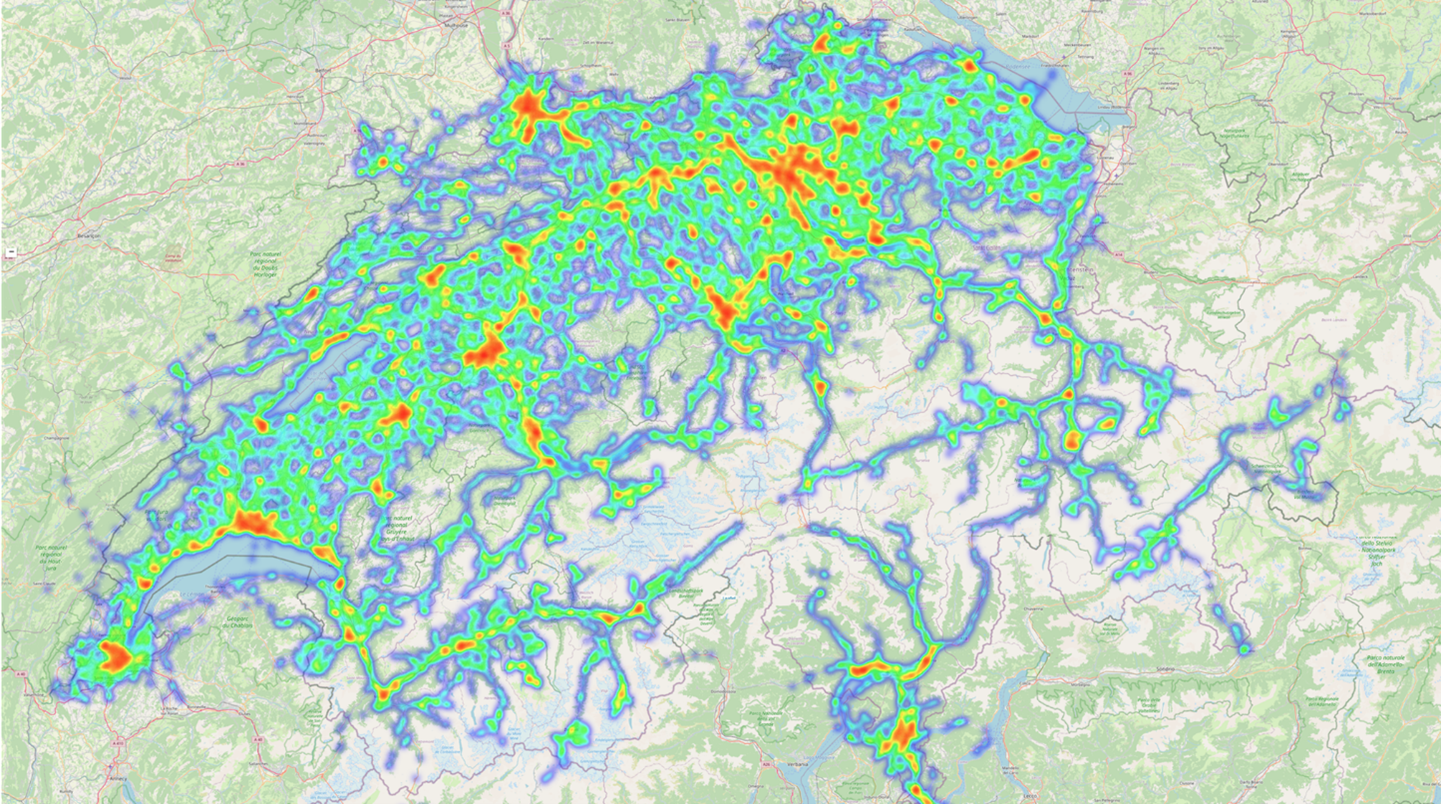
Im Herbst 2018 lancierte intervista das Footprints-Panel und sammelt seither kontinuierlich und vollautomatisch Mobilitätsdaten der teilnehmenden Panelistinnen und Panelisten. Aktuell erfasst das Footprints-Panel 3’000 Personen, diese wurden nach soziodemografischen Merkmalen entlang repräsentativer Vorgaben für die Schweizer Bevölkerung im Alter von 15 bis 79 Jahren aus dem intervista Online-Panel unter Einhaltung der geltenden Datenschutzgesetze (DSG und DSGVO) rekrutiert. Im Unterschied zu herkömmlichen Tagebuchstudien, die in der Regel nur einen kurzen Zeitraum umfassen, erfasst die App das Verhalten an 365 Tagen im Jahr, wodurch insgesamt ein Datenschatz von mehr als 1 Million Messtagen pro Jahr erhoben wird, der intervista für Analysen zur Verfügung steht.
Abbildung 3: Heatmap Mobilität in der Schweiz
Zu den Footprints-Panelistinnen und -Panelisten liegen umfassende Profilmerkmale vor (z.B. Alter, Geschlecht, Einkommen, Interessen), welche mit den Messdaten kombiniert werden können, um tiefergehende Analysen durchzuführen.
Über die App können Personen zudem zu Befragungen eingeladen werden. So können z.B. Personen eingeladen werden, wenn sie bestimmte Orte besucht haben oder ein bestimmtes Verhalten zeigen. Dies ermöglicht gehaltvollere Forschungsdesigns, welche beispielsweise auch Motive und Wahrnehmung beinhalten.
Zudem bietet die App eine ideale Experience für die Teilnehmenden, da sie nur eine einmalige, einfache Installation erfordert und einen geringen Akkuverbrauch aufweist.
Anders gesagt: Die Footprints-Panelistinnen und -Panelisten nehmen an einer Mobilitätsstudie teil, indem sie einfach zur Arbeit pendeln, einen Städtetrip unternehmen oder einkaufen – ohne im Hinterkopf behalten zu müssen, sich den Ablauf möglichst gut einzuprägen und selbständig zu dokumentieren. Damit revolutioniert intervista die Mobilitätsforschung und bringt sie auf das nächste Level, um den zunehmend komplexen Fragestellungen zur Mobilität auf Augenhöhe zu begegnen.
Die App von intervista ist zudem als White-Label-Lösung verfügbar. So hat intervista beispielsweise im Jahr 2022 für das Bundesamt für Statistik BFS die massgeschneiderte MVMZ-App (Mikrozensus Mobilität und Verkehr) konzipiert und programmiert.
Den Mehrwert der App-basierten passiven Messung möchten wir Ihnen am Beispiel einer intervista-Studie veranschaulichen, die 2021 mit dem renommierten «GOR Best Practice Award» für den erfolgreichen Einsatz modernster digitaler Forschungsmethoden ausgezeichnet worden ist.
Mobilitäts-Monitoring während der COVID-19-Pandemie
Im Auftrag des statistischen Amtes des Kantons Zürich, der Swiss National COVID-19 Science Task Force, des Bundesamtes für Statistik BFS und der Konjunkturstelle der ETH Zürich führten wir im Rahmen der COVID-19-Pandemie während 18 Monaten (Januar 2020 – Juli 2021) ein umfassendes Mobilitäts-Tracking der Schweizer Bevölkerung durch.
Dank der umfangreichen Datenerhebung durch das Footprints-Panel konnten wir verschiedene Entwicklungen anhand ausgewählter Kriterien detailliert aufzeigen. So konnte u.a. gesehen werden, ob und inwiefern sich Bevölkerungssegmente an verbindliche Vorgaben sowie Empfehlungen des Bundesrates hielten.
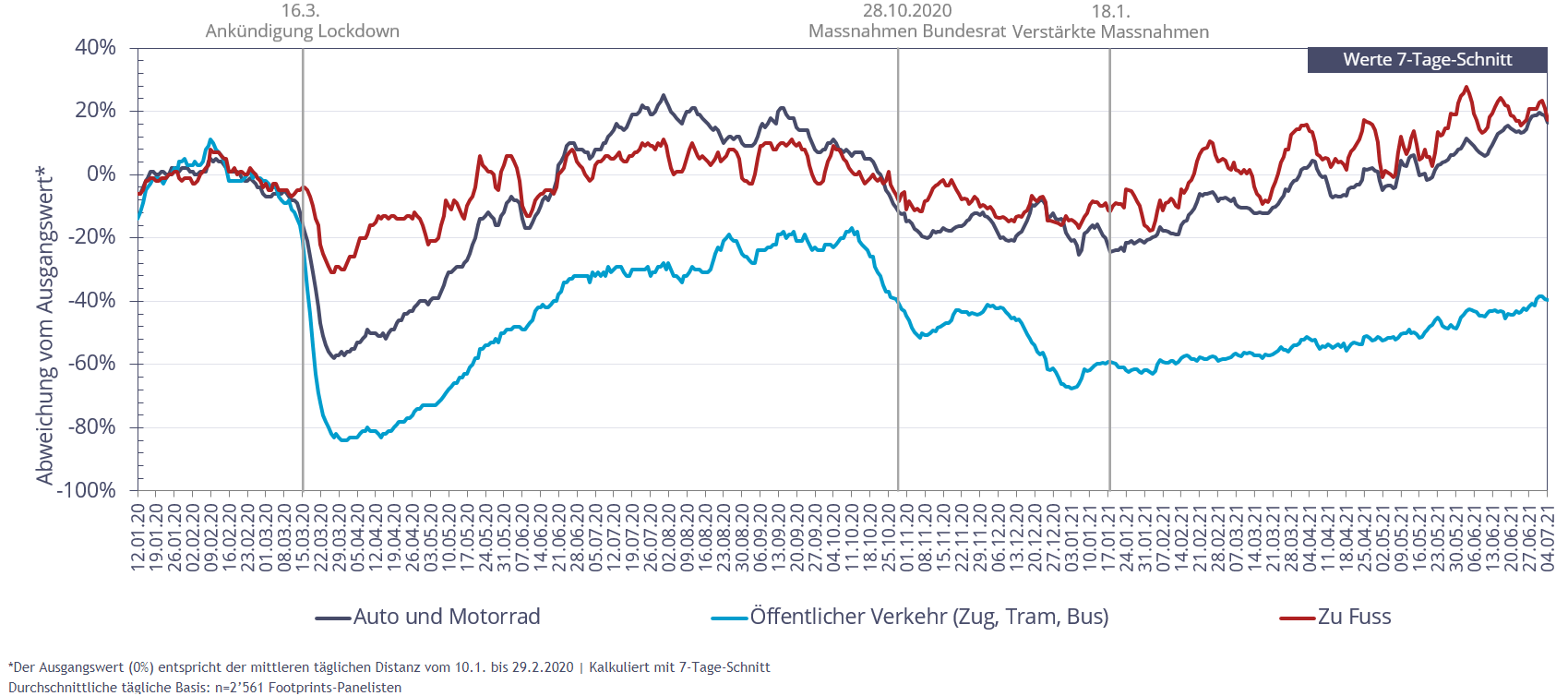
Während der COVID-19-Pandemie veränderte sich das Mobilitätsverhalten der Schweizer Bevölkerung massiv. Das Tracking ergab, dass die Bevölkerung ihr Mobilitätsverhalten – zu Fuss, mit privaten Fahrzeugen sowie dem öffentlichen Verkehr – nach Erklärung der ausserordentlichen Lage am 16. März 2020 deutlich einschränkte. Insbesondere die Nutzung öffentlicher Verkehrsmittel ist zu dem Zeitpunkt stark eingebrochen und hat sich in der Folge nur langsam erholt.
Abbildung 4: Relative Entwicklung der Verkehrsmittelnutzung
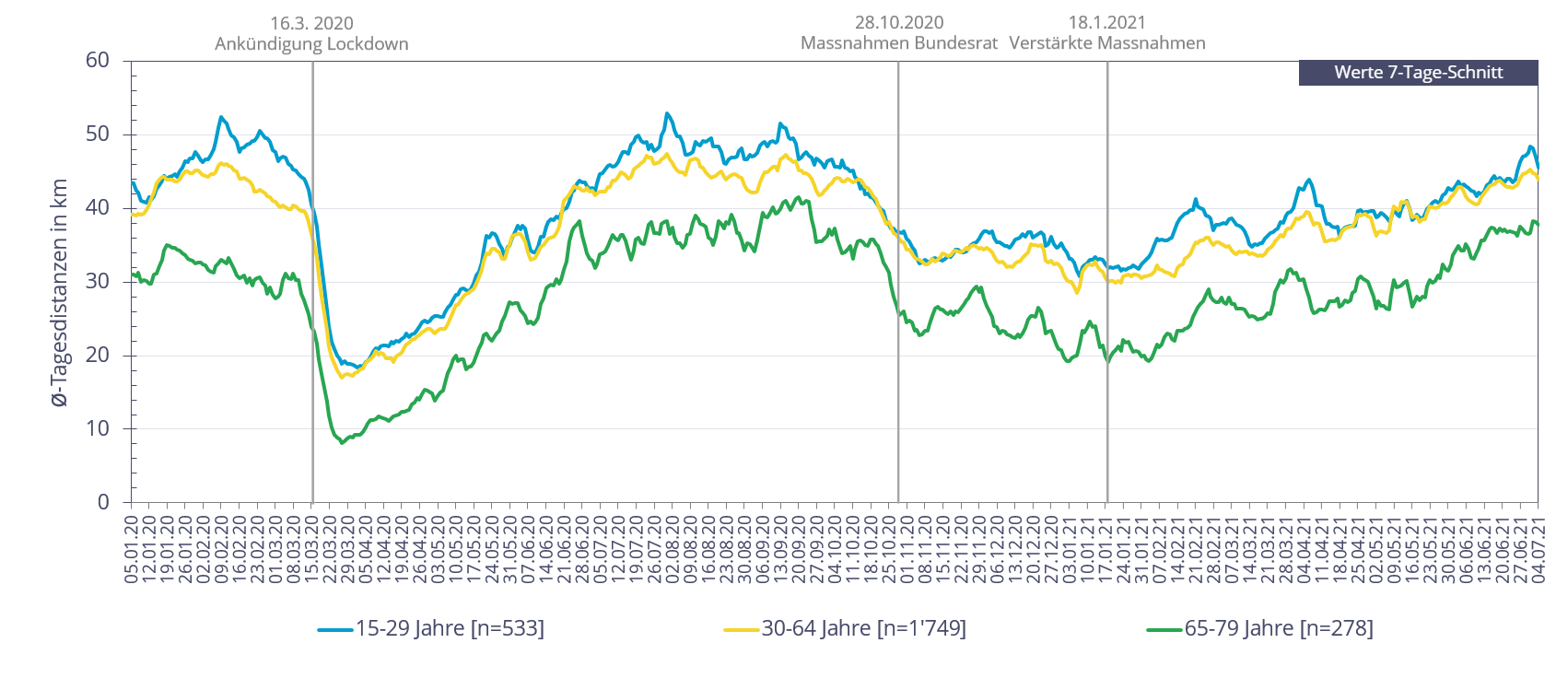
Segmentiert nach Altersklassen zeigten sich Parallelen in den Verhaltensanpassungen über alle Altersklassen hinweg. Damit liess sich nachweisen, dass sich auch jüngere Personen an die Anweisungen des Bundesrates hielten und ihr Mobilitätsverhalten anpassten.
