Die Forschung zur visuellen Aufmerksamkeit hat durch Eye Tracking in den vergangenen Jahren einen substanziellen Entwicklungsschub erfahren. Mit der zunehmenden Relevanz von Künstlicher Intelligenz (KI) stellt sich die Frage, ob menschliche Probanden bei der Blickverlaufs-analyse künftig durch KI-basierte Vorhersagemodelle ersetzt werden können. Der vorliegende Beitrag beleuchtet das Potenzial und die Grenzen des «Predictive Eye Trackings», einem Verfahren, bei dem visuelle Aufmerksamkeit auf Basis trainierter Modelle prognostiziert wird – ohne das Testmaterial realen Personen vorzulegen.
Methodenüberblick: Wie messen wir visuelle Aufmerksamkeit?
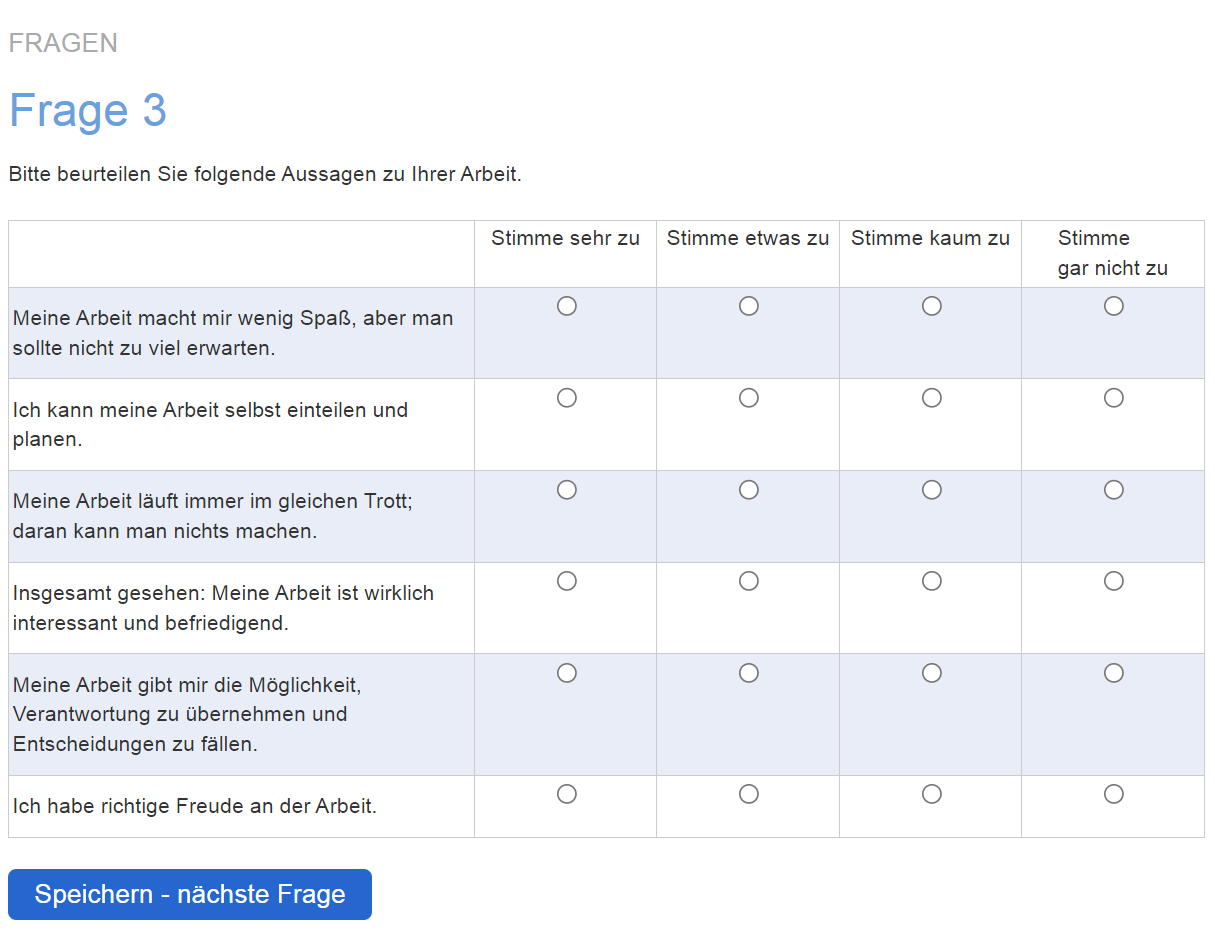
Zur Erfassung visueller Aufmerksamkeit stehen derzeit drei methodische Ansätze zur Verfügung, die sich hinsichtlich ihrer technischen Anforderungen, Datenqualität sowie Skalierbarkeit unterscheiden.
Eye Tracking mittels Brillenhardware Die klassische Eye Tracking-Brille liefert hochpräzise Messdaten (Abweichung von 0.5 – 1.5°). Die Messung erfolgt mit einer speziellen Brillenhardware über Infrarotsensoren und Kameras, welche z. B. Pupillenposition und -grösse, Fixationen (das Auge schaut für einen sehr kurzen Moment – ca. 100 bis 600 ms – auf einen Punkt, um visuelle Informationen bewusst aufzunehmen) sowie Augen- und Kopfbewegungen messen. Aufgrund der Mobilität der Hardware eignet sich diese Methode auch für Feldstudien, z. B. zur Analyse des Einkaufsverhaltens am Point of Sale (POS), wobei kontextuelle Einflussfaktoren wie die Umgebung oder Bewegungen einbezogen werden können. Der Nachteil liegt in der begrenzten Skalierbarkeit und den eher hohen Kosten aufgrund der notwendigen Hardware sowie der Rekrutierung realer Teilnehmender.
Webcam-basiertes Eye Tracking Diese Methode nutzt die integrierten Kameras gängiger digitaler Endgeräte wie Laptops oder Smartphones. Während ein visueller Stimulus (z. B. ein Werbemittel, Verpackungsdesign oder eine Website) präsentiert wird, werden die Blickbewegungen der Teilnehmenden über die Webcam aufgezeichnet. Die Messgenauigkeit ist im Vergleich zur Brille etwas geringer (Abweichung ca. 2 – 5°), kann jedoch durch die Nachbearbeitung mittels KI zumindest partiell kompensiert werden. Kontextfaktoren lassen sich einbeziehen, indem das Eye Tracking mit einer (Online-)Befragung kombiniert wird. So können Blickdaten und Selbstaussagen gemeinsam ausgewertet werden. Weitere grosse Vorteile liegen in der höheren Skalierbarkeit und in der Wirtschaftlichkeit. Allerdings ist auch hier die Rekrutierung realer Testpersonen erforderlich, häufig über Online-Panels, was neben den geringen Softwareaufwendungen zusätzliche Kosten verursacht.
KI-basiertes Predictive Eye Tracking Im Gegensatz zu den vorangehenden Methoden verzichtet Predictive Eye Tracking vollständig auf die Erhebung neuer Blickdaten. Stattdessen werden KI-Modelle auf Basis historischer Eye Tracking-Datensätze trainiert, um visuelle Aufmerksamkeitsverläufe auf neuen Stimuli vorherzusagen. Die prognostizierte Genauigkeit hängt wesentlich von der Qualität und Herkunft der Trainingsdaten, der verwendeten Modellarchitektur sowie der visuellen Komplexität der Stimuli ab. Kontextfaktoren wie Umgebungsbedingungen oder situationsabhängige Einflüsse können mit dieser Methode nicht erfasst werden. Ihr Hauptvorteil liegt jedoch in der extrem hohen Skalierbarkeit, den sehr geringen Kosten pro Analyse und der unmittelbaren Ergebnisverfügbarkeit – typischerweise innerhalb weniger Minuten.
Funktionsweise von Predictive Eye Tracking: Wichtige Kriterien bei der Wahl eines Anbieters
Die Aussagekraft der Vorhersagen von Predictive Eye Tracking hängt wesentlich von der Datenbasis, der Modellarchitektur und der Transparenz der Anbieter ab:
Input: Qualität der Trainingsdaten Die Validität eines Predictive Eye Tracking-Modells ist stark abhängig von der Qualität, Repräsentativität und Herkunft der Trainingsdaten: • Kulturkreis: Die Übertragbarkeit der Modelle auf spezifische Zielmärkte erfordert, dass Trainingsdaten aus einem vergleichbaren Kulturkreis stammen. So sind z. B. asiatische Blickmuster nur bedingt auf europäische Kontexte übertragbar. • Messmethode: Daten aus Brillen-basiertem Eye Tracking sind in der Regel präziser als solche aus Webcam-Messungen. Modelle, die auf ungenaueren Quellen basieren, können systematische Abweichungen reproduzieren – selbst wenn nachträgliche KI-Korrekturen erfolgen. • Anwendungskontext: Die Relevanz der Trainingsdaten hängt vom späteren Einsatzzweck ab. Für Fragestellungen im Marketing sind Datensätze aus Consumer Research relevanter als solche aus medizinischen oder sicherheitstechnischen Studien (z. B. Fahr-assistenzsysteme).