Abbildung 5: Tagesdistanzen nach Alter
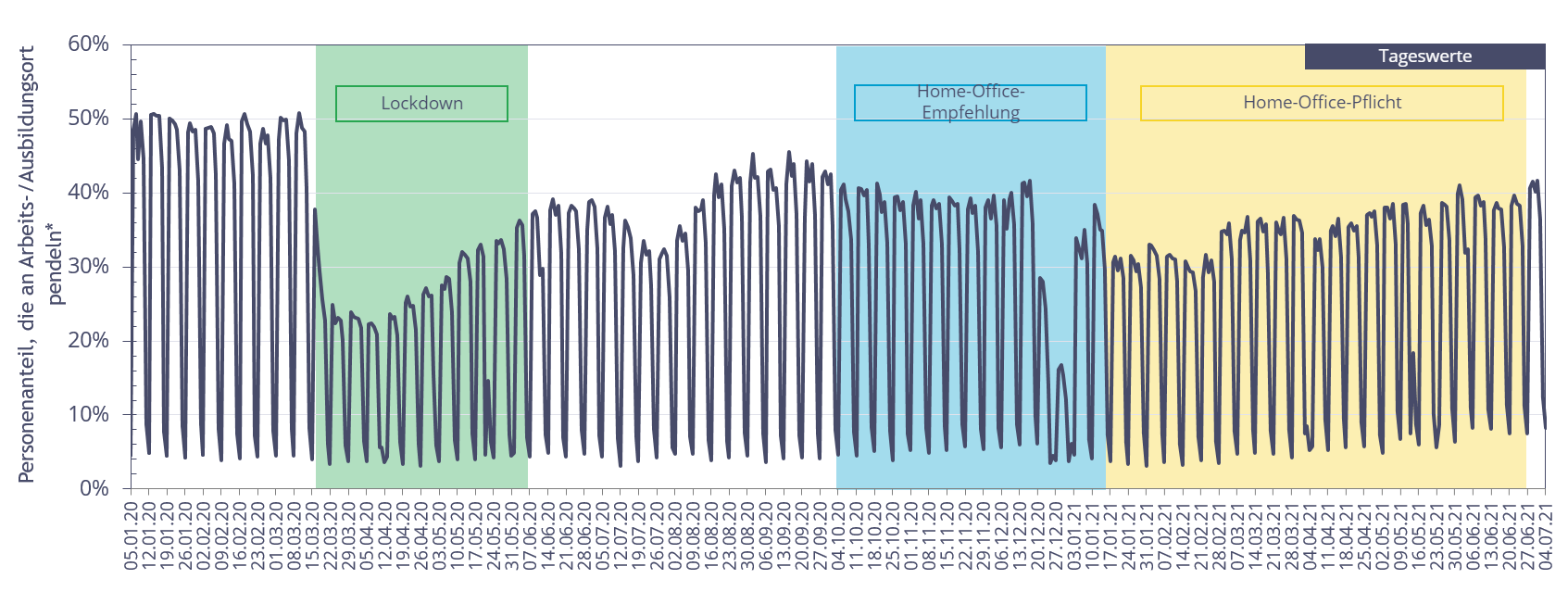
Ein weiteres Beispiel ist die Messung, wie sich die Homeoffice-Empfehlung bzw. die spätere Homeoffice-Pflicht auf das Verhalten von Pendlerinnen und Pendlern mit fixem Arbeits- oder Ausbildungsort auswirkte. So hatte z.B. die Homeoffice-Empfehlung im Oktober 2020 nur einen geringen Effekt auf das tatsächliche Pendlerverhalten.
Abbildung 6: Pendleranteile im Zeitverlauf
Die Daten aus dem Footprints-Panel lassen auch Analysen der interkantonalen Mobilität zu. Die Abbildung zeigt die Mobilitätsverbindungen zwischen den Kantonen. Je stärker die Linie ist, desto mehr Reisen gibt es zwischen den beiden Kantonen. Besonders starke Verbindungen sind z.B. zwischen den Kantonen Basel-Landschaft und Basel-Stadt sowie zwischen Zürich und Aargau zu sehen. Solche Daten sind auch bedeutend für die Analyse von Infektionsketten über Kantonsgrenzen hinweg.
Abbildung 7: Interkantonale Mobilität
Einsatzmöglichkeiten des smarten Mobilitäts-Trackings
Die Studie illustriert beispielhaft den Mehrwert dieser Methodik, welche Mobilitätsforschung mit modernster Technologie verbindet. Mit den umfangreichen Daten aus dem Footprints-Panel und der hohen Präzision der Messmethode können aber auch verschiedenste weitere Fragestellungen zuverlässig und detailliert bearbeitet werden.
So können u.a. die Reichweite und Wirkung von Aussenwerbung, das Pendlerverhalten in Zeiten von Online-Vorlesungen und Homeoffice als neuer Selbstverständlichkeit im «New Work», die Besucherstruktur von Destinationen oder Veranstaltungen, Passantenfrequenzen und auch Einkaufsroutinen untersucht werden. Mit der Möglichkeit, über die App zusätzlich Befragungen durchzuführen, können Befragungsdaten mit den Messdaten kombiniert und gemeinsam analysiert werden. Dies ermöglicht weitergehende Insights, welche beispielsweise Verhaltensmotive und die unmittelbare Wahrnehmung an bestimmten Orten umfassen.
Der Autor Beat Fischer ist Mitglied der Geschäftsleitung von intervista. Er ist spezialisiert auf digitale Forschungsmethoden und Experte für Mobilitäts- und Werbeforschung. Bei intervista ist er zudem für das Business Development sowie die Entwicklung digitaler Produkte verantwortlich.
Mangelnde Nachhaltigkeit bei der Herstellung von Produkten, sozial unverträgliche Arbeitsbedingungen entlang der Produktionsketten, unnötige Umverpackungen, Abbau von Arbeitsplätzen – all das hat Einfluss auf die Reputation und den guten Ruf eines Unternehmens. Dies umso mehr in einer Zeit, in der Unternehmen und auch Schweizer Non-Profit-Organisationen (NPOs) unter ständiger Beobachtung stehen: Sowohl in klassischen als auch in den sozialen Medien wird jegliches Fehlverhalten genau in Augenschein genommen und diskutiert. Im Gegenzug schlagen sich aber auch positive Entwicklungen z.B. im Rahmen eines besonderen Engagements für soziale oder ökologische Themen, entsprechend positiv in der Reputation nieder. Die verschiedenen Stakeholder:innen reden nicht nur darüber, sie handeln auch entsprechend: Als Konsumierende vermeiden sie Unternehmen mit zweifelhafter Reputation, als potenzielle Mitarbeitende wählen sie Unternehmen mit herausragender Reputation. Deshalb ist Reputationsmanagement nicht mit Krisenkommunikation gleichzusetzen, sondern sollte systematisch gepflegt werden. So wird zunehmend wichtig zu verstehen, wie die verschiedenen Stakeholder:innen über ein Unternehmen denken. Und zwar nicht nur in Zeiten der Krise, um reaktiv handeln zu können, sondern kontinuierlich, um ein systematisches Reputationsmanagement betreiben zu können.
Mit dem GfK Business Reflector das Thema Reputation stärker im Unternehmen verankern
Mit dem Business Reflector bietet GfK Unternehmen und Organisationen eine effiziente Möglichkeit, um herauszufinden, wie es um ihre Reputation bei der Schweizer Bevölkerung bestellt ist. Seit mehr als fünfzehn Jahren erfasst GfK einmal jährlich die Reputation der führenden Schweizer Unternehmen und seit sechs Jahren zudem die Reputation der bekanntesten Schweizer Non-Profit-Organisationen. Die Messung basiert auf einer repräsentativen Befragung der Schweizer Bevölkerung. Jeweils im Januar und Februar werden 3‘500 Personen zwischen 16 und 69 Jahren in der Deutsch- und Westschweiz mittels einer repräsentativen Online-Umfrage befragt. Das Ranking beruht demnach nicht auf einer Analyse von Performance-Daten, Medienberichten oder anderen Kennzahlen und Experteneinschätzungen, sondern allein auf der Meinung der Schweizer Bevölkerung. GfK erfasst für das jährliche Ranking eine Kerngruppe von Unternehmen, welche die bekanntesten Unternehmen, die 20 SMI-Titel sowie die grössten Schweizer Arbeitgeber:innen umfasst, sofern diese in der Bevölkerung hinreichend bekannt sind. Unternehmen, welche in der Bevölkerung nicht oder kaum bekannt sind, können von den teilnehmenden Personen auch nicht sinnvoll hinsichtlich ihrer Reputation beurteilt werden und werden ausgeschlossen. Daneben werden die 20 bekanntesten Schweizer Non-Profit-Organisationen in die Studie einbezogen. Weitere Unternehmen und Organisationen können sich ausserhalb des Rankings an der Studie beteiligen und sich so direkt mit den führenden Unternehmen und Organisationen der Schweiz vergleichen. Damit stellt der GfK Business Reflector für alle interessierten Unternehmen und Organisationen ein einzigartiges Reputationsbenchmarking zur Verfügung, das als Basis für das Reputationsmonitoring und Reputationsmanagement dient. Es zeigt auf, wo ein Unternehmen im Vergleich zu anderen führenden Unternehmen steht und wie sich die Reputation im Zeitverlauf verändert. Gemeinsam mit dem fög (Forschungsinstitut Öffentlichkeit und Gesellschaft), einem assoziierten Institut der Universität Zürich, wurde ein wissenschaftlich fundiertes Messinstrumentarium entwickelt, das die drei zentralen Reputationsdimensionen «rationale Wertschätzung», «emotionale Wertschätzung» und «sozialmoralische Wertschätzung» umfasst. Aus diesen drei Dimensionen wird ein Reputationsindex gebildet, der die zentrale Kennzahl für das GfK Business Reflector Ranking darstellt. Untersuchungen zeigen, dass insbesondere emotionale Faktoren wie die Sympathie eines Unternehmens zentral für eine gute Reputation sind. Können sich Personen mit einem Unternehmen identifizieren, wird auch die Reputation besser beurteilt. Dabei kommt der sozialmoralischen Verantwortlichkeit eine wesentliche Rolle zu. Die Bevölkerung interessiert sich – wie viele andere Anspruchsgruppen auch – immer stärker dafür, ob ein Unternehmen sich seiner gesellschaftlichen, ökonomischen und ökologischen Verantwortung bewusst ist. Themen wie Arbeitsplatzsicherung am Standort Schweiz, faire Lieferketten und attraktive Arbeitsbedingungen, Klimaschutz und verantwortungsbewusster Umgang mit natürlichen Ressourcen sind zentrale Aspekte, die von den Unternehmen erwartet werden.
Abbildung 1: 7 Dimensionen der Nachhaltigkeit
Für eine gute Reputation ist der verantwortungsbewusste Umgang mit natürlichen Ressourcen ein zentraler Faktor
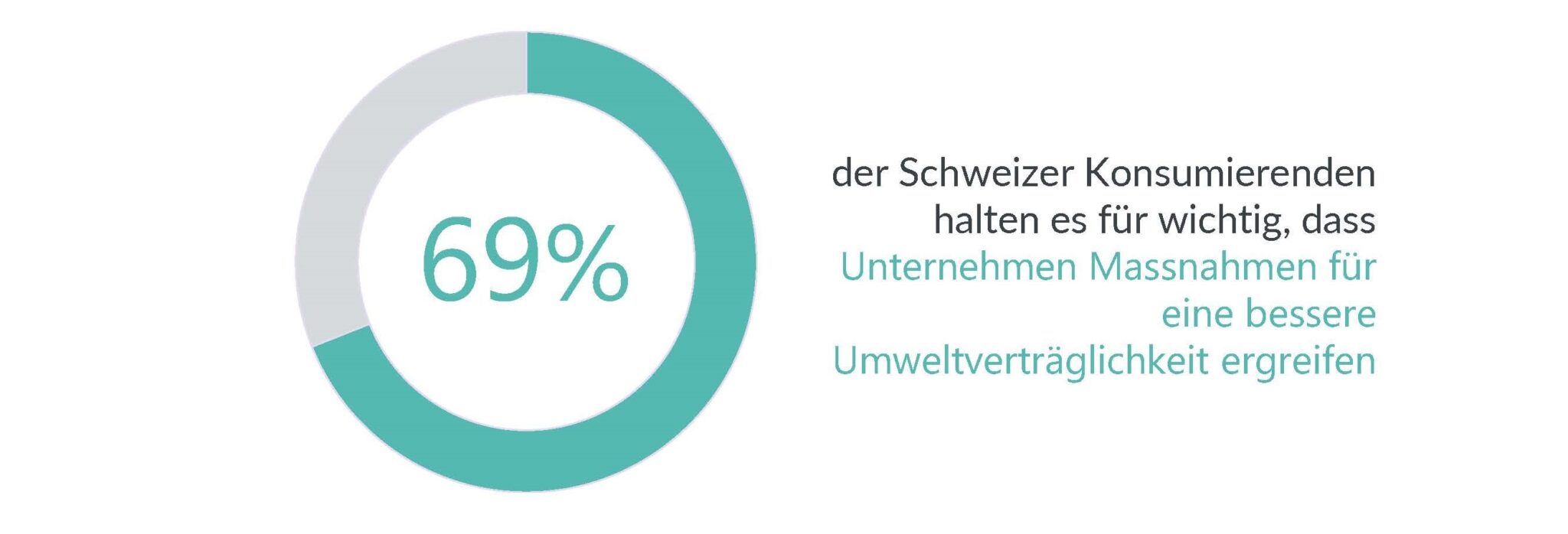
Wie wichtig das Thema Nachhaltigkeit ist, sieht man auch am Stellenwert in den persönlichen Werten. Seit über 25 Jahren misst GfK im Rahmen der GfK Consumer Life Studie die Wichtigkeit persönlicher Werte wie zum Beispiel den Schutz der Familie, Freundschaft, Ehrlichkeit oder materielle Sicherheit. Der Schutz der Umwelt gehört zu den wichtigsten zehn Werten der Schweizer Konsumierenden und ist inzwischen sogar wichtiger als Gesundheit und Fitness. Der Klimawandel ist die grösste Sorge der Schweizer:innen, noch vor Themen wie steigende Preise oder der Pandemie. Für fast 70 Prozent der Schweizer:innen ist der Klimawandel ein ernst zu nehmendes Problem.
Für eine gute Reputation ist der verantwortungsbewusste Umgang mit natürlichen Ressourcen ein zentraler Faktor
Doch Nachhaltigkeit umfasst nicht nur die ökologische Komponente, sondern auch ökonomische und soziale Aspekte. Themen wie soziale Verantwortung und soziale Toleranz wurden in den letzten Jahren wichtiger für die Menschen, nicht nur in der Schweiz. Ganz besonders wichtig sind für die junge Generation Z soziale Toleranz und Chancengleichheit für alle Menschen, unabhängig von Geschlecht oder Herkunft. Ereignisse wie der Brand der Textilfabrik in Bangladesch vor einigen Jahren oder die Berichterstattung in den Medien über die Arbeitsbedingungen in manchen Ländern machen stärker auf die sozialen Aspekte aufmerksam. Dadurch wird es immer wichtiger, wie und wo ein Produkt hergestellt wurde.
GfK Green Gauge® Segmen-tierung identifiziert verschiedene Anspruchsgruppen
Nicht alle Menschen ticken in Bezug auf Nachhaltigkeit gleich. Deshalb hat GfK eine Segmentierung entwickelt, die Menschen anhand ihrer Sorgen, Einstellungen und Aktivitäten rund um Nachhaltigkeit unterscheidet. Das grünste Segment sind die sogenannten Green inDeed. Diese Menschen sind aktiv in Bezug auf nachhaltiges Denken und Handeln. Sie recyceln, achten beim Einkauf auf Nachhaltigkeit, sparen Wasser und Strom und kaufen nur, was sie brauchen. Sie sind bereit, Aufwand für einen nachhaltigen Lebensstil in Kauf zu nehmen. Auch soziale Aspekte, wie soziale Toleranz, Hilfsbereitschaft oder Chancengleichheit sind ihnen sehr wichtig. Unternehmen müssen sowohl ökologisch als auch sozial nachhaltig handeln, um ihre Reputation in dieser Zielgruppe zu erhöhen. Eine sehr grosse Rolle spielt das Thema CO2-Neutralität, aber auch die Einhaltung ethischer Standards entlang der gesamten Wertschöpfungskette hat einen hohen Stellenwert. Darüber hinaus sollten Unternehmen kommunizieren, wie sie sich sozial engagieren. Die Glamour Green dagegen, die grösste Gruppe, sind Konsumentinnen und Konsumenten, für die Nachhaltigkeit auch ein Statement ist. Sie tragen coole grüne Labels, posten ihren nachhaltigen Lebensstil in den sozialen Medien und suchen Produkte, die Nachhaltigkeit und Status verbinden. Sie wollen auf nichts verzichten, Nachhaltigkeit muss zu ihrem Lebensstil passen. Nachhaltige Produkte sollen Abwechslung und Spass bringen. Sie kaufen häufiger Markenprodukte und achten auf Convenience- und Ökolabel. Diese Zielgruppe erwartet von Unternehmen neben der Übernahme von Verantwortung für die Umwelt vergleichsweise häufig, dass sie Programme implementieren, die soziale Fragen adressieren, die lokale Gemeinschaft unterstützen oder in die Ausbildung der Mitarbeitenden investieren.
Abbildung 2: GfK Green Gauge®
Konsumentinnen und Konsumenten erwarten von Unternehmen, dass sie die Weichen für nachhaltiges Verhalten stellen
och auch wenn Nachhaltigkeit in den Werten und Einstellungen der Konsumierenden eine grosse Rolle spielt, fällt es den Menschen nicht immer leicht, auch selbst entsprechend zu handeln. Das hat verschiedene Gründe. So sind nachhaltige Produkte oft teurer als herkömmliche, oder es fehlt an Wissen, welche Produkte wirklich nachhaltig sind. Einige Menschen sind unsicher, ob nachhaltige Produkte tatsächlich genauso gut sind wie andere Produkte. Andere bezweifeln, ob sie als Individuum wirklich etwas bewirken können. Deshalb wird vor allem von Unternehmen nachhaltiges Handeln erwartet. Insbesondere bei der Herstellung von Produkten sollten Unternehmen auf Nachhaltigkeit achten, indem sie beispielsweise umweltfreundlich produzieren, erneuerbare Energien nutzen, umweltfreundliche Inhaltstoffe und Verpackungsmaterialien verwenden, lange Transportwege reduzieren und soziale Aspekte wie die faire Bezahlung aller Mitarbeitenden berücksichtigen.
Unternehmen sollten verstehen, welche Rolle Nachhaltigkeit in ihrer Branche spielt
Nur wenige Unternehmen konnten sich schon erfolgreich nachhaltig positionieren, wie eine europäische GfK-Studie zeigt: 19 Prozent der Konsumentinnen und Konsumenten können eine Marke nennen, die umweltfreundlich ist. Die FMCG-Industrie wird in puncto Nachhaltigkeit vergleichsweise gut bewertet, während bei Reisen, Smartphones oder Autos noch Nachholbedarf besteht. Frühzeitiges Handeln hilft, sich hier einen Reputationsvorsprung zu erarbeiten und sich einen langfristigen Vorteil im Wettbewerb zu verschaffen.
Das Wissen um die verschiedenen Nachhaltigkeitssegmente wird im GfK Business Reflector integriert
In diesem Jahr ist die Green Gauge® Segmentierung Teil der GfK Business Reflector Studie. Teilnehmende Unternehmen können so genau sehen, wie die unterschiedlichen Zielgruppen ihr Unternehmen im Vergleich zu den führenden Unternehmen in Bezug auf die verschiedensten Reputationsaspekte beurteilen. So können sie ganz gezielt auf die Anforderungen und Bedürfnisse der relevanten Zielgruppen eingehen und ihr Reputationsmanagement optimieren. Eine Steigerung der Reputation erfordert zwar Anstrengungen und Investitionen in vielen Bereichen des Unternehmens, wird aber langfristig mit treuen Konsumierenden sowie zufriedenen Mitarbeitenden belohnt.
Abbildung: Erwartungen von Konsumierenden an Unternehmen
Die Spannung steigt!
Nur noch wenige Wochen bis zur diesjährigen Awardverleihung des GfK Business Reflector und der Veröffentlichung des Swiss Reputation Rankings. Wir freuen uns auf die Verkündung der Gewinner am 28. März in Zürich! Möchten Sie live dabei sein, wenn wir die Gewinner:innen prämieren? Neben der Awardverleihung können Sie sich auf zwei spannende Referate zum Thema Nachhaltigkeit freuen! Die Teilnahme ist kostenlos. Die Teilnehmerzahl ist beschränkt. -> zur Anmeldung
Möchten Sie sich in der Zwischenzeit vertieft mit den Themen Reputation und Nachhaltigkeit beschäftigen? In unserem Podcast geben wir noch mehr Insights über die Segmente Glamour Green oder Green inDeed aus unserem GfK Green Gauge® Report. Auch kommen die letztjährigen Preisträger:innen zu Wort. Hier können Sie die Episode nachhören.
Dr. Anja Reimer
Client Business Partner und Studienleiterin GfK Business Reflector
Wir freuen uns, Ihnen den Swiss Insights Report 2022 der Swiss Data Insights Association vorstellen zu dürfen.
Der Launch des Data Fairness Label hat die Verbands-Transformation einen beträchtlichen Schritt weiter gebracht. Damit einhergehend konnte mit dem Aufbau der Data Fairness Community ein Pendent zur Roundtable Konferenz der Institute aufgebaut werden. Sowohl für die Data Science, wie auch für die klassische Marktforschung gibt es nun ein Gefäss, in dem sich die Unternehmen themenspezifisch austauschen und die Branche weiterentwickeln können.
Diese Vielseitigkeit findet sich auch in den Artikeln im Swiss Insights Reports 2022 wieder. Er bietet einen breit gefächerten Überblick über den Markt und zeigt auf, in welche Richtung sich die Branche entwickelt.
Im letzten Drittel finden Sie eine Übersicht aller Member, einige stellen darin ihre Dienstleistungen ausführlich vor.
In einer Welt, in der sich die Technologien ständig weiterentwickeln, ist es für Unternehmen umso wichtiger, mit den neusten Trends Schritt zu halten. Der Begriff «Marketing 5.0» wurde vor kurzem von Kotler et al. (2021) geprägt und bezieht sich auf die jüngste Evolution des Marketings, bei der die ständige, vernetzte Nutzung von Daten und Technologien im Vordergrund steht, um gezieltere, relevante Kundenerfahrungen zu schaffen. Das Ziel von Marketing 5.0 ist es, Kunden die passende Botschaft zum richtigen Zeitpunkt über den entsprechenden Kanal zukommen zu lassen.
Marketing 5.0 bietet mehrere Vorteile, darunter ein tieferes Kundenverständnis, eine verstärkte Kundeneinbindung, eine gesteigerte Kapitalrendite (ROI) und einen erhöhten Kundenertragswert. Kurz auf den Punkt gebracht: Der wesentliche Nutzen von Marketing 5.0 besteht darin, den Marketern zu ermöglichen, die potenziellen Konsumenten umfassender zu verstehen und deren Bedürfnisse angemessener anzusprechen. Mithilfe KI-basierter Insights können Marketer zielgerichtete Kampagnen erstellen, die bei den Konsumenten besser ankommen und ein nachhaltiges Unternehmenswachstum fördern. Darüber hinaus macht der standardmässige Einsatz von Automatisierung das Marketing effizienter und effektiver.
Kotler et al. (2021) verstehen Marketing 5.0 als «the application of human-mimicking technologies to create, communicate, deliver, and enhance value across the customer journey» (Kotler et al., 2021, p. 6). Marketing selbst ist dabei von Natur aus ein sozialer Unternehmensansatz und fokussiert in erster Linie darauf, die Gedanken und Gefühle im Kopf und im Herzen der verschiedenen Anspruchsgruppen zu verstehen, um diese wiederum gezielt anzusprechen.
Mit anderen Worten: Marketing ist eine spezifische Art des Managements, um ein Unternehmen vom Markt her- und zum Markt hinzuführen. Dies bedeutet im Kern, dass die Bedürfnisse des Marktes bekannt sein müssen, um auf sie entsprechend eingehen zu können. Sowohl ein ganzheitliches Informations- als auch ein Aktionsmanagement sind notwendige Voraussetzungen, um diese Marketingherausforderung zu bewältigen.
Marketing 5.0 besteht aus drei operativen, miteinander verknüpften Kernkomponenten, nämlich Predictive Marketing, Contextual Marketing und Augmented Marketing sowie zwei organisatorischen Komponenten, genauer Data-Driven Marketing und Agile Marketing. Die beiden organisatorischen Marketing-Technologiekomponenten bilden die Basis für ein systematisches Informationsmanagement, z.B. zum Aufbau eines umfassenden Daten-Ökosystems. Die drei operativen Komponenten erlauben ein wirksames Aktionsmanagement, z. B. zur Erstellung relevanter Marketinginhalte wie Markenslogans, Produktbeschreibungen oder Kampagnen-bilder. Jede Komponente hat dabei einen unmittelbaren Bezug zur Marketingforschung, wobei die beiden organisatorischen Komponenten als Input-Pipeline für Insights und die drei operativen Komponenten als Output-Pipeline für Insights fungieren.
Vor diesem Hintergrund zeigt der nächste Abschnitt die Möglichkeiten fortschrittlicher Technologien der modernen Marketingforschung für eine tragfähige Marketing 5.0-Implementierung auf, im Folgenden als Marketing Insights 5.0 bezeichnet. Als Fallbeispiel für diese Demonstration dient die Vermarktung von Olivenöl des Start-ups JON’S OILIVE
Abbildung 1: Beispielhafte Ergebnisse der Predictive-Marketing-Intelligence-Komponente.
Erstellung von Marketing-Insights-5.0-Inhalten für das Start-Up JON’S OILIVE – eine Fallstudie
Das datengesteuerte Attributionsmodell von Google Analytics wurde als eine der Input-Pipelines verwendet, um zu evaluieren, wie potenzielle Kunden auf die verschiedenen über Google Ads eingeblendeten Anzeigen reagiert haben, mit dem Ziel, zu erkennen, welche Keywords etc. den größten Einfluss auf den Geschäftserfolg hatten und aus Nutzer Kunden werden liessen. Des Weiteren wurde die Konversionsleistung über die verschiedenen Marketing-Touchpoints (Website, soziale Medien usw.) bewertet. Zudem wurden mit Hilfe der agilen Insights-Plattform von quantilope potenzielle und reale Kunden befragt, um implizite markenbezogene Daten (Methode: Single Association Test) zur Stärkung der Markenpositionierung sowie produktbezogene Daten (Methode: Maximum Difference Scaling) zur Ermittlung der Konsumentenpräferenzen für Olivenöl-Produkteigenschaften zu erheben. Im Speziellen wurden dabei Attribute aus der KI-Entdecker-Funktion der KI-basierten SaaS-Lösung neuroflash gezogen und als Input für die Präferenzanalyse als eine Art Vorab-Erkennungs-Intelligenz (prädiktive semantische Analyse) verwendet.
In einem nächsten Erkenntnisschritt mit Blick auf die Predictive Marketing Intelligence wurde eine TURF-Analyse (Total Unduplicated Reach and Frequency) auf der agilen Plattform von quantilope durchgeführt, um die beste Kombination von olivenölbezogenen Produkteigenschaften zu identifizieren. Als Ergebnis wurde eine optimale Kombination von vier Produkteigenschaften ermittelt (in diesem Fall: frisch, regional, authentisch und fein), die etwas mehr als 80 % der (potenziellen) Konsumenten anspricht.
Darüber hinaus wurde Causal Artificial Intelligence (Causal AI) mittels der Software Neusrel auf die impliziten Markenwahrnehmungs- und Verhaltensdaten angewendet, um eine optimale archetypenbezogene Markenpositionierung abzuleiten. Auf diesem evidenzbasierten Weg wurde ein wirkungsvoller Interaktionseffekt auf das Konsumentenverhalten zwischen den Archetypen des Entdeckers und des Rebellen aufgedeckt und als optimale Markenpositionierung definiert. Abbildung 1 zeigt ausgewählte Ergebnisse dieser Predictive-Marketing-Intelligence-Komponente.
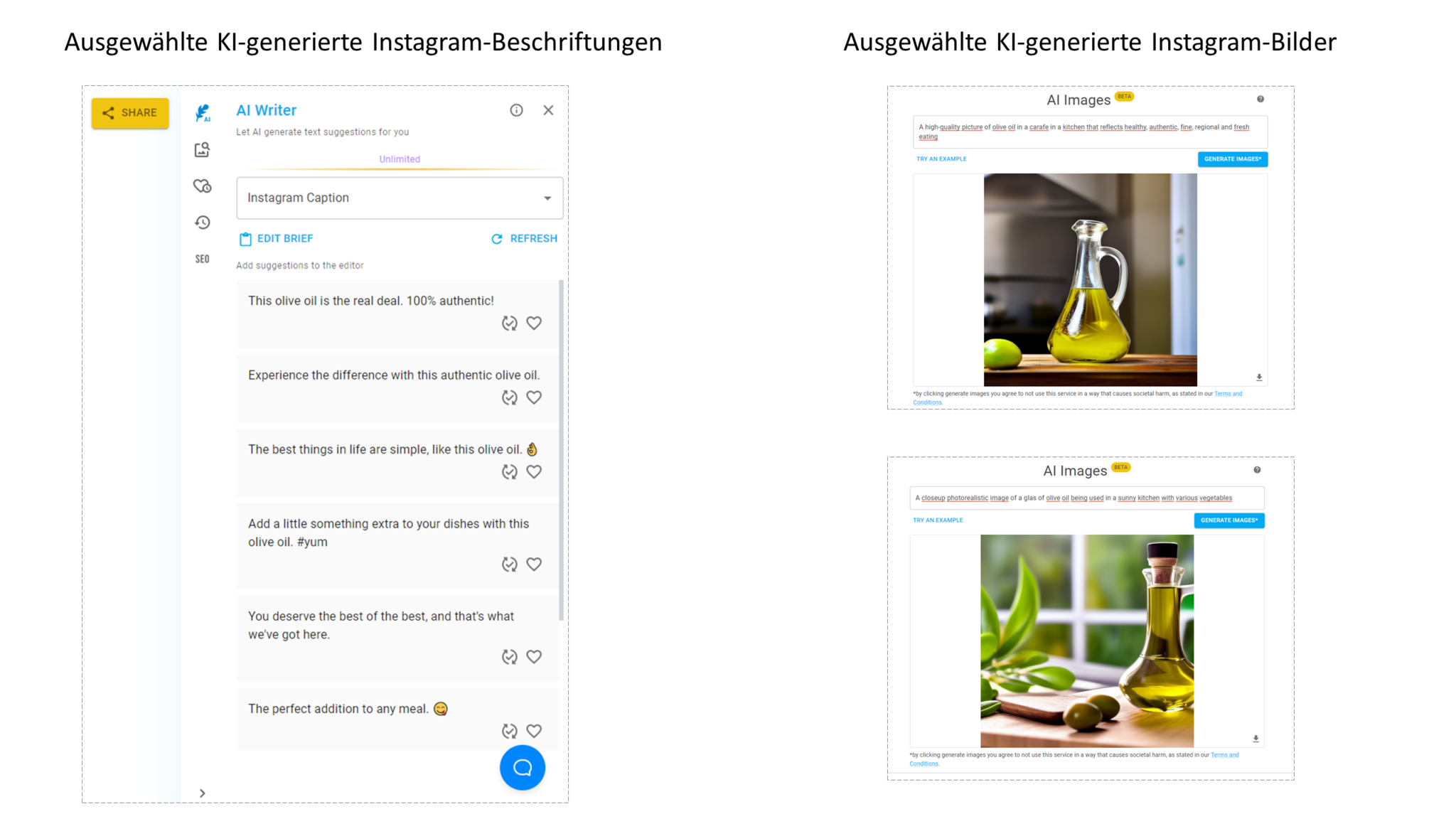
Im Rahmen der nächsten operativen Komponente, der Stufe der Contextual Intelligence Insights, wurden mit der KI-Texter- und KI-Bilder-Funktion von neuroflash automatisch Bildbeschriftungen sowie Bilder für einen wirksamen Sponsored Post auf Instagram als einem der wichtigsten Touchpoints und damit Kontextkanäle generiert. Als Input für diesen KI-basierten Kreativitätsansatz dienten die identifizierten wirksamen Produkt- und Markeneigenschaften, um die entsprechenden textlichen und visuellen Inhalte zu generieren.
Abbildung 2: Beispielhafte Ergebnisse der Contextual-Marketing-Intelligence-Komponente.