Modellqualität Beim Predictive Eye Tracking kommen KI-Modelle zum Einsatz, die aus vorhandenen Blickdaten lernen und zukünftige Fixationen vorhersagen. • Modellwahl: Je nach Zielsetzung kommen unterschiedliche KI-Modelle zum Einsatz – von klassischen Machine-Learning-Verfahren bis hin zu komplexen neuronalen Netzwerken oder Hybridmodellen. Je nach Anwendungsfall haben diese Modelle andere Stärken und Schwächen. • Datenpunkte: Eine hohe Anzahl von Datenpunkten ist nicht zwangsläufig ein Qualitätsmerkmal. Entscheidend ist, was als Datenpunkt definiert ist und wie viele reale Teilnehmende den zugrunde liegenden Datensatz gebildet haben. Einige Anbieter blähen die Eye Tracking-Daten mit externen Daten, z. B. mit Industry-Benchmarks, auf, was zwar die Datenmenge erhöht, aber nicht unbedingt die Modellgüte verbessert.
Output: Vergleichbarkeit Typische Outputs von Predictive Eye Tracking Tools sind Vorhersagen von zukünftigen Blickpositionen (Koordinaten), Fixationen und Sakkaden (schnelle Bewegungen zwischen Fixationen, in denen keine Information aufgenommen wird), welche meist in Heat- und Fokus-Karten zusammengefasst werden. Manche Anbieter berechnen eigene KPIs, welche innerhalb der Tools, nicht aber über verschiedene Tools oder Methoden hinweg vergleichbar sind.
Transparenz schafft Vertrauen Viele Anbieter machen zentrale Informationen zur Herkunft der Trainingsdaten, Modellstruktur oder Validierung nicht öffentlich zugänglich. Dies erschwert eine informierte Bewertung der Vorhersagequalität. Transparente Anbieter, die z. B. Validierungen über unabhängige Benchmarks wie das MIT Saliency Benchmark offenlegen, schaffen hier Vertrauen.
Empirische Überprüfung: Ein Use Case mit Hilcona
GIM Suisse hat gemeinsam mit Hilcona zwei Videospots getestet. Verglichen wurden die Ergebnisse aus Predictive Eye Tracking (Tool: Attention Insight) und Webcam-basiertem Eye Tracking (Tool: RealEye).
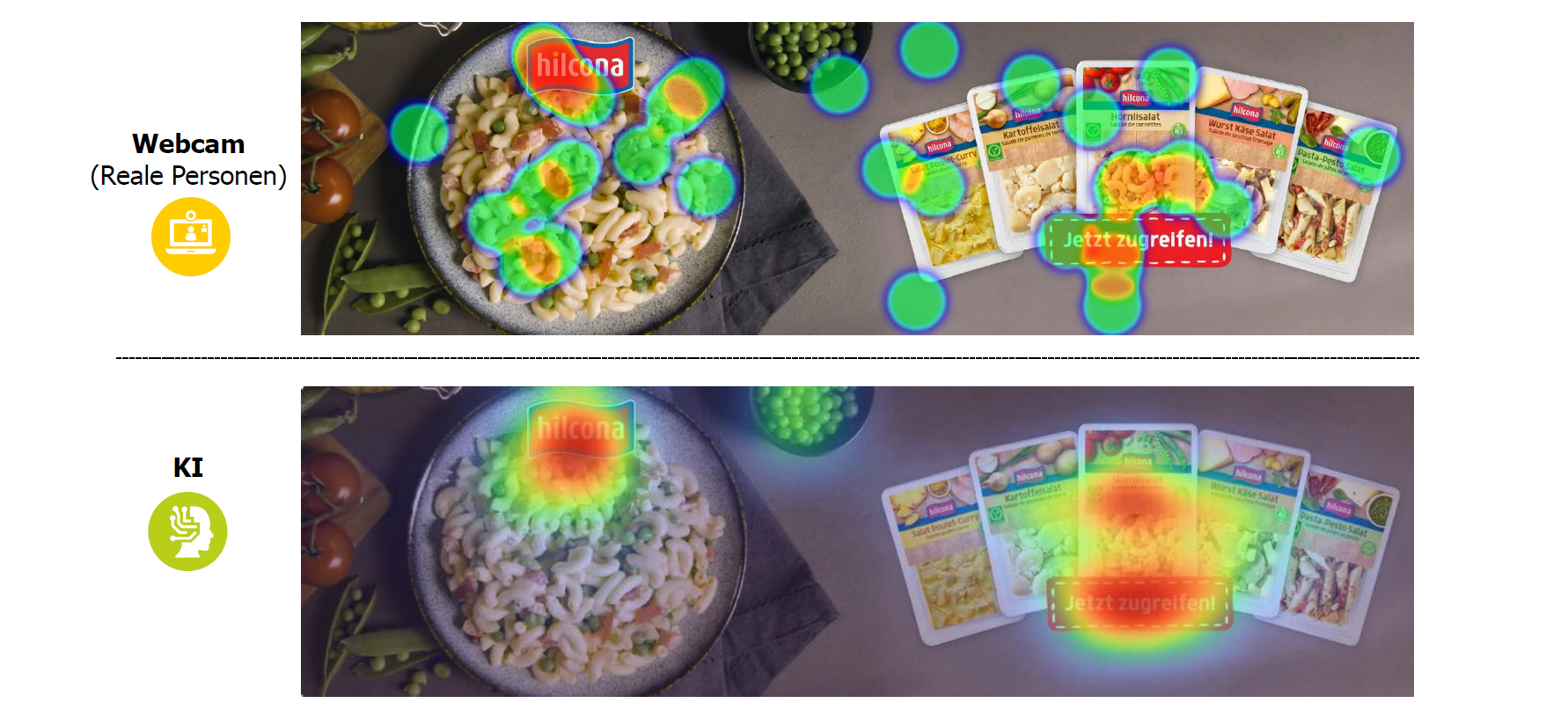
Ergebnisvergleich Abbildung 1: Die realen Messdaten zeigten eine breite Streuung der Aufmerksamkeit, inklusive peripherer Elemente wie Produktvarianten. Die KI-Vorhersage hingegen fokussierte stärker auf zentrale Designelemente (Logo, Call to Action).
Abbildungen 2 & 3: Ein weiteres Beispiel, bei dem der Stimulus Menschen und Gesichter beinhaltet, zeigt, dass bei beiden Methoden der Fokus initial auf Gesichtern liegt bzw. vorhergesagt wird (Abbildung 2). Während reale Personen bei einem nachfolgenden Bildwechsel ihren Blickverlauf flexibel auf das neu eingeblendete Produkt umleiteten (Abbildung 3), blieb die KI-Prognose weiterhin dominant auf das Gesicht fokussiert – ein Hinweis auf potenzielle Übergewichtung einzelner Merkmale durch das Modell («overfitting» auf Gesichter).
Abbildung 1Abbildung 2
Bildwechsel
Abbildung 3
Potenziale und Grenzen
Die Analyse der Anwendungsbeispiele zeigt, dass KI-basierte Modelle in der Lage sind, zentrale visuelle Aufmerksamkeitsbereiche (Hotspots) mit hoher Zuverlässigkeit zu prognostizieren. In der Darstellung wirken die resultierenden Aufmerksamkeitskarten oft klar strukturiert und visuell fokussiert. Allerdings weisen sie im Vergleich zu real gemessenen Blickverläufen eine geringere Differenzierung auf: Während reale visuelle Exploration durch Mikrobewegungen, Kontextwechsel und periphere Wahrnehmung geprägt ist, tendieren KI-Vorhersagen zur Reduktion auf dominante Muster – was zu einer vereinfachten, mitunter unvollständigen Abbildung der tatsächlichen visuellen Aufmerksamkeit führt.
Potenzial • Effizienz: Schnelle und kosteneffiziente Analyse visueller Stimuli • Skalierbarkeit: Gut geeignet für frühe Entwicklungsphasen (z. B. Design, Verpackung, Werbematerial) • Objektive Ergänzung: Ergänzt qualitative und quantitative Methoden um eine objektive, datenbasierte Ebene zur Analyse visueller Aufmerksamkeit
Grenzen • Geringere Differenzierung als reale Blickverläufe: Feinheiten realer visueller Exploration (Mikrobewegungen, Randwahrnehmung) werden oft nicht erfasst. • Tendenz zur Vereinfachung: Nuancen und Kontextinformationen bleiben unberücksichtigt. • Modellverzerrung durch Training: Überrepräsentation bestimmter Stimulusarten (z. B. Gesichter, Text) kann zu systematischen Bias führen. • Fehlende Kausalität: Predictive Eye Tracking zeigt, wo Aufmerksamkeit entsteht – nicht warum. Die Interpretation bleibt hypothesenbasiert.
Sibylle Oetiker Senior Research Manager bei GIM Suisse AG
Sibylle Oetiker ist Soziologin und Kommunikationswissenschaftlerin und hat Erfahrung in der Marktforschung, im Marketing und in der strategischen Beratung auf Instituts- und Kundenseite sowie im wissenschaftlichen Umfeld. Sie ist zudem Gründerin eines nachhaltigen Startups.
In einer Welt, die zunehmend von Daten und Technologie geprägt ist, erweitert generative KI (AI) die Instrumente der Marktforschung grundlegend. Ähnlich zu digitalen Zwillingen physischer Objekte simulieren KI-basierte Zwillinge heute Kund:innenpräferenzen und -verhalten in realitätsnahen Szenarien. Angetrieben von grossen Sprachmodellen (Large Language Models, LLMs) entstehen AI-Twins, die sich darauf auswirken, wie Unternehmen Konsument:innenbedürfnisse verstehen und analysieren. Diese Zwillinge liefern nicht nur tiefere Einblicke in simulierte Eins-zu-eins-Interviews, sondern auch Ergebnisse innerhalb von Minuten, selbst bei grossangelegten Umfragen oder A/B-Tests.
Wer AI-Twins gezielt einsetzt, reagiert schneller auf Marktveränderungen, passt Strategien flexibel an und sichert sich so einen nachhaltigen Wettbewerbsvorteil.
Unternehmen sehen sich heute mit einer enormen und stetig wachsenden Menge an Daten konfrontiert. Diese reichen von Kund:inneninteraktionen und Transaktionen bis hin zu vielfältigen digitalen Touchpoints, Marktstudien und Social-Media-Analysen. Gleichzeitig wächst der Druck auf schnelle Entscheidungen und agile Anpassungen in der Produktentwicklung, beim Marketing oder in der strategischen Planung.
Traditionelle Marktforschungsmethoden erreichen hier ihre Grenzen: Sie sind oft langsam sowie kostenintensiv und erlauben meist nur begrenzte Hypothesentests. Umfragen, Interviews und klassische Feldstudien liefern zwar wertvolle Einsichten, sind aber häufig zeitaufwendig und dadurch wenig agil. Hinzu kommt, dass reale Experimente – etwa zur Produktvalidierung, Werbemitteloptimierung oder Preisgestaltung – teuer sind und nicht immer wiederholt oder in grösserer Zahl durchgeführt werden können.
Genau hier setzen AI-Twins an. Sie ermöglichen Unternehmen, Kund:innenpräferenzen und -verhalten zu simulieren, sodass Hypothesen schnell, kosteneffizient und in hoher Frequenz getestet werden können. Anstatt aufwendig reale Studien oder Feldversuche zu organisieren, bieten AI-Twins die Möglichkeit, potenzielle Marktreaktionen, Produktfeatures oder Werbebotschaften unmittelbar und in grosser Breite digital zu prüfen.
Was steckt hinter einem AI-Twin?
Ein AI-Twin ist eine digitale, KI-basierte Replik einzelner Konsument:innen oder ganzer Zielgruppen. Er beruht auf synthetischen Daten, die reale Einstellungen, Präferenzen und Verhaltensweisen nachbilden. Dabei werden sogenannte synthetische Antworten («Synth-Responses») generiert, die reale Interaktionen und Wahrnehmungen von Kund:innen simulieren.
Konkret gehen AI-Twins über Predictive Analytics hinaus: Sie sagen nicht nur Ergebnisse voraus, sondern stellen individuelle Verhaltensweisen realitätsnah nach. Diese Zwillinge entstehen aus umfangreichen Datensätzen, die entweder direkt aus bestehenden Kund:inneninformationen oder aus idealtypischen Zielgruppenprofilen gewonnen werden. Dadurch können Unternehmen Szenarien durchspielen, die sonst aufwendig oder sogar unmöglich zu testen wären.
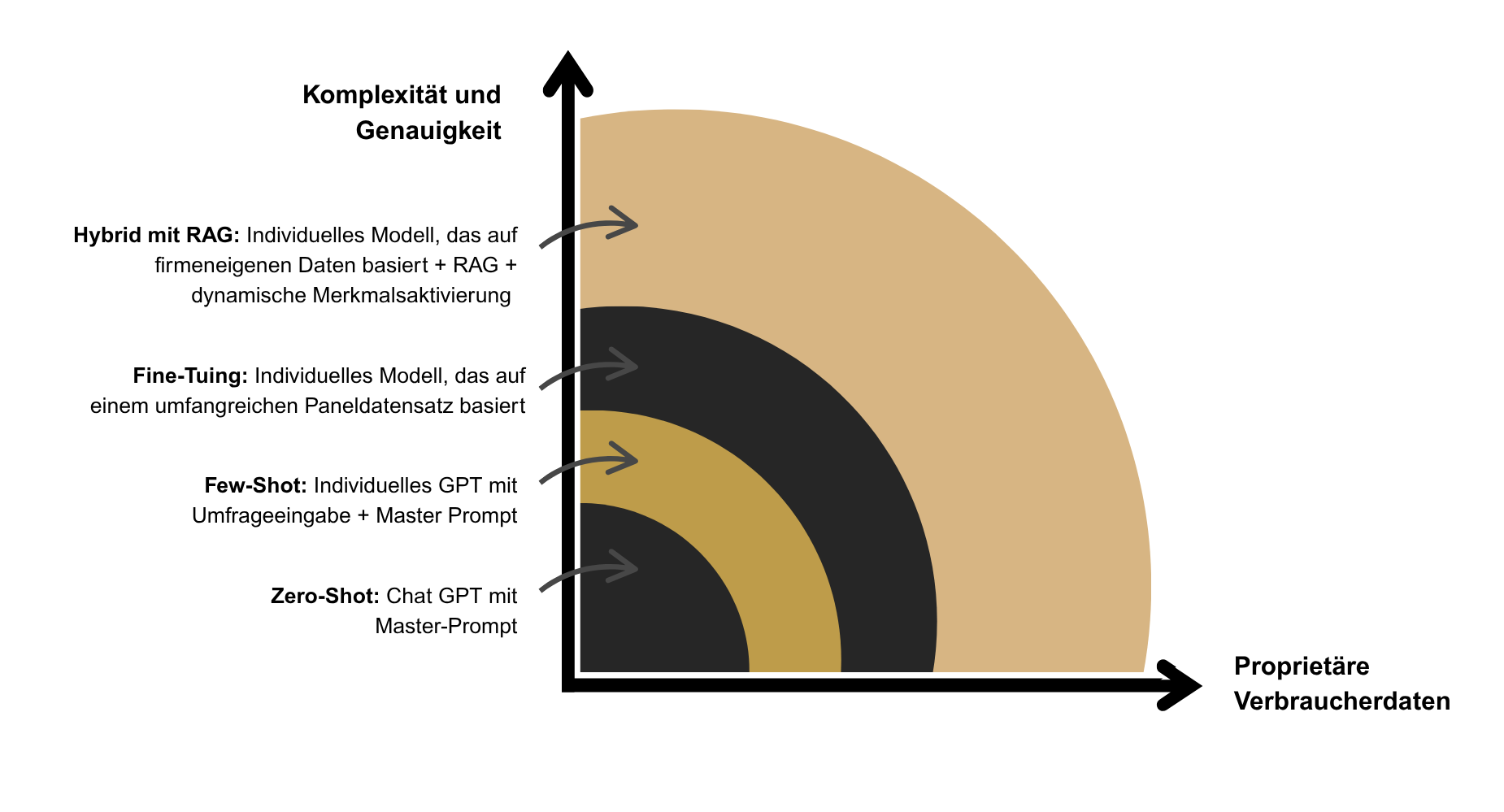
Wie realitätsnah und valide die Ergebnisse dieser digitalen Zwillinge tatsächlich sind, hängt dabei entscheidend von der gewählten Methode und dem Setup ab. Aktuell bieten Anbieter am Markt unterschiedliche Ansätze, deren Aussagekraft erheblich variiert. Im Folgenden unterscheiden wir vier wesentliche Methoden, sortiert nach steigender Realitätsnähe und Aussagekraft (siehe Abbildung 1):
Hybride Methode – Integration von Retrieval-Augmented Generation (RAG) (Höchste Validität) Die anspruchsvollste und zugleich realitätsnächste Methode kombiniert Fine-Tuning mit einem dynamischen Abrufsystem (RAG). Dieses System integriert in Echtzeit relevante Studien, aktuelle Marktforschungsergebnisse und zusätzliche Kontextinformationen. AI-Twins können somit hochaktuell, flexibel und äusserst realitätsgetreu individuelle Reaktionen und Marktverhalten simulieren. Diese Methode liefert die grösste Validität und Aussagekraft.