Eine beispielhafte Generierung gezielter kundenbezogener Inhalte, wie sie in Abbildung 2 zu sehen ist, erfolgt innerhalb weniger Sekunden. Jedes von der KI generierte Marketinggut (Asset), sowohl kurze und lange Texte als auch visuelle Inhalte, ist einzigartig; d. h. die KI ist darauf trainiert, keine bereits zuvor veröffentlichten Marketinggüter zu erstellen.
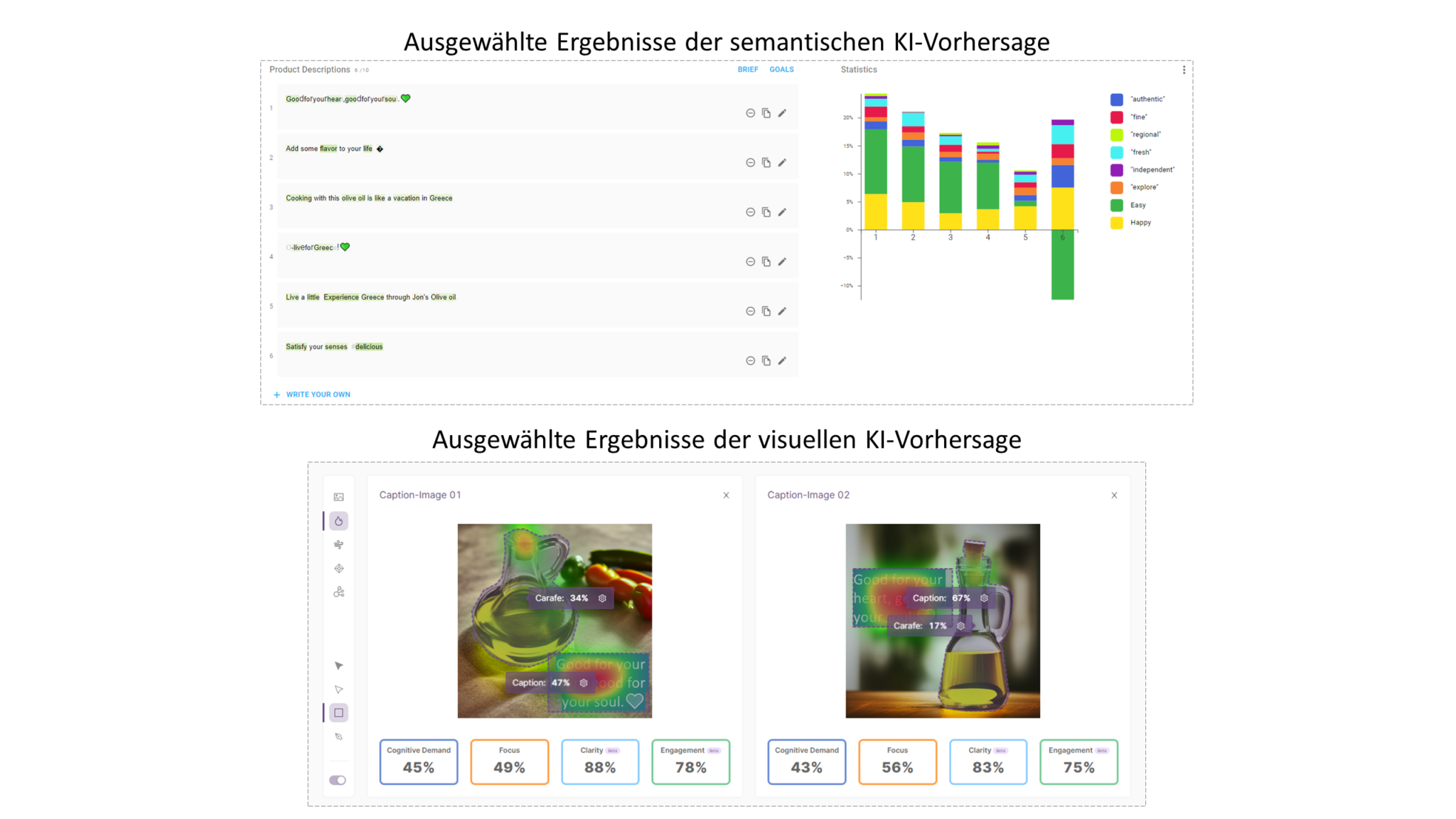
Im dritten und letzten operativen Schritt, der Stufe der Augmented Intelligence Insights, werden die generierten textlichen und visuellen Inhalte hinsichtlich a) der semantischen und b) der visuellen Wirksamkeit beurteilt, mit der Option, auch c) die verhaltensbezogene Leistungsfähigkeit zu bewerten. Beispielhafte Ergebnisse sind in Abbildung 3 dargestellt.
Abbildung 3: Beispielhafte Ergebnisse der Augmented-Marketing-Intelligence-Komponente.
Für die semantische Leistungsbewertung wurde wiederum das Tool neuroflash, genauer deren KI-Tester-Funktion verwendet, um vorherzusagen, was der Konsument auf einer impliziten Ebene in Bezug auf die als wirksam definierten Produkt- und Markeneigenschaften wahrscheinlich fühlen und denken wird, wenn er die textlichen Inhalte, in diesem Fall die generierten Bildunterschriften und Bildbeschriftungen, zu sehen bekommt. Darüber hinaus wurde die KI-Lösung Everypixel eingesetzt, um die Ahttps://www.neuronsinc.com/ttraktivität der visuellen Inhalte, hier also der generierten Bilder, zu analysieren, aber auch, um zu sehen, welche Assoziationen nach dem Kontakt mit dem jeweiligen Bild im Kopf des Konsumenten wahrscheinlich aktiviert werden.
Nachdem die besten Bildunterschriften und die beiden besten Bilder ermittelt worden waren, wurde die visuelle Wahrnehmungsqualität der Bildbeschriftung-Bild-Kombinationen bewertet. Die KI-Lösung Predict von Neurons wurde eingesetzt, um vorherzusagen, was die Konsumenten wahrscheinlich wahrnehmen werden, wenn sie die einzelnen Bildbeschriftung-Bilder-Inhalte anschauen, um sicherzustellen, dass die richtigen Hinweisreize ausreichend Aufmerksamkeit erhalten. Darüber hinaus wurde der Umfang der kognitiven Anforderungen vorhergesagt, um sicherzustellen, dass der Konsument während des Kontakts mit dem Sponsored Post nicht zu viele Informationen verarbeiten muss. Ebenfalls ist der Grad der Fokussierung geschätzt worden, um so zu gewährleisten, dass nicht zu viele Elemente auf dem Sponsored Post ein erhöhtes Ausmass an Aufmerksamkeit erfahren, was andernfalls zu einem abgelenkteren und damit weniger effizienten Wahrnehmungskontakt führen würde.
Die jüngsten Fortschritte ermöglichen nun auch die genaue Vorhersage von tiefer gehenden kognitiven und emotionalen Reaktionen. Insbesondere lässt sich jetzt der Grad der Klarheit vorhersagen. Dieser gibt an, ob ein Konsument den Inhalt als übersichtlich wahrnimmt oder nicht sowie den Grad des Engagements, der Aufschluss darüber gibt, wie angeregt und eingetaucht sich ein Konsument bei der Betrachtung des Inhalts fühlen wird (siehe Abbildung 3).
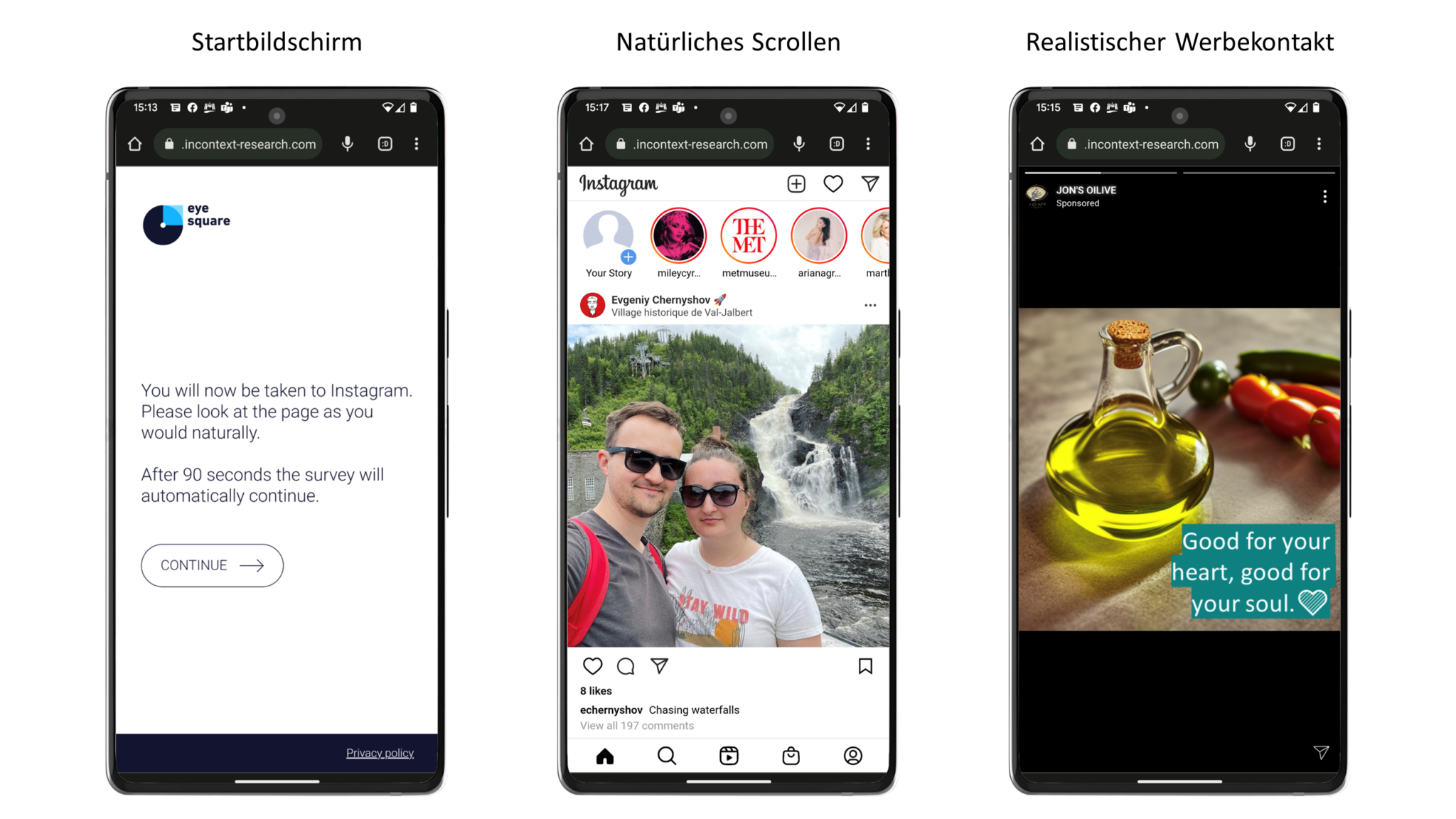
In diesem dritten Schritt wäre es zusätzlich möglich, die von der KI erstellten Texte und Bilder in einer realen digitalen Umgebung (noch) genauer zu testen, z. B. in sozialen Medien, in diesem Fall auf Instagram, um eine umfassendere Wahrnehmungs-, aber auch Verhaltenswirkung mithilfe des In-Context-Testansatzes von eye square zu ermitteln. Dieser Ansatz ermöglicht es insbesondere, die digitale Reise des Konsumenten (teilweise) zu simulieren, um die Auswirkungen einer bestimmten Marketingaktivität wie Werbung in sozialen Medien und/oder auf E-Commerce-Plattformen zu bewerten. Für diese Art der Untersuchung werden echte Konsumenten eingeladen und angehalten, eine bestimmte Website zu besuchen. Während des Besuchs der Website werden automatisch verschiedene Wahrnehmungs- (z. B. Betrachtungsdauer) und Verhaltenskennzahlen (z. B. Pausieren der Anzeige) aufgezeichnet, um Erkenntnisse für mögliche Verbesserungen zu gewinnen. Abbildung 4 veranschaulicht den Prozess und die Umsetzung dieses Ansatzes.
Die inhaltliche Optimierung mittels Marketing Insights 5.0 wurde für alle relevanten Social-Media-Touchpoints, aber auch für die Website einschliesslich des Online-Shops von JON’S OILIVE durchgeführt. Die Überprüfung der Konversionsleistung nach drei Monaten hat aufzeigen können, dass zum Beispiel in Bezug auf die Website die Impression Rate um etwa 300 % gestiegen ist, während sich die Click-Through-Rate fast verdoppelt hat. Derartige Ergebnisse zeigen eindrucksvoll das ausgezeichnete Potenzial des verwendeten Marketing-Insights-5.0-Ansatzes.
Abbildung 4: Veranschaulichung des Prozesses und der Umsetzung des In-Context-Testansatzes.
Marketers befähigen, ihre Marketingaktionen zu beschleunigen
Wie aufgezeigt werden konnte, ermöglicht Marketing Insights 5.0 hochpräzise Vorhersagen über die Marketingleistungsfähigkeit, z. B. die Wirksamkeit der Kommunikation, vom Strategie-Fit (bspw. optimale Markenpositionierung) bis hin zu Konsumentenreaktionen (bspw. was beim Werbekontakt wahrgenommen wird oder ob der Slogan die richtigen Markenassoziationen auslöst), um die mentale Verfügbarkeit im Markengedächtnis der Konsumenten nach Sharp (2010) zu erhöhen/zu stärken. Dieser Ansatz kann entweder allein auf KI-generierten Erkenntnissen beruhen oder durch gezielte Konsumentenbefragungen erweitert werden.
Im Detail wird ein erhöhter Erkenntniswert entlang des gesamten Marketing-Intelligence-Prozesses geschaffen. Dieser reicht von der Diagnose (bspw. tiefes Wissen über die Marke in den Köpfen der Kunden gewinnen, um die Markenstrategie zu definieren), über die Therapie (bspw. die Wirkung der Markenkommunikation im Einklang mit der Markenstrategie maximieren), die Überwachung (bspw. die Effektivität der Markenkommunikation ständig überprüfen, um sie mit der Markenstrategie abzugleichen) bis hin zur Inspiration (bspw. auf KI-gesteuerte Empfehlungen bezüglich Slogans oder Produktbeschreibungen zurückgreifen, die zur Markenstrategie passen). Auf diese Weise wird die Entscheidungsfindung in jeder Phase des Marketing-Intelligence-Prozesses nachhaltig gefördert. In einer sich rasant digitalisierenden Welt ist es für Unternehmen wichtiger denn je, eine Marketingeinstellung zu pflegen, welche die neuesten Veränderungen in Technologie und Konsumentenverhalten berücksichtigt. Marketing Insights 5.0 ist ein Ansatz, der dies ermöglicht und mit fortschrittlichen KI-basierten Tools und Technologien relevante und attraktive Konsumentenerlebnisse schafft. Um erfolgreich zu sein, erfordert dieser Ansatz jedoch nicht nur eine datengestützte, sondern vor allem die richtige agile und evidenz-basierte Marketing-Mentalität.
Eine Bürgerin sucht nach Daten der öffentlichen Statistik in der Schweiz: Die Wahrscheinlichkeit ist hoch, dass damit eine digitale Odyssee beginnt, statt, dass die Suche nach einer kurzen Suchmaschinenanfrage endet. Denn selbst für erfahrene Recherchierende ist es nicht immer leicht, Daten zu finden: Befinden sich die gesuchten Daten vertikal auf Ebene Bund, Kantone oder Gemeinden? Und welche Behörde oder welches Amt stellt innerhalb einer Ebene die Daten bereit? Die Suchmaschinen haben Mühe, die gesuchten Informationen zu indizieren, da sie sich in verschiedenen Applikationen oder sogar Dokumenten befinden. So klicken sich die Bürger durch, bis sie die gewünschten Informationen erhalten – oder bis sie die zuständige Stelle gefunden haben, bei der sie ihre Anfrage platzieren können.
Machine learning to the rescue?