Zero-Shot Prompting (Basis-Level) Die einfachste Methode: Hier wird lediglich eine Persona (z. B. demografische Merkmale) in einem Prompt beschrieben. Die KI generiert Antworten basierend auf allgemeinen Trainingsdaten. Die Ergebnisse wirken intuitiv plausibel, aber oft generisch. Sie eignen sich vor allem für grobe Ideation oder erste schnelle Tests, nicht jedoch für präzise Prognosen.
Few-Shot Prompting – In-Context-Learning (Erhöhte Validität) Diese Methode ergänzt den Persona-Prompt um konkrete Beispiele aus vergangenen Studien oder realen Kund:inneninteraktionen. Die AI-Twins profitieren so von explizitem Kontextwissen. Die Ergebnisse werden präziser und glaubwürdiger, allerdings hängen Qualität und Konsistenz stark von der Anzahl und Güte der Beispiele ab.
Fine-Tuning auf Unternehmensdaten (Hohe Validität) Hier wird das LLM gezielt mit historischen, firmenspezifischen Kund:innendaten trainiert. Dadurch entstehen AI-Twins, die das tatsächliche Konsument:innenverhalten spezifischer Zielgruppen realistischer und zuverlässiger abbilden. Die Validität der Ergebnisse ist hoch und erlaubt eine deutlich präzisere Marktsimulation.
Abb. 1: Aussagekraft und Realitätsnähe verschiedener Methoden
Einsatzfelder von AI-Twins
Aktuelle Forschungsarbeiten bestätigen die beeindruckende Leistungsfähigkeit von AI-Twins – sowohl in der qualitativen als auch quantitativen Marktforschung. Dabei überwinden AI-Twins bisherige methodische Grenzen und ermöglichen einen Paradigmenwechsel in der Gewinnung von Consumer Insights.
Qualitative Forschung: Skalierung und vertiefte Einsichten Qualitative Studien, etwa Tiefeninterviews oder Fokusgruppen, galten bisher als aufwendig und kaum skalierbar. AI-Twins verändern dies grundlegend. Mittels KI können Hunderte oder sogar Tausende von individualisierten Interviews durchgeführt werden. Dabei liefert KI nicht nur Antworten, sondern agiert eigenständig als Interviewerin: Sie stellt relevante Nachfragen und vertieft Themen gezielt. Ein Vorgehen, das bislang erfahrenen menschlichen Interviewer:innen vorbehalten war.
Diese automatisierte Interviewführung erlaubt erstmals grossangelegte qualitative Studien, ohne dabei die zentralen Stärken qualitativer Methoden – Tiefe, Kontextverständnis und exploratives Vorgehen – einzubüssen. Im Gegenteil. Aktuelle Forschungsstudien zeigen sogar, dass KI-generierte Interviews hinsichtlich Antworttiefe und Erkenntnisgewinn menschlichen Interviews überlegen sein können. Zusätzlich ermöglichen AI-Twins, gezielt vielfältige und diversere Stichproben zu simulieren und dadurch bislang unterrepräsentierte Zielgruppen präziser abzubilden.
Quantitative Forschung: Schnelle und zuverlässige Vergleiche Auch quantitative Forschung profitiert massgeblich von der Geschwindigkeit und vom Umfang der AI-Twin-Studien. Besonders wirkungsvoll sind vergleichende quantitative Studien, wie etwa A/B-Tests zur Kampagnen- oder Message-Optimierung oder zur Evaluation von Produktkonzepten. Digitale Zwillinge erlauben dabei umfassende, präzise und zügig durchgeführte Tests verschiedenster Szenarien, auf deren Basis Marketing- und Produktentscheidungen deutlich schneller und fundierter getroffen werden können. Die Validität und Aussagekraft der KI-generierten Ergebnisse hängt jedoch entscheidend von der gewählten Methode ab. Durch den Einsatz gezielter Techniken wie Few-Shot-Learning, Fine-Tuning auf unternehmensspezifischen Daten und insbesondere Retrieval-Augmented Generation (RAG), die Echtzeitinformationen dynamisch integriert, steigen Varianz und Zuverlässigkeit synthetischer Daten enorm an.
Verschmelzung qualitativer und quantitativer Methoden
Ein besonders spannender Mehrwert liegt in der engen Verzahnung qualitativer und quantitativer Methoden, die AI-Twins ermöglichen. Qualitative AI-Twin-Studien liefern beispielsweise tiefgehende initiale Einsichten zu Motiven und Einstellungen. Diese Erkenntnisse können anschliessend quantitativ validiert und ausgeweitet werden. Beispielsweise können mithilfe quantitativer AI-Twin-Studien generierte Hypothesen und Produktideen grossangelegt getestet und so valide und belastbare Insights gewonnen werden.
Zudem erlaubt die Generierung synthetischer Daten durch LLMs eine zuverlässige Vorhersage klassischer Umfrageergebnisse. Auf diese Weise können potenzielle Probleme und Schwachstellen traditioneller Marktforschungsinstrumente wie Fragebogen bereits vor der Feldphase identifiziert und behoben werden. Dies führt zu einer agileren, datengetriebenen Marktforschung, die Unternehmen erlaubt, schneller auf Marktveränderungen zu reagieren und ihre Strategien dynamisch anzupassen.
Worauf bei der Auswahl von AI-Twins zu achten ist
Die Qualität der gewonnenen Insights hängt wesentlich vom Setup der AI-Twins ab. Um valide, verlässliche und praxisrelevante Ergebnisse sicherzustellen, sollten Unternehmen insbesondere die folgenden drei Aspekte beachten:
Echtzeitfähigkeit und dynamische Anpassbarkeit (RAG) • RAG-Systeme und Echtzeit-Integration: AI-Twins, die aktuelle Informationen, Studien oder Marktforschungsergebnisse dynamisch einbeziehen, liefern realistischere und aktuelle Ergebnisse. Für das Unternehmen relevante Marktentwicklungen, Wettbewerbsinformationen oder Konsumententrends werden unmittelbar berücksichtigt, was zu deutlich relevanteren und verlässlicheren Insights führt.
Qualität und Kontextintegration der Daten • Breite und Qualität der Datenbasis: Eine hochwertige Integration vielfältiger Datenquellen (z. B. CRM-Daten, Transaktionen, Social Media) verbessert massgeblich die Aussagekraft und Relevanz der simulierten Insights. • Konsequente Kontextintegration: Modelle, die frühere Interaktionen («In-Context-Learning») systematisch einbeziehen, gewährleisten eine höhere interne Konsistenz der Antworten und realistischere Insights.
Modellwahl: Kommerziell vs. Open-Source • Kommerzielle Modelle (z. B. GPT-4) wurden mit umfangreichen Datenmengen trainiert, werden in regelmässigen Abständen upgedatet und erreichen in Benchmark-Studien konstant zuverlässige Resultate. Ein Nachteil ist jedoch die höhere Kostenstruktur. • Open-Source-Modelle (z. B. LLaMA, Mistral) ermöglichen eine höhere Kontrolle, erreichen aktuell jedoch noch nicht die gleiche Realitätsnähe.
Fazit: Nicht das «Ob», sondern das «Wie» zählt
AI-Twins verbinden qualitative und quantitative Forschung zu einem agilen, datengetriebenen Ansatz. Entscheidend sind Datenqualität, Modellwahl und dynamische Anpassbarkeit. Unternehmen, die diese Faktoren berücksichtigen, gewinnen schnellere, tiefere und valide Insights – ein klarer Wettbewerbsvorteil im dynamischen Marktumfeld.
Anne Scherer (Dr., ehemalige Assistenzprofessorin für Quantitatives Marketing an der Universität Zürich) ist Mitgründerin von Delta Labs, einem UZH-Startup, das sich auf innovative KI-Lösungen für Marketers spezialisiert hat – insbesondere auf AI-Twins zur datengetriebenen Optimierung von Marketingstrategien und Kund:innenverständnis.
Quantitative Marktforschung bietet uns belastbare Antworten auf das Was – psychometrisches Profiling ergänzt dieses Wissen um das Warum. Warum kaufen Menschen? Warum reagieren sie auf bestimmte Botschaften, Produkte oder Kanäle? Und warum entscheiden sie sich manchmal trotz klarer Faktenlage anders als erwartet? Dabei geht es um grundlegende Persönlichkeitsmerkmale, die einen Menschen auf allen Ebenen seines Denkens, Fühlens und Handelns steuern.