Können wir nicht einen Algorithmus trainieren, uns die richtigen Antworten auf unsere Fragen zu liefern? Ist es nicht genau das, was Google und Co. machen und nicht immer schaffen? Unsere Schlussfolgerung ist: Wenn die Daten nicht «richtig aufbereitet» sind, dann fehlen die Grundlagen für die Anwendung eines fortgeschrittenen Algorithmus.
Die benötigten Daten der Schweizer Behörden stehen qualitativ hochwertig zur Verfügung. Trotzdem ist es nahezu unmöglich, einen Algorithmus im Umgang mit diesen Daten so zu trainieren, dass er die Frage «was ist der Anteil der registrierten Elektroautos im Kanton Zürich» korrekt beantwortet.
Das seit längerer Zeit bekannte Problem von maschinell nicht lesbaren Datenformaten wie Excel oder PDF spielt dabei nur eine kleine Rolle. Vor allem fehlt es in der Schweiz an einheitlichen Ansätzen für Datenstrukturen; nicht nur zwischen den verschiedenen Datenproduzenten, sondern sogar innerhalb deren jeweiligen Datenportalen. Die Probleme sind:
Qualität (wahr und nicht suggestiv)
Ohne menschliches Zutun sind zeitliche Elemente, räumliche Elemente, Dimensionen und Attribute nicht identifizierbar.
Die Daten sind uneinheitlich sowohl im «Long-Format» wie auch im «Wide-Format» –
zusätzlich findet man manchmal sogar Kreuztabellen oder gar Listen.
Es fehlt eine Standardisierung der verwendeten Codes und Labels.
Die Definitionen der relevanten Daten sind nicht in jedem Fall harmonisiert – beispielsweise errechnen Bund, Kantone und Gemeinden die Bevölkerungszahlen der Stadt Zürich leicht unterschiedlich.
Spalten gleicher Datenkategorien sind unterschiedlich benannt
Als Konsequenz dieser unterschiedlichen Datenstrukturen ist der Bau jeglicher datensatzübergreifenden Applikation mit beträchtlichem Aufwand verbunden – unabhängig davon, ob es sich um eine High End Machine-Learning-Lösung oder um ein simples Indikatorenportal handelt. Selbst wenn nur die Daten aus einem einzigen Datenportal eingelesen werden, kann die Menge der eingelesenen Datasets nicht beliebig vergrössert werden, da man für jedes Dataset einen separaten Code schreiben muss.
Standards and data harmonization to the rescue!
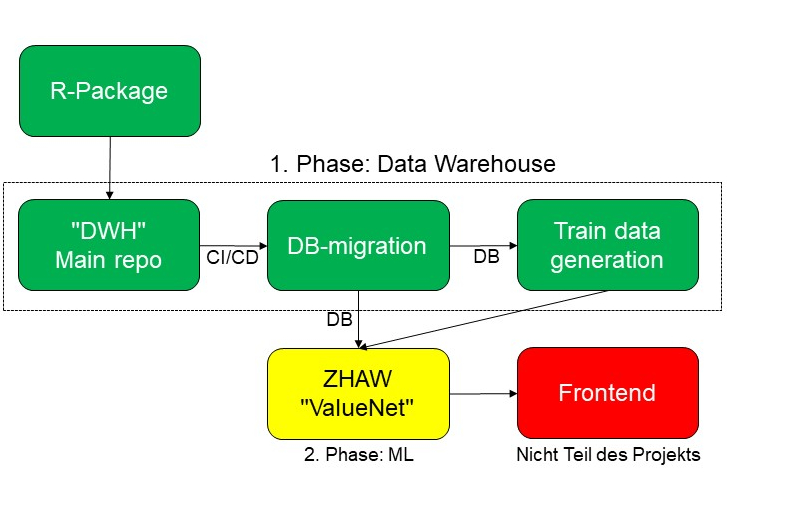
Hier setzen wir mit dem Projekt statbot.swiss an. Finanziert wird es durch eGov Schweiz, geleitet vom Bundesamt für Statistik und der Konferenz der regionalen statistischen Ämter der Schweiz. Technologische Partner sind die Zürcher Hochschule für angewandte Wissenschaften (ZHAW) sowie das Swiss Data Science Center (SDSC).
Das Projekt besteht aus zwei Teilen: Im chronologisch zweiten Teil experimentieren Forschende der Zürcher Hochschule für angewandte Wissenschaften an einem Machine-Learning-Algorithmus, der natürliche Sprache in Datenbankabfragen übersetzen kann [1]. Dieser soll die Antworten in Form von Datenwerten, Tabellen oder Grafiken anzeigen. Das aktuelle Projekt setzt dabei den Fokus absichtlich und bescheiden auf die Abklärung der Machbarkeit und der technischen Limitierungen.
Im bereits abgeschlossenen ersten Teil des Projekts haben wir ein Open Source Data Warehouse [2] gebaut, das Daten aus unterschiedlichen Quellen an einem Ort integriert und harmonisiert. Es lädt die Daten aus unterschiedlichen Schnittstellen, führt die gesamte Transformation («ETL») aus und erstellt alle Daten in einer einheitlichen, definierten Datenstruktur mit dazugehörenden Mapping-Tabellen für Dimensionen. Ziel war auch, die Datenstandardisierung und -harmonisierung voranzubringen.
[1] Die ZHAW leitet das Projekt «INODE – Intelligent Open Data Exploration», das vom EU-Forschungsprogramm Horizon 2020 mit knapp 6 Millionen Euro gefördert wird.).
Abbildung 1: Übersicht über die verschiedenen open source Repositories. Die Machine-Learning-Lösung der ZHAW wird dann sowohl auf die Datenbank, wie auch auf die generierten Trainingsdaten zugreifen. Ein sehr einfaches Frontend soll erstellt werden.
Das Hinzufügen der Daten ist dabei skalierbar: wir konnten Stand heute über 240 «Statbot-Datasets» mit Inputdaten sowohl aus dem Bundesamt für Statistik wie auch aus sechs weiteren regionalen Statistikämtern hinzufügen. Wir haben dabei einen Prozess geschaffen, der keine Programmierung durch Mitarbeitende von teilnehmenden Statistikämtern benötigt. Stattdessen brauchen diese nur das sprichwörtliche Rezept anzugeben, wie die Daten verarbeitet werden sollen: Für einen Milchshake müssen die Früchte gewaschen, geschält, dann in den Mixer gegeben und am Ende mit Milch gemischt werden. Die Reihenfolge dieser Schritte gibt der Mitarbeitende ein einziges Mal ein, dann kann die Maschine regelmässig die aktuellsten Inputdaten holen und die notwendigen Transformationen durchführen.
Wichtig ist dabei auch, dass dieser Endzustand aller Datasets gleich ist, wobei wir hier eine Lösung gefunden haben, die sich an bisherigen Ansätzen orientiert [3]. Als zusätzlicher Schritt müssen daher Dimensionen «harmonisiert» werden. Jede Dimension wie Geschlecht oder Staatsangehörigkeit hat dabei gewisse Codes. Wenn die Standardcodes (üblicherweise aus dem Bundesamt für Statistik) verwendet werden, läuft das Matching ohne grösseren Zusatzaufwand. Ansonsten können neue Mappings hinzugefügt werden, um eine flexible Zuordnung herzustellen.
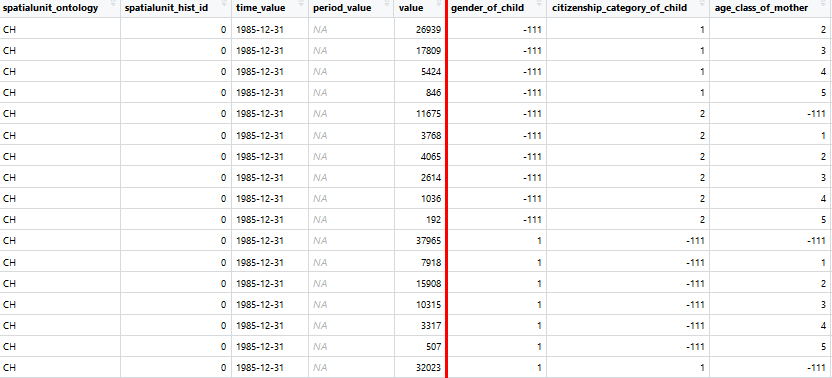
Das Resultat sind relationale Daten in einer definierten Struktur mit einheitlichen Spaltenbezeichnungen, Zuordnung von Raum, Zeit, Dimensionen sowie Attributen und klar bestimmten Kodierungen [4].
Diese «Statbot-Datasets» sind somit einheitlich strukturiert. Damit ist es leichter, daraus datensatzübergreifende Applikationen zu bauen, beispielsweise eine Machine-Learning-Lösung wie im zweiten Teil des Projekts oder ganz andere Applikationen, die nun auf solche bereinigten Daten zugreifen könnten.
[3] Es orientiert sich sowohl an der Linked Data Lösung von Statistik Stadt Zürich wie auch am SDMX-Format, welches u.a. von Eurostat verwendet wird. Die Überlegungen gehen dabei noch weiter, ob sogar diese Formate generiert werden könnten.
[4] Momentan fehlt eine Vorgabe für eine «definierte Struktur» von Statistikdaten in Schweizer Statistikämtern. Diese funktionale Vorgangsweise könnte auch als Bottom-up-Lösung dienen, um einer Harmonisierung schrittweise näher zu kommen.
Abbildung 2: Ein Beispiel der definierten Datenstruktur eines «Statbot-Datasets». Die ersten beiden Spalten definieren eindeutig die Raumeinheiten. Die nächsten beiden Spalten definieren Zeitelemente (Stichtage sowie Perioden). Danach kommt der Beobachtungswert des Datenpunkts. Alles was rechts der eingezeichneten Linie ist, sind Dimensionen, die von Dataset zu Dataset unterschiedlich sind aber die in Dimensionstabellen definiert sind. Im Bild nicht sichtbar sind angedachte Attributsspalten: Quellenangaben, Definitionsangaben und «Flags» mit weiteren Informationen pro Datenpunkt.
Weiteres Potenzial
Das Projekt lehrt uns viel über Machine Learning. In Machine-Learning-Projekten geht es um weit mehr als den Gebrauch der Algorithmen. Viel Arbeit muss in Grundlagenarbeit gesteckt werden, um die Daten für Algorithmen überhaupt brauchbar zu machen. Dazu gehört auch die Bereitstellung von «Trainingsdaten», also Paare von Fragen in natürlicher Sprache und passenden Antworten in Form von Datenbankabfragen. Die werden dann verwendet, um den Algorithmus zu trainieren. Hier haben wir mit zusätzlichen Sprachinformationen gearbeitet, um sinnvollere Sätze zu generieren, die aber dennoch etwas hölzern erscheinen.
Die klare Trennung von Inhalt und Bezeichnung und die einheitliche Strukturierung und Harmonisierung der Bezeichnungen im Data Warehouse werden es darüber hinaus erlauben, automatisiert hochwertige «Linked Open Data» zu generieren. Linked Open Data sind Daten, die schnittstellenartig per HTTP abgerufen werden können, und die auf weitere Ressourcen verweisen können.
Dies würde vernetzte Datenlösungen ermöglichen, welche Daten aus den verschiedensten Quellen kombinieren könnten und es würde ein semantischer Datenraum geschaffen werden. Das wäre ein zusätzlicher Mehrwert für Nutzende, Firmen sowie das gesamte Statistiksystem der Schweiz, da es weitere maschinelle Anwendungen ermöglichen würde.
Ein Projekt-Teilnehmer hat kürzlich Folgendes treffend formuliert: «Auch nach dem offiziellen Ende des Projekts statbot.swiss glaube ich, dass das Data Warehouse bestehen bleiben wird… Es ist womöglich das erste Mal in der Schweiz, dass öffentliche Daten von verschiedenen Datenproduzenten an einem Ort in einer gemeinsamen, harmonisierten Struktur vorhanden sind.». Die Datenbedürfnisse der potentiellen Machine-Learning-Anwendung haben somit als wesentliche Anforderung dazu geführt, Daten zu strukturieren und zu harmonisieren. Dieses Resultat – das Data Warehouse – könnte viel Potenzial für andere Anwendungen haben.
Ich erinnere an dieser Stelle zunächst an die Bürgerin, die hoffentlich in der Zwischenzeit die gesuchten Daten gefunden hat. Jede Entwicklung, egal ob ein Data Warehouse, ein Bot oder eine andere Anwendung, muss direkt oder indirekt auf die Bedürfnisse der Bürger ausgerichtet sein. Öffentliche Behördendaten sollten einfacher auffindbar, vernetzter und leichter in andere Applikationen integrierbar werden.
Hier möchten wir mit der Community durch persönliche Gespräche, Events und Online stärker ins Gespräch kommen. Einerseits möchten wir die Datenbedürfnisse der Nutzenden besser kennen, um darauf bedarfsorientiert entwickeln zu können. Andererseits können wir damit leichter Lösungen wie den Bot in einer frühen Phase testen und Feedback integrieren. Wenn Sie Interesse haben, können Sie mir gerne formlos eine E-Mail mit Betreff statbot.swiss schreiben.
Dr. Christian Ruiz
Projektleiter Machine Learning Statistisches Amt Kanton Zürich
Der Autor Dr. Christian Ruiz leitet aktuell das Machine Learning im Statistischen Amt Kanton Zürich. Er hat 13 Jahre Erfahrung in Data Science und 6 Jahre Erfahrung in der praktischen Entwicklung von Machine-Learning-Anwendungen. Er ist Mitgründer von zwei Startups im Bereich Deep Learning, hat drei weitere Machine-Learning-Projekte umgesetzt und andere Projekte begleitet.
Die 1986 kurz nach dem Start explodierte Challenger-Raumfähre der NASA mit sieben Astronauten[1] und das wegen eines Fehlers in Google Maps versehentlich abgerissene Haus von Lindsey Diaz[2] sind beides Konsequenzen mangelnder Datenqualität.
Als multifaktorieller, unscharfer Begriff ist Datenqualität kein «Messerwert», sondern wird multimodal erarbeitet: bei Online-Befragungen vor der Feldphase mittels elaboriertem Sampling, Fragebogenkonzeption und Pretesting. Aber auch danach in der Analyse und der Bereinigung der gewonnenen Daten. Hinzu kommen Meta-Aspekte der Datenqualität wie Passung der Daten zur Forschungsfrage, Prozesstransparenz, faire Datengewinnung oder proaktiver Datenschutz, die Empowerment für Kunden bewirken.
Datenqualität – was ist das?
57 Millionen Suchergebnisse bei google verdeutlichien die Relevanz des Begriffs «Data Quality». Im täglichen Sprachgebrauch wird der Begriff «Datenqualität» häufig mit der Richtigkeit (Präzision) von Daten gleichgesetzt. Um diese zu erhöhen, werden genauere Messinstrumente, rigorose Datenerhebungsverfahren und komplexe statistische Methoden zum Aggregieren von Daten entwickelt[3]. Auch der Fokus der nachfolgend präsentierten Massnahmen zur Erhöhung der Datenqualität liegt auf der Verbesserung der klassischen Gütekriterien Validität und Reliabilität von Umfrageergebnissen. Darüber hinaus differenzieren Konzepte wie das der Universität Greifswald Datenqualität weiter, hier in die Dimensionen Integrität, Komplettheit und Korrektheit (Konsistenz und Akkuratheit)[4] – und es existieren in der Literatur zahlreiche überlappende Modelle[5].
Bild 1: Datenqualitätsmodell der Universität Greifswald nach Schmidt et al. (2021)
Insbesondere im Bereich der Markt- und Meinungsforschung stehen am Ende der Datenverarbeitung Auftraggebende oder Forschende als Consumer der Daten. Daher ist es besonders wichtig, zu verstehen, dass Datenqualität aus Konsumentensicht oft über die Präzision von Werten hinausgeht.
Consumer als Zielgrösse
Welche Aspekte der Datenqualität für Consumer ausschlaggebend sind, untersuchten Richard Y. Wang und Diane M. Strong in einer zweistufigen empirischen Studie. Definiert wurde Datenqualität dabei über das verbreitete «fitness-for-use»-Konzept[6], welches Datenqualität durch die Eignung der Daten zum von Consumern angedachten Zweck bestimmt. Das Ergebnis der Studie war ein vierdimensionales Modell von Datenqualität, welches das bestehende Konzept empirisch operationalisiert[6].
Die vier Dimensionen sind: intrinsic data quality, contextual data quality, representational data quality und accessibility data quality. Sie zeigen, dass für Consumer der Begriff der Datenqualität vielschichtig ist und nicht nur im Sinne der Richtigkeit verstanden werden sollte. Vielmehr sind auch Aspekte wie Glaubwürdigkeit, Relevanz, Vollständigkeit, Interpretierbarkeit, Konsistenz oder Zugänglichkeit der Daten für Consumer ausschlaggebend[4].
Tabelle 1: Dimensionen der Datenqualität mit Ausprägungen nach Wang und Strong (1996).
Vor der Befragung
Jede Onlinebefragung ist trotz Abwesenheit einer interviewenden Person und den damit wegfallenden primären Interviewer-Effekten (deshalb oft als «verzerrungsfrei» angepriesen) immer eine Situation, in der im Extremfall eine parasoziale Interaktion mit einem imaginären Interviewer stattfindet. Oder die mindestens irgendeine Art von kognitivem Stimulus-Response-Prozess bei Befragten auslöst. Dieser gliedert sich als Cognitive Aspects of Survey Methodology (CASM) vereinfacht in vier Schritte[7-10]:
Lesen und Verstehen der Frage
Abrufen relevanter Informationen aus dem Gedächtnis
Beurteilung der abgerufenen Informationen bezüglich Vollständigkeit und Relevanz, kognitive Editierung der präferierten Antwort auf das gewünschte Antwortformat und Angemessenheit
Antwortabgabe
Die kognitive Verarbeitung folgt dabei den Zweiprozessmodellen[11-12] und geschieht elaboriert (intensiv, zentral) oder peripher (oberflächlich, schnell, nebenbei, heuristisch). Eine elaborierte Verarbeitung begünstigen unter anderem die gute Verständlichkeit der Frage, die kognitive Fähigkeit sowie die Motivation der Antwortenden, genügend Zeit und wenig Ablenkung. Eine periphere Verarbeitung öffnet die Tür für Verzerrungseffekte noch weiter.
Zehn Gebote für gute Fragebögen
Bei dieser Verarbeitung sind eine Menge latenter Störeinflüsse (Response Bias[13]) im Spiel, die sich nur schwer kontrollieren lassen. Trotzdem kann im Design von Fragebögen mit zehn Geboten[9], soweit möglich und ökonomisch sinnvoll, vorgesorgt werden, wobei diese weniger als «starre» Regeln, denn als Reflexionsbasis für das Finetuning von Fragebögen dienen:
einfache, unzweideutige Begriffe (werden von allen Befragten sehr ähnlich verstanden)
unklare Begriffe definieren
keine langen/komplexen Fragen
keine hypothetischen Fragen
keine Doppelstimuli/Doppelverneinung
keine Unterstellungen/Suggestivfragen
keine Fragen nach Informationen, die viele Befragte vermutlich nicht kennen
Fragen mit eindeutigem zeitlichen Bezug
Antwortkategorien sind erschöpfend und disjunkt (überschneidungsfrei)
Kontext einer Frage wirkt sich nicht auf deren Beantwortung aus
Zum Beispiel kann eine Frage wie «Wurden in Ihrer Schule bereits Projekte im Rahmen des LP21 umgesetzt?» vielleicht Lehrpersonen gestellt werden, aber nicht Eltern (Gebote 2 und 7). Und «Experten denken, dass CO2-Massnahmen zu langsam umgesetzt werden – halten Sie diese Ansicht für richtig oder für falsch?» verstösst gegen das sechste Gebot. Sogar in wissenschaftlich angesehenen Studien werden Fragen gestellt, die sich in erheblichem Masse der Erinnerbarkeit entziehen (Mobiltelefonnutzung in den letzten 6 Monaten): «detailed questions were asked about the initial pattern of use, including network operator and average number and duration of calls, and any subsequent changes in use patterns. Questions were also asked about the proportion of time the phones were used in urban, suburban or rural settings»[14] (Gebot 3, 7, 8). Entsprechend der Konversationsmaximen nach Grice[15] gilt auch für Formulierungen in Fragebögen:
• Qualität (wahr und nicht suggestiv) • Quantität (so ausführlich wie nötig, so kurz wie möglich) • Relevanz (zielgruppengerecht, nur fragen und ansprechen, was zum Thema gehört) • Modalität (klar, eindeutig, kompakt und geordnet)
Weiter sollten Übertragungseffekte minimiert werden: Steht vor der Frage, «Welche Partei wählen Sie am Wahlsonntag?» eine Frage zu Umweltkatastrophen oder eine zum Wirtschaftswachstum? Ist Fleisch 25% fett oder 75% mager?[16] Übertragungs- und Framing-Effekte sollten mit möglichst objektiven Formulierungen und Kontexten verringert werden.
Skalen sind Korsetts, die passen müssen
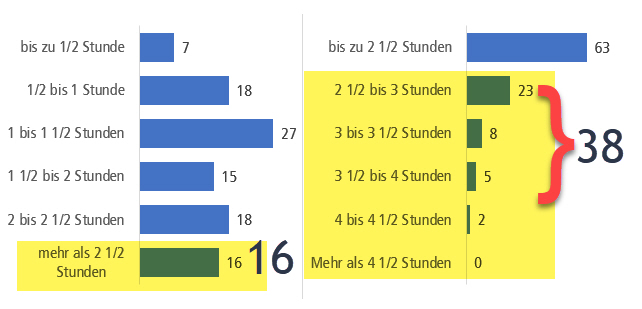
Auch Rating-Skalen an sich können Verzerrungen unterstützen, da Antworten von den Befragten «passend» gemacht werden. «Trash-Antworten» können reduziert werden, in dem eine Ausweichkategorie «keine Antwort» angeboten wird. Dadurch gehen leider einige gültige Antworten verloren, die versteckte Datenverschmutzung, wenn wegen Fehlen einer Ausweichkategorie einfach irgendwas angekreuzt wird[17], nimmt jedoch ab. Eine mittlere Ausprägung wie «teils/teils» wird ebenfalls empfohlen[18]. Rating-Skalen mit 5 bis 7 vollverbalisierten Antwortkategorien werden mehrheitlich als ratsam erachtet – zu wenige Kategorien differenzieren ungenügend, zu viele sind inhaltlich schwer zu unterscheiden, fehlende Verbalisierung ist schwerer zu interpretieren[18]. Einige weitere Verzerrungseffekte, denen in Online-Befragungen Beachtung geschenkt werden sollte, sind Akquieszenz (generelle Zustimmungstendenz in Skalen), Non-Attitude (beliebige Antworten bei Desinteresse, Zeitknappheit), soziale Erwünschtheit (Erwartungskonformität), Sponsorship-Effekte (Antworten dem Auftraggeber zuliebe), Situationseffekte (Kontext und Ort des Ausfüllens, Anwesenheit von Bekannten, Helfern), Tendenzen zur Mitte (Meiden von Extremen), Lageeffekte (Primacy/Recency-Effekt: Erste und letzte Antwortvorgaben werden besser erinnert und bevorzugt, weil salienter) oder Ankereffekte (Übertragung, Beeinflussung durch Vorfragen, selektives Antwortuniversum, Priming). Schwarz[19] hat zu Letzterem schon 1999 festgestellt, dass Antwortvorgaben implizite Anker setzen. So antworteten unter Verwendung der linken Skala (vgl. Bild 2) nur 16% der Befragten mit «mehr als 2 ½ Stunden». Mit der rechten Skala hingegen insgesamt 38%, obwohl dieselbe Frage gestellt worden war. Die Extremposition der Antwortvorgabe «mehr als 2 ½ Stunden» in der linken Skala lässt die Teilnehmenden unterreportieren, rechts ist der umgekehrte Effekt der Fall.
Bild 2: Ankereffekt der Antwortvorgaben bei Schwarz (1999)
Die Datenqualität ist auch beeinflusst durch die Frageformate: offene Textfelder versus Skalen versus halboffene Formate, Validierungen direkt im Fragebogen, Regie-Anweisungen, visuelle Darstellung von Skalen, Mobildarstellung, technische Einflüsse wie schwer bedienbare Schieberegler; und ebenso Herausforderungen bestimmter Zielgruppen wie Kinder oder digital unerfahrene Benutzer. Pretesting sowie Regie-Hinweise bezüglich der erwarteten Dateneingaben in punkto Umfang, Art und Format der Eingaben sind im Fragebogen fast immer vorteilhaft.
Einige Probleme der Datenqualität können somit durch intensive Reflexion, Einbinden von Fragebogen-Consultants, ausführliches Pretesting (z. B. auch mit Explorieren oder Split-Half-Setups verschiedener Frageformate) und Überarbeiten von bereits bestehenden Fragebögen durchaus adressiert werden.
Nach der Befragung
Mit einem Prämienvolumen von knapp 6 Mrd. CHF (1) stellt die Motorfahrzeugsparte (MFZ) das grösste Auch im Nachgang können Massnahmen zur Verbesserung der Datenqualität getroffen werden. Diese beziehen sich hauptsächlich auf verzerrende Effekte, die Teilnehmende durch ihr Verhalten im Fragebogen erzeugen.
Während einige dieser Effekte, wie z. B. Ausreisser*, Speeder** oder inkomplette Fragebögen unabhängig vom Befragungsmodus auftreten (z. B. auch in CATI, Face-to-Face), häufen sich gerade bei schriftlichen und Online-Befragungen sogenannte «Response-Sets» (Tendenzen von Teilnehmenden, eine Reihe von Fragen in einem bestimmten Muster zu beantworten)[20]. Bei Online-Befragungen wird dies zusätzlich durch die erhöhte empfundene Anonymität verschärft, da mit steigender Anonymität die Tendenz steigt, Items weniger ernsthaft auszufüllen und falsche oder fiktive Antworten abzugeben[20].
*Datenpunkt, der bedeutend von den restlichen Datenpunkten entfernt liegt. **Teilnehmende, die den Fragebogen in einer Zeit komplettieren, die bei seriösem Durchlesen der Fragen und Antwortmöglichkeiten nicht plausibel ist.
Klassische Antwortmuster, die in schriftlichen Befragungen mit Rating-Skalen beobachtet werden können, sind: Response-Ranges (Verwendung nur eines bestimmten Bereichs der Skala, unabhängig vom Inhalt der Frage oder der Ausrichtung der Antwortvorgaben), Extreme Checking Style (auch Extreme Response Style[21], ERS, genannt: abwechselndes Anwählen der linken und rechten Extrempunkte einer Skala), Muster-Ankreuzer (Ankreuzen von Mustern wie z. B. Diagonalen oder Pfeilen in Tabellenfragen) und Straightliner (Null-Varianz-Antwortverhalten, d. h. Auswahl eines bestimmten Skalenpunkts, unabhängig von der Skalenbreite, -ausrichtung und Frageformulierung). Gerade Letztere sind bei unmotivierten Teilnehmenden beliebt. Jandura identifiziert in einer offenen Online-Befragung zu Mediennutzungsverhalten von Jugendlichen bei einem Viertel der Befragten ein Null-Varianz-Antwortverhalten in mindestens einer der neun beantworteten Fragen[20]. Allerdings muss hier relativiert werden, dass Straightlining unter gewissen Umständen valide ist, beispielsweise, wenn eine Item-Batterie eine hohe interne Konsistenz aufweist und alle Items in dieselbe Richtung formuliert sind[22]. Um valides Straightlining auszuschliessen, könnte ein Item pro Frageblock vor der Feldphase umgepolt werden.
Um die Qualität der Ergebnisse einer Befragung zu erhöhen, sollten Fälle mit den beschriebenen Effekten untersucht und allenfalls aus der Analyse exkludiert werden. Während dies bei einigen Effekten relativ einfach möglich ist (z. B. können Speeder anhand der Bearbeitungszeit und inkomplette Fragebögen anhand der fehlenden Antworten schnell identifiziert werden), ist für andere Effekte ein genaueres Hinsehen notwendig (siehe Tabelle 2). Der Prozess kann dabei digital mit multifaktoriellen, statistischen Prozeduren unterstützt werden. Die Entscheidung, ob ein spezifischer Fall nun als Quality Fail ausgeschlossen werden soll oder nicht, sollte jedoch durch geschulte Mitarbeitende nach der Sichtung des entsprechenden Fragebogens und nicht auf Basis einzelner Kriterien erfolgen.
Tabelle 2: Erkennen von verzerrenden Effekten im Datensatz, angelehnt an Jandura (2018) und Reuning und Plutzer (2020).
Fazit
In einem kurzen Artikel kann das Thema Datenqualität lediglich anhand ausgewählter Aspekte angeschnitten werden. Zusammenfassend ergeben sich drei essenzielle Punkte:
Eine Ausrichtung der Datenqualität auf Abnehmergrupp
Wesentliche Weichen für die Datenqualität werden schon vor der Feldphase gestellt.
Eine Datenqualitätsanalyse und Datenbereinigung nach der Feldphase ist technisch möglich und nützlich.
Dies sind wichtige Erkenntnisse für validere Analysen, für die Kundenkommunikation, den Projektaufbau und das Branchen-Image.
Datenqualität geht zudem einher mit Themen wie Erhebungs- und Verwendungsethik, Zweckbestimmung von Daten, Panelpflege, Datenschutz und mit der Idee, auch komplexe Prozesse der Auswertungslogik, Algorithmen und Deep-Learning-Modelle so transparent wie möglich zu machen. Ein positives Wechselverhältnis von Datengebenden und -nehmenden widerspiegelt sich in einem emanzipierten und daher lohnenswerten Verständnis von Datenqualität für alle.
Die Autoren Raffael Meier, MA, MSc – Mitgründer und CTO von onlineumfragen.com und Pionier der Onlinebefragungstechnologie. Er befasst sich mit gesellschaftlichen und methodologischen Aspekten von Daten und berät Kundinnen und Kunden mit dem Ziel «Empowerment».
Nina Gwerder, MA – ist Consultant bei onlineumfragen.com und spezialisiert auf die Beratung namhafter nationaler und internationaler Unternehmen rund um das Thema Online-Befragungen und deren effektiver Auswertung.