Genau hier setzt das psychologische Profiling-Framework von Brandmind an. Es basiert auf dem empirisch entwickelten ASPECTS-Modell, das in Kooperation mit der Zürcher Hochschule für Angewandte Wissenschaften (ZHAW) entstanden und von Innosuisse gefördert worden ist. Ziel ist es, die psychologischen Treiber menschlichen Verhaltens zu entschlüsseln und nutzbar zu machen – für bessere Kommunikation, präzisere Segmentierung und erlebnisorientierte Customer Journeys.
Abb.1: Wissenschaftlicher Beweis: Signifikante Korrelation zwischen Werbepräferenzen & Persönlichkeit
Das ASPECTS-Modell: Tiefer blicken, gezielter handeln
Die Funktionen von Personas:
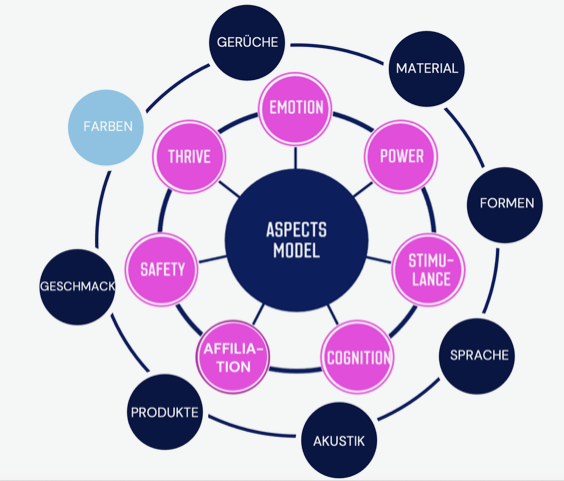
Das Modell unterscheidet sieben zentrale psychologische Grundmotive:
Affiliation (Zugehörigkeit)
Stimulation (Neugier, Abwechslung)
Power (Macht)
Emotion
Cognition (Rationalität)
Thrive (Leistung)
Sicherheit (Safety)
Diese Dimensionen bilden die Basis für eine differenzierte Ansprache, die weit über demografische oder verhaltensbasierte Cluster hinausgeht. Marken können so nicht nur segmentieren, sondern gezielt motivbasierte Resonanz erzeugen.
Die Umsetzung des Modells erfolgt an allen Kunden-Touchpoints – von Bildsprache über Materialwahl bis hin zu Geruch und Tonalität. Die folgende Visualisierung zeigt, wie die ASPECTS-Dimensionen mit Sinneskanälen verbunden werden können.
Abb.2: Das wissenschaftlich entwickelte ASPECTS-Modell mit Sinneskanälen
Vom Datensilo zur Dialogkultur
Psychometrisches Profiling verändert den Umgang mit Daten grundlegend. Es geht nicht länger um das Sammeln möglichst vieler Informationen, sondern um eine ethische, transparente und wirksame Nutzung bestehender Daten – mit dem Ziel, echte Interaktion zu ermöglichen. Das Modell fordert ein neues Denken im Customer Experience Management: Weg von generischen Funnels, hin zu einem orchestrierten, emotional intelligenten Dialog mit den Menschen hinter den Daten. Dazu braucht es die richtige technologische Infrastruktur, eine neue Art der Segmentlogik und vor allem ein klares Verständnis psychologischer Muster. Marken, die diesen Weg gehen, transformieren nicht nur ihre Kommunikation, sondern ihr gesamtes Kundenverständnis.
Psychometrisches Profiling in der Praxis
Psychometrisches Profiling ist heute vielseitig einsetzbar. Vier typische Anwendungsfälle können identifiziert werden:
Profiling & Targeting: Bestehende Kundendaten lassen sich durch psychologische Merkmale bzw. das psychologische Profil der Kund:innen anreichern – datenschutzkonform und qualitativ hochwertig. So entstehen Zielgruppenprofile, die nicht nur beschreiben was, sondern auch warum etwas wirkt. Wer reagiert etwa besonders auf das Thema Zugehörigkeit – wer auf Leistung oder auf Kontrolle? (siehe das praktische Beispiel «AMAG» weiter unten)
Marketing & Kreation: Basierend auf den psychologischen Profilen können kreative Umsetzungen entwickelt werden, die exakt auf die Bedürfnisse der Zielgruppen zugeschnitten sind – in Bildwelten, Sprache und Tonalität. Die Wirkung: mehr Relevanz, mehr Conversion, mehr Vertrauen.
Marktforschung: Psychometrisches Profiling ergänzt klassische quantitative und qualitative Methoden durch emotionale Tiefe. Einstellungen, Wertelandschaften und Motivstrukturen werden sichtbar und eröffnen neue Möglichkeiten für fundierte Segmentierungen und differenzierte Insights. (siehe Beispiel «QoQa» weiter unten)
Produktentwicklung & CX-Design: Ob in der Gestaltung von Nutzererlebnissen oder digitalen Services – wer psychologische Profile berücksichtigt, kann Erlebnisketten schaffen, die nicht nur logisch, sondern auch emotional kohärent sind. Das Ergebnis: höhere Akzeptanz, stärkere Markenbindung.
Abb. 3: Unterschiedliche Ansprache für das gleiche Thema führt zu mehr Impact in den KPIs (Beispiel Newsletter)
Ein Beispiel aus dem AMAG-Projekt zeigt, wie sich psychologische Zielgruppenprofile auf die kreative Umsetzung auswirken können. Links ein klassischer, rationaler Ansatz – rechts eine gezielte, profilbasierte Ansprache auf Basis der Dimension Stimulanz.
Case AMAG: 50 % höhere Conversion durch psychologische Zielgruppenprofile
Für AMAG wurden bestehende Kundendaten mit dem ASPECTS-Modell angereichert. Ziel war es, die Relevanz der Kundenkommunikation zu steigern. Das Ergebnis: psychologische Zielgruppenprofile, die Verhalten, Demografie und Produktinteressen in einem konsistenten Bild integrieren.
Auf Basis dieser Profile wurden neue Kommunikationsstrategien entwickelt. Der Impact war signifikant: Die Conversion Rates der Marketing-Newsletters stiegen um bis zu 50 %. Gleichzeitig veränderte sich die interne Perspektive – die Relevanz «weicher» Daten wurde mess- und sichtbar.
Case QoQa: Klares Zielgruppenverständnis für gezieltere Ansprache
QoQa ist eine Westschweizer Online-Einkaufplattform, die sorgfältig ausgewählte Produkte und Erlebnisse anbietet. Das Expert:innenteam findet kontinuierlich Shopping-Perlen, jeden Tag gibt es neue, exklusive und limitierte Angebote. QoQa ist zudem eine aktive Community, die sich intensiv untereinander und mit den Expert:innen zu den Angeboten austauscht und sich zu Offline-Events trifft.
Hier ging es darum, häufig online shoppende Menschen der französischen und deutschen Schweiz jenseits der Soziodemographie zu profilieren, um Gemeinsamkeiten und Unterschiede zwischen den Sprachregionen sowie zwischen bestehenden Kund:innen und Nichtkund:innen besser zu verstehen.
Die Hypothese stand im Raum, dass sich Romands und Deutschschweizer Online-Shopper bezüglich ihrer Persönlichkeits- und Motivstruktur unterscheiden. Dies zeigte sich deutlich in den Ergebnissen: Westschweizer Online-Shopper und insbesondere bestehende QoQa-Kund:innen sind deutlich stimulanz- und affiliationsorientierter als die Deutschschweizer Konsument:innen, weshalb QoQa mit ihrem Konzept täglich neu erscheinender Angebote quasi offene Türen eingerannt hat. Dieses Profil hat sich in etwas weniger deutlicher Ausprägung auch bei Deutschschweizer QoQa-Kunden bestätigt.
Interessant war, dass bei Deutschschweizer Nichtkund:innen, dem zahlenmässig grössten Potenzial, das Profil «Emotion» vorherrscht. Das bedeutet, dass die Nichtkund:innen empfänglich für emotionale Inhalte sind. Sie haben tendenziell stärkere emotionale Empfindungen, sind sensibler für emotionale Inhalte und reagieren emotionaler auf ihre Umwelt als die anderen Shopper-Typen.
Diese wertvollen Erkenntnisse stellen die Basis dar, um die Kommunikation für Online-Shopper:innen der Deutsch- und Westschweiz noch gezielter zu gestalten.
Fazit: Mehr Mensch. Mehr Wirkung.
Psychometrisches Profiling ersetzt keine bestehenden Methoden – es erweitert sie dort, wo herkömmliche Modelle an ihre Grenzen stossen. Nämlich dann, wenn es um emotionale Relevanz, Differenzierung und ethisch fundierte Kommunikation geht.