Literaturverzeichnis [1] Fisher, C. W., & Kingma, B. R. (2001). «Criticality of data quality as exemplified in two disasters », Information & Management, 39(2), 109–116. https://doi.org/10.1016/S0378-7206(01)00083-0 [2] Wrong house gets torn down based on a Google Maps error. Engadget. (n.d.). Abgerufen am 17. August 2022, von https://www.engadget.com/2016-03-24-texas-wrong-house-torn-down-google-maps.html [3] Keller, S., Korkmaz, G., Orr, M., Schroeder, A. und Shipp, S. (2017). «The Evolution of Data Quality: Understanding the Transdisciplinary Origins of Data Quality Concepts and Approaches», Annual Review of Statistics and Its Application, 4(1), S.85-108. [4] Schmidt, C. O., Struckmann, S., Enzenbach, C., Reineke, A., Stausberg, J., Damerow, S., Huebner, M., Schmidt, B., Sauerbrei, W., & Richter, A. (2021). «Facilitating harmonized data quality assessments. A data quality framework for observational health research data collections with software implementations in R», BMC Medical Research Methodology, 21(1). https://doi.org/10.1186/S12874-021-01252-7 [5] Haug, A. (2021). «Understanding the differences across data quality classifications: a literature review and guidelines for future research», Industrial Management and Data Systems, 121(12), 2651–2671. https://doi.org/10.1108/IMDS-12-2020-0756 [6] Wang, R.Y. und Strong, D.M. (1996). «Beyond Accuracy: What Data Quality Means to Data Consumers», Journal of Management Information Systems, 12(4), S.5-33. [7] Cannell, C. F., Miller, P. v., & Oksenberg, L. (1981). «Research on interviewing techniques», in S. Leinhardt (Ed.), Social Methodology. Jossey-Bass Publishers. [8] Tourangeau, R., Rips, L. J., & Rasinski, K. (2000). The Psychology of Survey Response. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511819322 [9] Porst, R. (2014). Fragebogen. Wiesbaden: Springer Fachmedien. https://doi.org/10.1007/978-3-658-02118-4 [10] Tourangeau, R. (2018). «The survey response process from a cognitive viewpoint», Quality Assurance in Education, 26(2), 169–181. https://doi.org/10.1108/QAE-06-2017-0034 [11] Petty, R. E., & Cacioppo, J. T. (1986). «The elaboration likelihood model of persuasion», Advances in Experimental Social Psychology, 19(C), 123–205. https://doi.org/10.1016/S0065-2601(08)60214-2 [12] Dual-process theories in social psychology. PsycNET. (n.d.). Abgerufen am 17. August 2022, von https://psycnet.apa.org/record/1999-02377-000 [13] Bogner, Kathrin und Landrock, Uta (2015). Antworttendenzen in standardisierten Umfragen. Mannheim, GESIS Leibniz Institut für Sozialwissenschaften (GESIS Survey Guidelines). https://doi.org/10.15465/gesis-sg_016 [14] Cardis, E., Richardson, L., Deltour, I. et al. (2007). «The INTERPHONE study: design, epidemiological methods, and description of the study population», Eur J Epidemiol, 22, 647–664. https://doi.org/10.1007/s10654-007-9152-z [15] Grice, H. P. (1975). «Logic and Conversation», in P. Cole, & J. L. Morgan. (Eds.), Syntax and Semantics, Vol. 3, Speech Acts (pp. 41-58). New York: Academic Press. [16] Levin, I. P., & Gaeth, G. J. (1988). «How Consumers are Affected by the Framing of Attribute Information Before and After Consuming the Product», Journal of Consumer Research, [15] (3), 374. https://doi.org/10.1086/209174 [17] Berekoven, L., Eckert, W., & Ellenrieder, P. (2004). Marktforschung. Wiesbaden: Gabler Verlag. https://doi.org/10.1007/978-3-663-05734-5 [18] Menold, N., & Bogner, K. (2015). «Gestaltung von Ratingskalen in Fragebögen (Version 1.1)», GESIS Survey Guidelines, 13. https://doi.org/10.15465/GESIS-SG_015 [19] Schwarz, N. (1999). «Self-reports: How the questions shape the answers», American Psychologist, 54(2), 93–105. https://doi.org/10.1037/0003-066X.54.2.93 [20] Jandura, O. (2018). «Fake Data? Zur Trennung von sauberen und verschmutzten Daten bei selbst-administrierten Befragungsmodi», in Rössler P. & Rossman, C. (Hrsg.), Kumulierte Evidenzen. Wiesbaden: Springer VS, S. 207-223. [21] Greenleaf, E. A. (1992). «Measuring Extreme Response Style», The Public Opinion Quarterly, 56(3), 328–351. http://www.jstor.org/stable/2749156 [22] Reunig, K. und Plutzer E. (2020). «Valid vs. Invalid Straightlining: The Complex Relationship Between Straightlining and Data Quality», Survey Research Methods, 14(5), S.439-459.
Im Folgenden möchten wir Antworten auf diese Fragen geben und schicken gleich voraus, dass es wie so oft, nicht den einen Ansatz gibt, der zu verfolgen ist, sondern dass verschiedene Wege zum Ziel führen. Daher teilen wir zunächst ein paar grundlegende Erkenntnisse, die übergreifende Gültigkeit haben, bevor wir anhand eines konkreten Beispiels aus der Praxis auf spezifische Fragen, Methoden und Auswertungsansätze eingehen.
Erfolgsfaktoren der Preisforschung
Behavioral Pricing basiert auf valider Preisforschung als Grundlage für geplante Preisoptimierungen. Aus unserer Erfahrung sind hierbei drei Faktoren relevant für den Erfolg:
Das richtige Kundenmodell
Die Untersuchung von allen relevanten Entscheidungsdimensionen
Wahl der optimalen Methode
1. Das richtige Kundenmodell
Preisforschung ist Entscheidungsprozessforschung. Möchten Sie das Entscheidungsverhalten Ihrer Kunden verstehen, prognostizieren und gestalten? Dann müssen Sie das richtige Kundenmodell wählen. Dieses ist von zentraler Bedeutung, um sicherzustellen, dass das Entscheidungsverhalten, welches die Kunden in der Marktforschung zeigen, möglichst ihrem Entscheidungsverhalten in der Realität entspricht.
Die Erkenntnisse der Verhaltensökonomie zeigen nachdrücklich auf, dass Menschen vorhersagbar irrational entscheiden. Dies heisst, dass sie nicht wie der klassische Homo Oeconomicus agieren, sondern sich von Daumenregeln (Heuristiken) leiten lassen. Thaler und Sunstein nutzen hierfür das Bild des Mr. Spock von Raumschiff Enterprise, der rational und stabil wie ein Computer entscheidet – im Gegensatz zum in der Realität zumeist anzutreffenden Homer Simpson, der eher irrational und mit wechselnden Präferenzen unterwegs ist.
Sie fragen sich nun vermutlich: Warum ist das Kundenmodell so wichtig für valide Preisforschung? Ausschlaggebend ist doch vielmehr, die richtigen Fragen zu stellen und das richtige Testmaterial zu präsentieren. Unserer Erfahrung nach wird Ihnen dies jedoch nur gelingen, wenn Sie das richtige Kundenmodell anwenden. Zur Untermauerung dieser Aussage zeigen wir im Folgenden eine Reihe von verhaltensökonomischen Erkenntnissen und die zugehörigen Implikationen für die Preisforschung auf:
Abbildung 1: Verhaltensökonomische Erkenntnisse und Implikationen für Preisforschung
2. Die Untersuchung von allen relevanten Entscheidungsdimensionen
Um sowohl Input für die Ausgestaltung und Kommunikation konkreter Leistungsangebote zu generieren, als auch Erkenntnisse zum Pricing zu gewinnen, hat es sich bewährt, alle relevanten Dimensionen des Entscheidungsprofils der Kunden zu erheben. Die hieraus gewonnenen Erkenntnisse helfen auch wesentlich bei der Interpretation der noch zu diskutierenden Preisakzeptanz.
Im Einzelnen geht es um drei Dimensionen, die das Entscheidungsprofil der Kunden ausmachen:
Abbildung 2: Dimensionen Entscheidungsprofil
3. Wahl der optimalen Methode
Wie bereits erwähnt, sollte das Entscheidungsverhalten der Kunden in der Marktforschung möglichst ihrem Entscheidungsverhalten in der Realität entsprechen.
Da die Auswahl der passenden Methode nicht generisch beantwortet werden kann, möchten wir an dieser Stelle die grundsätzliche Ebene verlassen und auf ein konkretes Projektbeispiel zu sprechen kommen. Wir gehen jedoch davon aus, dass einzelne Erkenntnisse auch auf andere Branchen bzw. Produkte übertragen werden können.
Fallstudie: Preisoptimierung von Motorfahrzeugtarifen
Mit einem Prämienvolumen von knapp 6 Mrd. CHF (1) stellt die Motorfahrzeugsparte (MFZ) das grösste Segment in der Sachversicherung dar. Preisoptimierungen lohnen sich daher allein schon wegen des Anteils der Sparte am Prämienvolumen eines jeden Sachversicherers. Es gibt jedoch noch weitere Gründe, warum sie für Behavioral Pricing Ansätze ein lohnendes Anwendungsgebiet darstellt:
(1) Gebuchte Haftpflicht- plus Kaskoprämien in 2020 (Quelle: FINMA «Bericht über den Versicherungsmarkt 2020»
Das intangible, auf die Zukunft gerichtete Leistungsversprechen von Versicherungen erschwert Kunden die Entscheidungsfindung. Um zu vermeiden, dass sie sich zu schnell auf den Preis fokussieren, lohnt es sich, das Entscheidungsverhalten differenzierter zu untersuchen, um Ansatzpunkte für Differenzierungen jenseits des Preises zu identifizieren (siehe Ausführungen oben zur Motivation).
Die MFZ-Sparte ist weitgehend ausgereift und kann sich kaum über Innovationen bei ihren Kunden positionieren. Innovationen sind vor allem in Bezug auf Themenfelder wie E-Mobilität und autonomes Fahren zu erwarten. Je reifer jedoch eine Branche, desto grösser ist das Risiko von Preiskämpfen, die aus der Branche heraus in Ermangelung anderer, naheliegender Alternativen initiiert werden.
Bei Vertriebsmitarbeitern herrscht häufig die Wahrnehmung vor, die Mehrheit der Kunden sei sehr preissensitiv. Dies steigert das Risiko, dass der Preis zu stark in den Mittelpunkt des Vertriebsansatzes rückt. Verstärkt wird dieses Risiko durch das Bestreben, Motorfahrzeugversicherungen möglichst effizient zu vertreiben, um das Verhältnis zwischen Zeiteinsatz und zu erhaltender Provision zu optimieren.
Diese Ausgangslage war uns bewusst, als wir die Anfrage zur Optimierung eines MFZ-Tarifs erhielten. Umso wichtiger war es uns, die Befragten einerseits mit einer möglichst realistischen Entscheidungssituation zu konfrontieren, andererseits den Rahmenfragebogen ausreichend ausführlich zu gestalten, um das Entscheidungsverhalten der Befragten möglichst umfassend zu erheben.
Die Schaffung einer möglichst realistischen Ausgangssituation bedeutet in diesem Fall, die Berechnung realitätsnaher Prämien auf Basis ausgewählter, tarifierungsrelevanter Merkmale. Selbst wenn man sich auf die zentralen Kriterien wie u. a. Fahrzeugalter, Neuwagenpreis, Alter/Geschlecht/Nationalität des Fahrers fokussiert, ergibt sich aufgrund der Vielzahl an Ausprägungen je Merkmal und Kombinationsmöglichkeiten sehr rasch ein komplexes Modell. Auf Basis des Inputs des Kunden haben wir daher ausserhalb unserer üblichen Befragungssoftware ein separates Tarifierungstool programmiert, welches uns ermöglichte, die Befragten mit realistischen Preisen zu konfrontieren.
Die folgende Abbildung 3 gibt einen Eindruck vom Tarifierungstool, wie es den Kunden in der Befragung präsentiert wurde.
Abbildung 3: Überblick Tarifierungstool
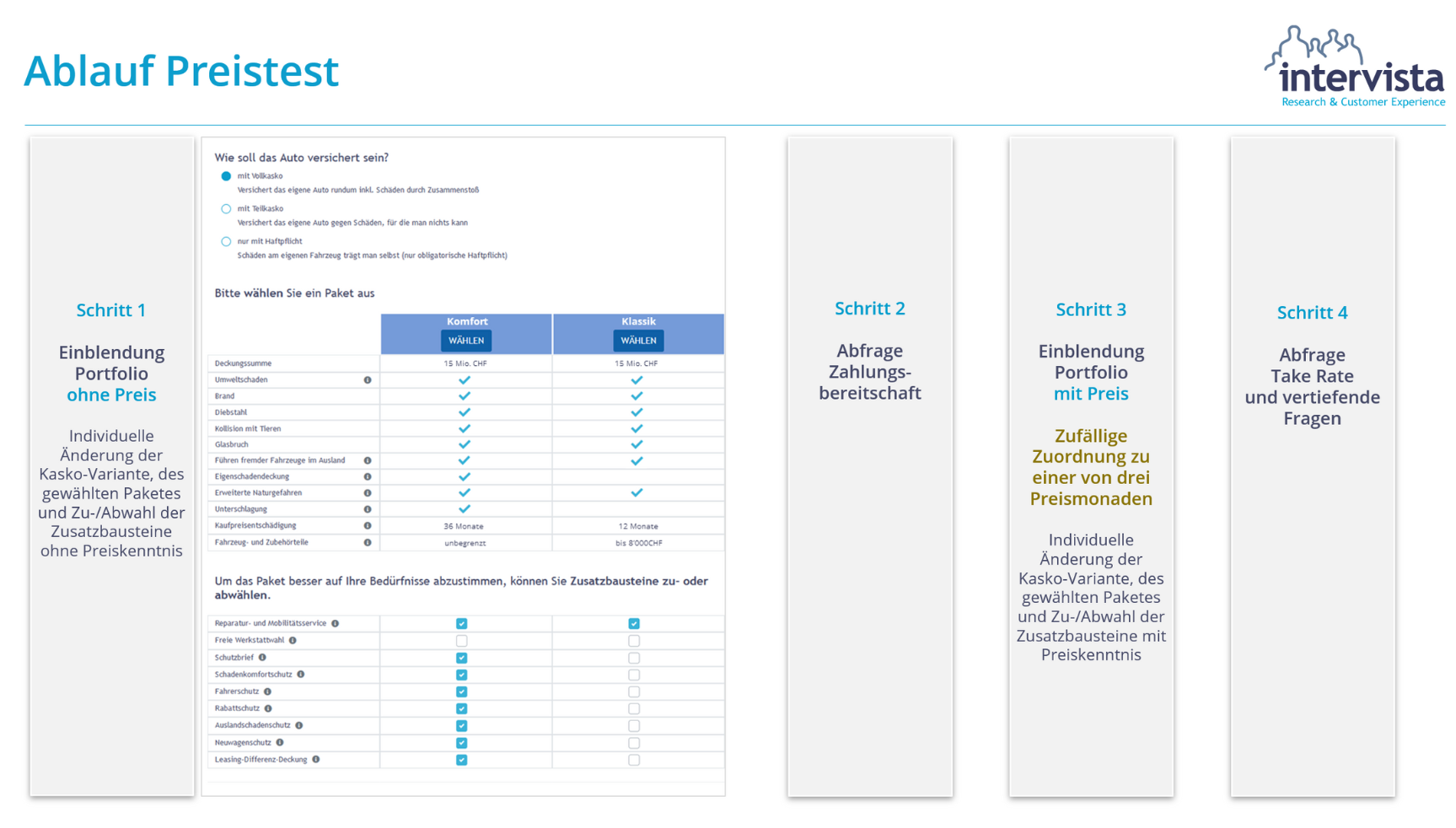
Um den Entscheidungsprozess der Kunden möglichst differenziert zu untersuchen, vollzogen wir den eigentlichen Preistest in mehreren Schritten, wie in der folgenden Abbildung 4 dargestellt.
Abbildung 4: Ablauf Preistest
Auf Basis der Befragungsergebnisse konnten Empfehlungen zu den folgenden Themenfeldern abgegeben werden:
Anzahl der empfohlenen Produktlinien
Die Verteilung der Wahlanteile in einem realistischen Umfeld belegt den Bedarf an zwei Produktlinien für einen bedürfnisorientierten Vertriebsansatz.
Defaults
Vor dem Hintergrund eines häufig geringen Produktwissens bieten sich sinnvolle Defaults an, um sowohl dem Kunden als auch dem Vertrieb die Entscheidung zu erleichtern.
Die geringen Zu- oder Abwahlraten haben grundsätzlich die geplante Tarifzusammenstellung belegt.
Aufgrund der vermehrten Zuwahl einzelner Leistungen und Produktlinien waren weitere Optimierungen bei der Zusammenstellung der Tarife möglich.
Aufgrund des Vergleichs von ungestützt erhobener Preisakzeptanz und faktischem Produktwert gemäss Tariftool empfahlen wir einen Baustein nicht in den Default zu integrieren.
Pricing Zusatzbausteine
Anhand der aktiven Zu- bzw. Abwahlraten bei den Zusatzbausteinen konnten je Baustein konkrete Preisempfehlungen ausgesprochen werden.
Auf diese Weise konnte die Preisakzeptanz der Kunden – jenseits der aktuell angesetzten, technischen Preise – deutlich besser abgeschöpft werden.
Die Steigerungen variierten zwischen 10% und 40% auf Ebene einzelner Bausteine.
Strategische Empfehlungen
Anhand der Ergebnisse aus dem Rahmenfragebogen sowie der qualitativen Vorstudie konnten weitere, grundlegende strategische Empfehlungen für einen erfolgreichen Vertriebsansatz abgeleitet werden.
Hierzu gehörte z. B. die Positionierung des Angebots über Use Cases, die den Kunden mit seinen Bedürfnissen direkter ansprechen als dies bisher bei den teilweise eher technisch dargestellten Leistungen der Fall ist.
Insgesamt sollte die Positionierung des Angebots verstärkt über Leistungsaspekte erfolgen, um das Thema Preis in den richtigen Kontext zu setzen.
Fazit
Preisoptimierungen mit Behavioral Economics bauen im Kern darauf auf, dass die Kunden in der Befragung möglichst dieselben Entscheidungsregeln anwenden wie in der Realität. Dies ist eine zentrale Voraussetzung für valide Ergebnisse bei einem so sensiblen Thema wie der Ableitung von Preisempfehlungen. In Bezug auf Motorfahrzeugversicherungen erfordert dies die Modellierung realistischer Prämien als Basis für die Erhebung realitätsnaher Wahlentscheidungen. Je nach Erkenntnisinteresse können unterschiedliche Produkt- und Preismonaden zur Ableitung von Optimierungsempfehlungen getestet werden. Gerade in reifen, wettbewerbsintensiven Märkten lassen sich mit diesem Ansatz noch Spielräume zur Abschöpfung der Preisakzeptanz auf Kundenseite konkretisieren.
Die Autorin Dr. Patricia Lüer ist Director bei intervista. Sie hat mehr als 25 Jahre Beratungs- und Marktforschungserfahrung in verschiedensten Branchen, B2B wie B2C. Ihr Fokus liegt auf der Analyse und Gestaltung komplexer Entscheidungsprozesse auf Grundlage verhaltensökonomischer Erkenntnisse.
Sich häufende Cyberattacken haben das Thema der Datensicherheit in den Fokus gerückt. Gleichzeitig handelt es sich bei der Datensicherheit um eine Vorgabe, die das Datenschutzgesetz an die Unternehmen stellt.
Die Datensicherheit ist Bestandteil des Datenschutzrechts und damit auch des Datenschutzgesetzes. Im aktuell noch geltenden Datenschutzgesetz (DSG) ist die Datensicherheit in Art. 7 DSG geregelt. Danach müssen Personendaten durch angemessene technische und organisatorische Massnahmen gegen unbefugtes Bearbeiten geschützt werden. Per September 2023 wird das revidierte Datenschutzgesetz (revDSG) in der Schweiz in Kraft treten.
Die dann massgebliche Vorschrift zur Datensicherheit ist Art. 8 revDSG. Die Vorschrift formuliert in Absatz 1 die Anforderungen an die Datensicherheit wie folgt: «Der Verantwortliche und der Auftragsbearbeiter gewährleisten durch geeignete technische und organisatorische Massnahmen eine dem Risiko angemessene Datensicherheit.». Abs. 2 hält fest, dass die Massnahmen es ermöglichen müssen, Verletzungen der Datensicherheit zu vermeiden. Darüber hinaus bestimmt Abs. 3, dass der Bundesrat Bestimmungen über die Mindestanforderungen an die Datensicherheit erlässt.
Dies erfolgt konkret mittels der Verordnung zum Datenschutzgesetz (VDSG). Die Revision des DSG erfordert eine Anpassung der VDSG. Davon sind auch die Regelungen über die Mindestanforderungen an die Datensicherheit betroffen. Die VDSG befindet sich daher aktuell in der Revision, es ist bisher ein Entwurf (E-VDSG) veröffentlicht und in die (nunmehr bereits abgeschlossene) Vernehmlassung geschickt worden.
Im Rahmen der Vernehmlassung äusserten Anwender wie Verbände, Kanzleien und Unternehmen erhebliche Kritik am E-VDSG. Insbesondere kritisierten sie, dass der bisherige Entwurf zu detaillierte und zu umfangreiche Vorgaben für Unternehmen, insbesondere für KMU, enthalte. Im Hinblick auf hier noch zu erwartende Ergänzungen und/oder Anpassungen durch den Gesetzgeber bleibt abzuwarten, welches Anforderungsniveau und welche konkreten Massnahmen zur Datensicherheit die revidierte VDSG (revVDSG) an Unternehmen stellt. Die aktuelle Entwicklung hierzu sollten die Fachverantwortlichen im Unternehmen genau beobachten.
Vorgaben an die Datensicherheit nach dem aktuellen DSG
Zentrale Vorgabe der gesetzlichen Regelung ist es, Personendaten gegen die unbefugte Bearbeitung zu schützen. Dabei hat der Schutz der Daten vor den Risiken einer unbefugten Bearbeitung durch angemessene organisatorische und technische Massnahmen zu erfolgen. Üblicherweise erfolgt eine Analyse potentieller Risiken und erforderlicher Massnahmen im Rahmen eines Datensicherheitskonzepts. Dieses ermöglicht eine gesamtheitliche Bewertung und Einordnung der ergriffenen Massnahmen. In der VDSG sind verschiedene technische und organisatorische Massnahmen umschrieben. Zu beachten sind insbesondere die Art. 8 bis 11 VDSG sowie die Art. 20 und 21 VDSG (für Bundesorgane).
Bereits erkennbare Vorgaben aus der Botschaft zum revDSG
In den Gesetzgebungsmaterialien zum revDSG sind grundsätzliche Überlegungen zu den Anforderungen an die Datensicherheit enthalten. Die Vorschrift des Art. 8 revDSG geht von einem risikobasierten Ansatz aus. Die Botschaft (Botschaft Totalrevision Datenschutzgesetz BBl 2017 7031) formuliert hierzu «Je grösser das Risiko einer Verletzung der Datensicherheit, umso höher sind die Anforderungen an die zu treffenden Massnahmen.» Darüber hält die Botschaft fest, dass sowohl Verantwortliche als auch Auftragsbearbeiter dazu verpflichtet sind, «für ihre Systeme eine geeignete Sicherheitsarchitektur vorzusehen und sie z. B. gegen Schadsoftware oder Datenverlust zu schützen».
Bereits jetzt empfohlene, ausgewählte Massnahmen zur Daten- und Cybersicherheit
Bereits jetzt empfehlen sich verschiedene Massnahmen zur Datensicherheit. Dabei kommen sowohl technische als auch organisatorische Massnahmen in Betracht, welche das Risiko eines erfolgreichen Cyberangriffs mindern. Nachfolgend werden einzelne, ausgewählte Massnahmen vorgeschlagen. Es ist zu beachten, dass es sich dabei nicht um eine abschliessende oder vollumfängliche Aufzählung aller potentiellen oder relevanten Massnahmen handelt.
Schulung und Sensibilisierung von Mitarbeitenden
Eine wesentliche organisatorische Massnahme stellt die hinreichende Schulung und Sensibilisierung der Mitarbeitenden dar. Der menschliche Faktor ist in einer Sicherheitsarchitektur häufig eine Schwachstelle. Der unzureichende Schutz von Zugangscodes, Passwörtern, Zugangsberechtigungen, usw. stellt ein potentielles Einfallstor für unbefugte Zugriffe dar. Entsprechende Schulung der Mitarbeitenden kann ein erhebliches Mass an Awareness für Risikosituationen und das richtige Verhalten schaffen.
Zugriffsberechtigungen
Wenn unternehmensintern über alle Stufen und Abteilungen hinweg weitgehende Zugriffsrechte auf sämtliche Informationen und Daten bestehen, wird dies häufig mit flachen Hierarchien und schnellen Entscheidungswegen gerechtfertigt. Unter dem Aspekt der Datensicherheit müssen indessen tatsächlich nur sehr wenige Mitarbeitende derart weitreichende Zugriffsrechte haben. Um Daten auch intern vor nicht erforderlichen Zugriffen und damit potentiellen Risiken zu schützen, wird empfohlen nur diejenigen Zugriffsrechte zu gewähren, die der Mitarbeitende für seine Tätigkeit auch tatsächlich benötigt. Zur Vermeidung der (unbeabsichtigten) Installation von Schadsoftware ist in diesem Zusammenhang überdies zu empfehlen, dass die Berechtigung zur Installation von Software nur sehr eingeschränkt vergeben wird und stattdessen den Mitarbeitenden ein verstärkter IT-Support zur Verfügung steht.
Aktualität der eingesetzten IT-Anwendungen
Schadsoftware nutzt häufig Lücken in veralteten Softwareanwendungen aus. Daher wird empfohlen die Betriebssysteme stets mit den aktuellen Updates/Sicherheitsupdates auf den neusten Stand zu bringen. Zugleich sind auch Browser und sonstige Softwareanwendungen im Hinblick auf die Aktualität ihrer Updates zu prüfen. Zudem sollten alle im Einsatz befindlichen Geräte, also nicht nur Laptops, sondern auch Mobiltelefone, Drucker, Tablets, usw. daraufhin kontrolliert werden, ob ihre Betriebssysteme und Sicherheitsupdates auf dem neusten Stand sind. Auch wenn Mitarbeitende eigene Geräte nutzen (BYOD), ist auf die Aktualität der Schutzmassnahmen zu achten. Schliesslich gilt es entsprechende Schutzsoftware (sog. Virenschutz) vorzuhalten und Firewalls zum Schutz des eigenen Systems zu aktivieren.
Verschlüsselung
Bei der Bearbeitung von wichtigen und/oder sensiblen Daten ist stets darauf zu achten, dass diese nur verschlüsselt gespeichert, übermittelt oder transportiert werden.
Vertragsmanagement
Im Zusammenhang mit der Bearbeitung und Auslagerung von Datenbearbeitungsvorgängen, beispielsweise indem Cloud-Dienstleister, (Online-)CRMs, Analyse-Tools usw., zum Einsatz kommen, ist stets die Frage nach der Wahrung der Sicherheit für die betroffenen Datensätze zu beachten. Hier kommen insbesondere vertragsrechtliche Regelungen mit der anderen Partei in Betracht. Diese regeln die einzuhaltenden Standards, beinhalten klare Vorgehensweisen bei Verstössen gegen die Datensicherheit, bestimmen Meldepflichten an den Vertragspartner und benennen Haftungsregeln, Verantwortungssphären usw. Darüber hinaus können Unternehmen vom Vertragspartner auch verlangen, dass er ein Sicherheitskonzept vorlegt. Wie die Einhaltung der vereinbarten Sicherheitsstandards kontrolliert wird oder werden kann, ist üblicherweise Teil des Vertrags zwischen dem Unternehmen und dem Partner, welcher Daten extern bearbeitet.
Weitere zusätzliche Regelungsinhalte werden dann erforderlich, wenn es sich um einen ausländischen Vertragspartner handelt. Hat dieser seinen Sitz darüber hinaus in einem Land, das kein gleichwertiges Datenschutzniveau bietet (vgl. hierzu die Länderliste des EDÖB), werden weitere vertragliche (u. a. Verwendung von Standardvertragsklauseln) und prozessuale (DTIAs = Data Transfer Impact Assessments; Risikoabschätzung hinsichtlich der geplanten Datentransfers) Massnahmen erforderlich, um die Datensicherheit hinreichend zu gewährleisten. Dies ist insbesondere im Fall von Datentransfer in die USA, bspw. bei Nutzung von US-Cloud-Dienstleistungen, Online-CRMs, usw., erforderlich.
Empfehlung
Die Datensicherheit ist eine zentrale datenschutzrechtliche Vorgabe, die im DSG wie auch dem revDSG festgehalten ist. Zur Umsetzung der Datensicherheit im Unternehmen empfiehlt es sich ein Sicherheitskonzept zu erstellen, das den rechtlichen Anforderungen entspricht und diese technisch umsetzt. Darüber hinaus kommt der vertraglichen Ausgestaltung zur Datensicherheit bei Datentransfers eine besondere Bedeutung zu. Hinsichtlich der neuen und konkretisierten Anforderungen an die Datensicherheit durch die revVDSG bleibt der Umfang der umzusetzenden Massnahmen abzuwarten. Diese Massnahmen lassen sich je nach Ausmass der Anforderungen indessen in ein bestehendes Sicherheitskonzept integrieren, so dass sich dessen Erstellung schon jetzt anbietet.
Der Autor Marcel Griesinger, Rechtsanwalt, Inhaber Rechtsanwaltskanzlei Griesinger, die auf Business Law und Corporate Privacy Law spezialisiert ist, Hochschuldozent Wirtschafts- und Datenschutzrecht
Customer lifetime value (CLV) is a key metric for every customer-centric marketer. Predicting the future value of a customer more accurately and reliably, would help to increase the marketing efficiency. Thus, its importance is widely acknowledged in industry and academia. But surveys show that CLV measurement is often a challenge in business practice. Retailers or other non-contractual businesses often fail to accurately predict customer purchase behavior. In particular, in the medium and long term.
Two reasons are key for this: (1) In non-contractual settings, customers do not formally announce when they will stop purchasing from a business. This contrasts contractual business settings such as insurance firms and poses a great challenge for modeling the future purchase behavior of customers. (2) Further, many businesses are subject to seasonal patterns. They experience for example a summer dip as many regular customers are on holidays or they observe significant increases related to special shopping events like Black Friday or Christmas.
The novel approach accounts for all these challenges and provides accurate and reliable estimates of the future value for each individual customer. Recent benchmarks also show that this probability-based approach not only provides better and more reliable prediction accuracy than machine learning approaches but is also faster to compute and does not require specialized computing infrastructure. By providing an accompanying open-source software, it is readily applicable for any business.
The novelty of the proposed approach is to include previously neglected, but from a practical point of view crucial, context variables in the statistical modeling. For the first time, it is possible to consider the effects of customer characteristics such as income and place of residence as well as dynamic effects such as shopping events. Although this seems logical and perhaps even overdue from a content point of view, the challenge lay in the statistical complexity that such an undertaking entails.
To guarantee reliability of the results across a wide variety of scenarios in corporate practice, this study considered data from three different industries. In addition, several alternative statistical models were calculated as benchmarks, this included widely used „rules of thumb“, established traditional statistical models and latest machine learning approaches. Furthermore, short-, medium-, and long-term forecast periods were considered to account for the widely varying planning horizons in practice. The added value of the proposed novel approach could thus be demonstrated over a broad database. The exemplary performance is shown in Figure 1.
Figure 1: Comparison of the aggregated performance of the extended Pareto/NBD Model with other approaches
How to use this novel approach as a data analyst
To make the application of this novel approach as easy as possible in practice, an open-source software called „CLVTools“ was developed (www.clvtools.com). CLVTools is a software package for the statistical programming environment R. Beyond the latest work presented here, CVLTools also includes implementations of further complementary and alternative modeling techniques to predict CLV. To date, this software has been downloaded more than 30,000 times.
In its simplest form, without considering any contextual factors, the estimation of CLV only requires a minimal amount of data. At its core, three input variables of customers purchase history are required. This data is available for any firm: a customer identifier (Id), the purchase date, and the purchase amount. Exemplary input data is shown in Table 1.
Table 1: Exemplary input data for the probabilistic modelling
Using the CLVTools package in R only three steps are required to predict customer lifetime value in simplest application case: • Step 1: Import the historical customer purchase data. • Step 2: Estimate the model parameters. • Step 3: Predict the customer purchase behavior. Figure 2 summarizes the workflow and avai-lable options of CLVTools.
Figure 2: Workflow for CLVTools
Multiple options to check and plot the data along this workflow are provided. Moreover, advanced model features and alternative model options are available. See https://www.clvtools.com/articles/CLVTools.html for a detailed walkthrough.
Marketing practice thus has a new, freely available tool at its disposal to better coordinate customer-centric marketing activities. Customer value as a central marketing metric is used in a variety of ways, e.g., to individualize coupons, to determine the most effective marketing channels or to allocate resources for win-back campaigns. An accurate calculation of the customer value based on our proposed approach helps to significantly improve the customer-specific personalization and thus the marketing efficiency.
Research Team
Patrick Bachmann (ETH Zurich) Markus Meierer (University of Geneva) Jeffrey Näf (ETH Zurich) Patrik Schilter (Crealytics GmbH)
Patrick Bachmann
Post Doctoral Researcher ETH Zurich
Markus Meierer
Assistant Professor of Marketing Analytics University of Geneva