Gerade in datengetriebenen Zeiten ist es entscheidend, den Menschen hinter den Daten zu erkennen. Wer seine Kund:innen wirklich versteht, schafft Vertrauen – und Vertrauen ist der nachhaltigste Wettbewerbsvorteil der Zukunft.
Christina Hoffmann (Diplom-Kauffrau & Executive MBA, CAS Positive Psychology, Studiengangsleiterin und Dozentin an der HWZ) ist Gründerin und CEO von Brandmind – der ersten Unternehmensberatung in der Schweiz, die psychometrisches Profiling, angewandte Verhaltenspsychologie und ethisches Marketing auf höchstem Niveau verbindet.
Alexander Lorenz ist Sozialpsychologe und Inhaber/CEO der Qualitest AG, einer Marktforschungsboutique, die mit der Kombination aus klassischer Marktforschung und verhaltenspsychologisch fundierter Segmentierung tiefere Insights generiert.
Personas entstanden im späten 19. Jahrhundert als soziologisches Instrument zur Darstellung der Merkmale bestimmter Bevölkerungsgruppen. Max Weber (1864-1920), Pionier und Gründer dieses Konzepts, betonte, dass der Zweck von Personas darin besteht die strategischen Aspekte (manchmal übertrieben) zu verkörpern und zum Leben zu erwecken, die berücksichtigt werden müssen, um wirksame Entscheidungen zu treffen. Mit der Zeit wurden Personas in der Marktforschung eingesetzt, um die Motivationen und Erwartungen der Menschen besser zu verstehen. In den 1980er Jahren wurden Personas in der UX-Forschung genutzt, um die Diskrepanz zwischen Designvorhaben und Benutzer:innen-Anforderungen zu überbrücken. In der Folge setzten Marketing- und Strategieabteilungen Personas ein, um Käufergruppen zu definieren und bestimmte Profile anzusprechen.
Die Funktionen von Personas
Die Funktionen von Personas:
Eine Persona repräsentiert eine Kundengruppe durch ein psychologisches und verhaltensbezogenes Profil. Sie fördert das Verständnis dieser Gruppe und gestaltet die Ergebnisse für die Nutzerin oder den Nutzer möglichst handlungsorientiert. Personas haben sich im Laufe der Jahre weiterentwickelt und erfüllen mehrere wichtige Funktionen:
Kreativität anregen: Personas erfassen Emotionen und Standpunkte und regen so innovatives Denken und kreative Lösungen an.
Daten zum Leben erwecken: Personas vermenschlichen abstrakte Daten und schaffen eine Diskussionsplattform, die als Ausgangspunkt für Co-Creation und iterative Entwicklung dient.
Internes Abstimmen von Teams: Personas sorgen für ein einheitliches Verständnis der Zielgruppen im gesamten Unternehmen und vereinfachen die Kommunikation.
Begrenzen von Risiken: Personas bieten einen sicheren Rahmen, um Ideen zu testen und zu verfeinern, Entscheidungen zu dokumentieren und die Übereinstimmung mit den tatsächlichen Bedürfnissen der Kundinnen und Kunden sicherzustellen.
Der Aufstieg von KI und Persona-Bots
Mit dem technologischen Fortschritt sind Personas ausgefeilter geworden und beinhalten nun auch KI-gesteuerte Tools. Diese Entwicklung hat zur Erstellung von Persona-Bots geführt. Dies sind interaktive Einheiten, mit denen z. B. Marketing-Teams und Marktforschende kommunizieren und Erkenntnisse gewinnen können. Die Herausforderung besteht darin, ein Gleichgewicht zwischen der Einfachheit von Personas und der Tiefe der Erkenntnisse zu finden, die sie liefern. Es gibt immer mehr Methoden und Möglichkeiten für eine bessere Entscheidungsfindung, Zusammenarbeit und Innovation.
Ipsos hat mit der revolutionären Ipsos PersonaBot-Lösung, die auf der Ipsos-eigenen generativen KI-Plattform basiert und sich auf eine umfassende wissenschaftliche Validierung stützt, eine Vorreiterrolle in diesem Gebiet übernommen. Dieses neue Tool, das wir inzwischen bei einer beträchtlichen Anzahl internationaler und Schweizer Kundinnen und Kunden im Einsatz haben, ermöglicht den Mitarbeitenden einer Organisation die Interaktion mit Personas, die ihre Zielgruppen repräsentieren. Teams können dynamisch mit Zielgruppen kommunizieren, Ideen schnell testen und mit Einfühlungsvermögen auf sich verändernde Bedürfnisse reagieren – und all dies auf der Grundlage methodisch fundierter Forschung.
Über ein sicheres Portal können Benutzer:innen Fragen zu allen möglichen Themen stellen: Einstellungen und Verhaltensweisen, Anforderungen an die Kommunikation, Präferenzen für die Art der Nachrichten und Kanäle usw. Die Personas können individuell oder als Gruppe befragt werden, fast wie eine Fokusgruppe. Die Plattform kann auch direkt mit Frameworks zur Aktivierung verknüpft werden, z. B. mit Vorlagen für Briefings von Agenturen.
Wenn Personas auf einer soliden Grundlage qualitativer und quantitativer Forschung durch erfahrene Expertinnen und Experten aufgebaut sind, dienen Persona-Bots als unschätzbare Tools für die Ideenfindung, die Hypothesenbildung und die Berücksichtigung des Menschen in jeder Diskussion im Unternehmen. Sie sind jedoch kein Ersatz für fundierte Marktforschung und menschliches Urteilsvermögen, wenn es darum geht, Erkenntnisse zu validieren und strategische Entscheidungen zu treffen. Persona-Bots sind nur so gut wie das Fachwissen und die Daten, die in ihre Erstellung einfliessen.
Erstellung eines Persona-Bots
Die Erstellung eines effektiven Persona-Bots erfordert mehr als nur die Eingabe von Rohdaten in ein KI-System. Es erfordert eine sorgfältige Aufbereitung und Organisation der Informationen, einschliesslich:
Wer: Grundlegende demografische und psychografische Informationen über die Persona.
Warum: Das Verständnis der Motivationen, Bedürfnisse und Einstellungen der Persona.
Was: Einblicke in die Marken und Produkte, welche die Persona nutzen könnten.
Wo: Verstehen des Kontexts und der Anlässe für die Produktnutzung.
Der Lebensstil: Ein umfassenderes Bild des allgemeinen Lebensstils, der Interessen und der Mediengewohnheiten der Persona.
Neben den Fakten profitieren Persona-Bots auch davon, dass sie mit Beispielen von Sprachgebrauch und Persönlichkeitsmerkmalen angereichert werden, um die Denkweise der Persona besser zu verstehen. Auch Bilder können das Persona-Profil aufwerten, wobei jedoch darauf geachtet werden muss, dass die KI-Algorithmen nicht durch bestehende Vorurteile verzerrt werden.
Verzerrungen («Biases») und Einschränkungen
Personas helfen Designern und Marketingfachleuten zwar dabei, ihre Zielgruppen zu verstehen und Zielgruppenprofile zu erstellen, doch haben sie auch ihre Grenzen, die berücksichtigt werden müssen:
Realismus: Personas müssen auf einer gründlichen Beobachtung und Analyse beruhen. Mit KI ist es nur allzu leicht, Personas zu erstellen, die zwar realistisch erscheinen, aber nicht die tatsächlichen Kundengruppen repräsentieren. Die Glaubwürdigkeit einer Persona hängt stark von der Segmentierungsanalyse und der Expertise der Marktforscher:innen ab.
Repräsentativität: Personas sind Archetypen, keine monolithischen Konstrukte. Ihre Gültigkeit ist kontextspezifisch, d. h. sie besteht in Bezug auf einen Markt, ein Land, ein Objekt und einen Zweck.
Qualität der Priming-Daten (Input Daten): Die Qualität und Tiefe der erhobenen Daten sind entscheidend für KI-generierte Personas. Ungenaue oder verzerrte Daten können zu irreführenden Erkenntnissen führen.
Einschränkung der Perspektive: Persona-Bots können nur Fragen innerhalb des Bereichs der erhobenen bzw. analysierten Daten beantworten, nicht darüber hinaus.
Nicht-kausale Zusammenhänge: KI erkennt manchmal falsche Korrelationen und verwechselt diese mit kausalen Zusammenhängen. Menschliches Fachwissen ist für die Beratung unerlässlich.
Wichtige Erkenntnisse und zukünftige Entwicklungen
Bei verantwortungsvoller Anwendung haben Persona-Bots ein immenses Potenzial, KI zu vermenschlichen und die Stimme des Kunden/der Kundin (Voice of the Customer) auf eine nie dagewesene Weise in die Organisation einzubringen. KI-gestützte Persona-Bots stellen einen bedeutenden Fortschritt in der Marktforschung dar und bieten eine dynamische und interaktive Möglichkeit, Zielgruppen zu verstehen. Sie ersetzen nicht das menschliche Urteilsvermögen, sondern dienen als leistungsfähige Tools zur Inspiration und Ideenfindung. Im Zuge der weiteren Entwicklung und des Fortschritts werden Persona-Bots zu einem integralen Bestandteil, indem sie die Innovation beschleunigen und die Wirkung von Erkenntnissen in allen Branchen erhöhen. Es ist von entscheidender Bedeutung, Grundsätze festzulegen und eine verantwortungsvolle Anwendung dieser Tools zu gewährleisten, um ihr Potenzial voll auszuschöpfen und gleichzeitig mögliche Verzerrungen und Einschränkungen zu minimieren. Die Zukunft der Marktforschung wird zweifellos von diesen Fortschritten geprägt sein, und Persona-Bots stehen an der Spitze dieses Wandels.
Dieser Artikel basiert auf einem demnächst erscheinenden, neuen globalen Ipsos White Paper und wurde in einer Kombination aus Human Intelligence (Francesca & Guido) sowie Artificial Intelligence (Ipsos Facto) erstellt.
Market research institutes regularly collect open-ended responses, but getting in-depth responses and manually analyzing such extensive open-ended data presents major challenges for researchers. Let’s explore how the adoption of LLMs and vocal transcripts helps to increase insight quality.
Best practices for open-ended quality at the Era of AI
By regularly offering voice transcription in our market research surveys, we have gained the following key insights that enable us to best adopt this technology.
#1 Audio that accompanies the text
Letting respondents both read and listen to the question helps them stay more focused. This dual approach enhances their attentiveness, making it a key factor in maximizing the quality of insights from your survey. Modern text-to-speech technology is highly efficient and sounds natural, ensuring a smooth experience.
Respondent said: “It’s really nice to answer the questions orally and hear them locally. It’s fun and interesting.”
#2 Voice as an option for market research surveys
Giving respondents the option to respond with or without voice decreases the potential fatigue.
Respondent said: “A pity to do it with a microphone; sometimes writing is more clear.”
#3 Voice requires clarity of mind
Using voice enables users to express their thoughts more openly and clearly, fostering more authentic and effective communication.
Respondent said: “An excellent experience with the microphone. I’ve noticed, and can say easily, that writing down responses to questions is automatic, while answering with the microphone requires a bit more dexterity.”
#4 No redundancy
Time is valuable – don’t waste your respondents’ time. An advanced AI model is needed to avoid looping the same conversation topics.
Respondent said: “The questions go in circles. The direction of the questionnaire ended up being more double what was originally stated.”
An effective AI modelization use could create important value for Market Researchers
The market research institute YouGov Switzerland partnered with Pulse Partners to test our new tool. The goal was to enhance the ability to collect and automatically classify qualitative insights at scale. With a survey involving approximately 3,600 respondents across Switzerland (both French- and German-speaking regions), we aimed to gain a deeper understanding of regional product perceptions.
Here are the key technological features we leveraged from our test of Smartinterview with YouGov :
1 – AI-Driven probing:
The survey adapted in real time, asking targeted follow-up questions to encourage respondents to expand on their answers, resulting in richer and more detailed insights. The context is driven automatically be the Market Researcher.
2 – Voice reads question:
The questions of the survey are read in the respondent’s language.
3 – Multi-lingual voice transcript:
The survey is conducted in French and Swiss German, ensuring cultural and linguistic relevance for Swiss respondents.
4 – Sentiment and topic analysis:
Key topics from responses are automatically classified with AI.
Effective AI implementation can drive significant value creation for Market Researchers
Here is a sample of what we get from the data collection with and without Smartinterview:
By adoptingSmartinterview, we have improved the depth and accuracy of the insights on regional product feedback and could propose this technology to end-client with more comprehensive insights.
Qualitative long-tail feedbacks
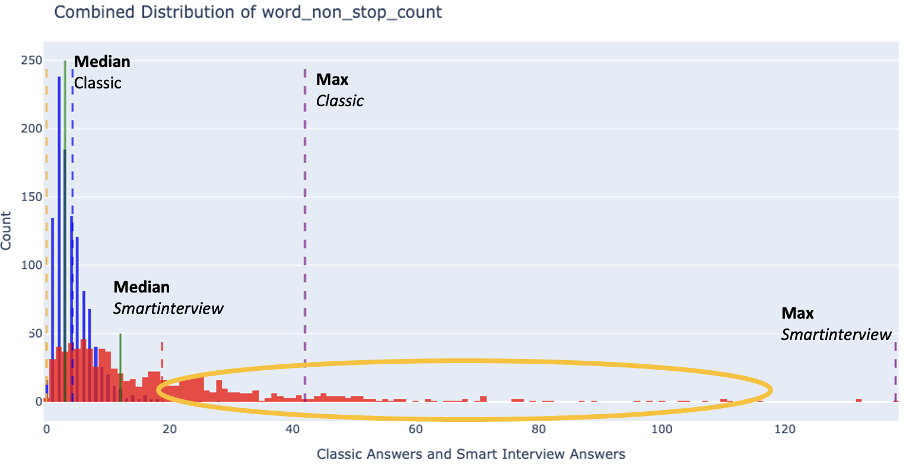
If we take the median, Smartinterview captures approximately 4 times more words per response. A likely explanation is that when respondents use voice, they naturally articulate their thoughts more freely and in greater detail.
Access to long-tail feedbacks: We have been able to capture detailed, highly specific feedback from a subset of respondents who would otherwise provide limited input (highlighted in yellow in the above graphic).
With Smartinterview, we can seamlessly integrate qualitative interviews within a quantitative survey, capturing in-depth insights in a single run. This approach eliminates the need for separate qualitative and quantitative studies, significantly reducing costs while maintaining the richness of open-ended responses typically found in real-life qualitative interviews.
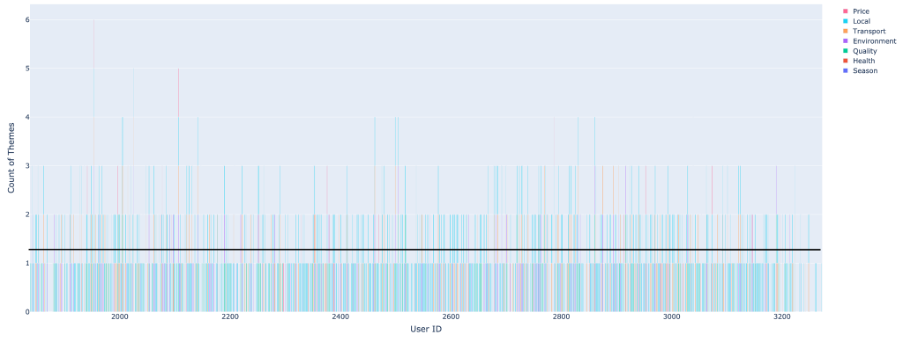
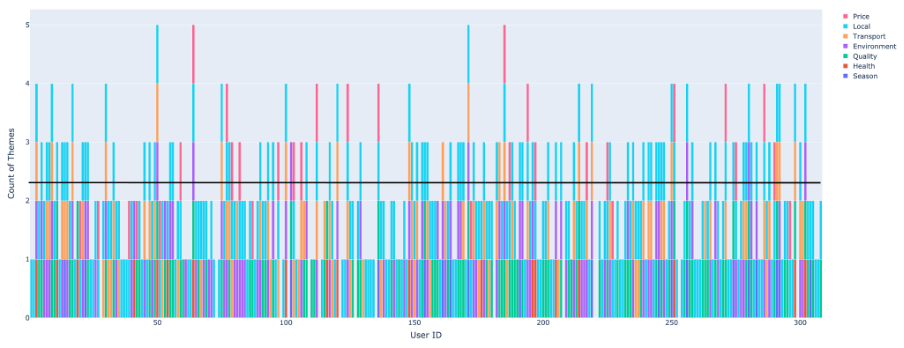
The comparison graphics below illustrate the number of topics generated from a traditional open-ended question versus a Smartinterview open-ended question for each respondent, highlighting the depth and richness of insights captured.
Traditional methodologySmartinterview methodology
Here is what has been found:
2.2 times more topics captured per response – Compared to traditional open-ended questions, respondents provided significantly richer and more detailed answers, enabling a more comprehensive and nuanced analysis.
A seamless integration for Market Researchers and Companies
The collaboration between YouGov and Pulse Partners showcases the transformative power of AI and voice in market research surveys, enhancing insight quality without increasing costs. Market research companies can increase the depth and accuracy of their insights on regional product feedback and could propose this technology to its end-client.
“Smartinterview is an exciting tool with interesting possibilities. We were able to integrate it seamlessly into our survey, making it available for clients who may wish to use it with us in the future. In particular, we see potential for gaining more cost-effective insights: with Smartinterview, it may be possible to derive the same insights from open-ended questions with fewer survey respondents.” — Dr. Manuel Cariappa-Schwaninger, Research Consultant, YouGov
Angenommen, wir betrachten Käufer:innen im Lebensmitteleinzelhandel (LEH) beim Erledigen ihres täglichen Einkaufs. Sie wählen Produkte von ihrer Einkaufsliste aus, bleiben spontan bei reduzierten Angeboten stehen und legen das eine oder andere Produkt in ihren Einkaufswagen. Warum üben Reduzierungen eine gewisse «magische» Anziehungskraft auf uns aus? Welche Faktoren führen zu diesem (impulsiven) Verhalten, reduzierte Produkte zu erwerben? Und wie kann der LEH die Käufer:innen dazu bewegen, Produkte im Angebot zu kaufen, an die sie zuvor nicht gedacht hatten? Viele unterschiedliche Faktoren beeinflussen unser Kaufverhalten. Ein kostengünstiger und daher relevanter Faktor ist die optische Preisgestaltung.
Bisherige Untersuchungen erforschten hauptsächlich die Auswirkungen von prozentualen und absoluten Reduzierungen in hypothetischen Kaufszenarien, beispielsweise im Rahmen von (Online-)Experimenten. Dieser methodische Ansatz erfolgte jedoch isoliert von anderen Einflussfaktoren. Diese Studie in Zusammenarbeit mit einem führenden Lebensmitteleinzelhändler erforscht nun genau diese Lücke. Ziel ist es, die bisher nur in der Theorie nachgewiesenen Ergebnisse in einem realen Supermarkt-Setting zu überprüfen. Dafür wurde ein Zwei-Methoden-Ansatz verfolgt. Zum einen gab ein Online-Experiment Einsichten zu Bewertungen und Akzeptanz des Preisschildes aus Konsument:innensicht, zum anderen wurden im Rahmen eines Filialtests reale Abverkäufe gemessen. Der Fokus lag auf der Frage, ob Preisschilder mit prozentualen Reduzierungen auch unter nicht experimentellen Bedingungen zu höheren Abverkäufen führen als Preisschilder mit absoluten Reduzierungen. Zudem erforschte die Studie Moderationsfaktoren im Zusammenhang mit prozentualen Darstellungen und den Absatzzahlen im Filialtest. Dabei fiel die Wahl besonders auf bisher wenig oder gar nicht berücksichtigte Faktoren, wodurch eine Forschungslücke bezüglich Einflussfaktoren auf Produkt und Preis geschlossen wurde.
Dafür wurden mithilfe einer Clusteranalyse und anhand verschiedener Attribute möglichst ähnliche Referenz- und Testfilialen identifiziert. Insgesamt wurden 35 Filialen in den Test einbezogen. Letztendlich ergab sich ein Datensatz aus 5600 Produktdaten auf Basis von 438 verschiedenen Produkten und 873 Reduzierungen. Getestet wurde im Zeitraum vom 01.05.2022 bis zum 01.07.2022 in Deutschland.
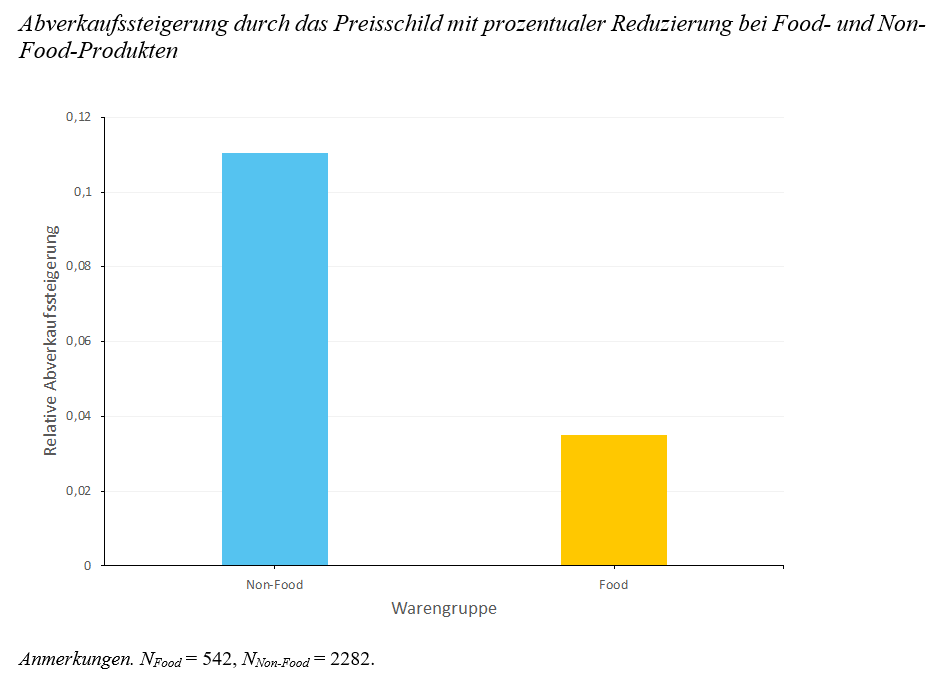
Wirkung der Reduzierungsdarstellung auf den Abverkauf
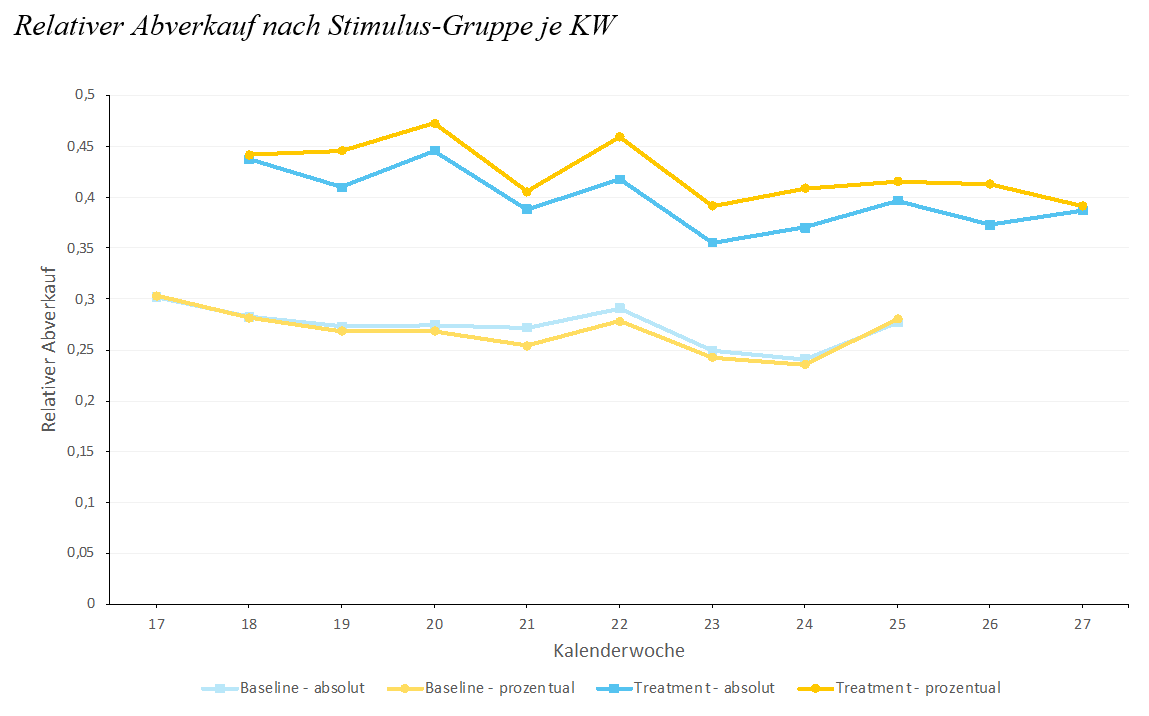
Wie beeinflusst also die Art und Weise der Darstellung von Preisnachlässen die Konsument:innen in ihren Kaufentscheidungen? Die bisherige Forschung zeigt, dass diese Frage nicht einfach zu beantworten ist, sondern dass viele Faktoren Einfluss auf das Kaufverhalten von Konsument:innen haben. Generell beeinflussen prozentuale Darstellungen von Reduzierungen die Konsument:innen und führen zu höheren Abverkäufen von Produkten. Insgesamt ergab sich mit Einbezug der Baseline-Gruppe ein Gesamtanstieg des relativen Abverkaufs um 9,71 %. Das unterstützt die Annahmen des Preis-Promotion-Framings, nach dem wertmässig identische Reduzierungen nur aufgrund anderer Darstellung zu unterschiedlichen Kaufverhalten der Konsument:innen führen. Dies lässt auf unterbewusste, heuristische Wirkungen der prozentualen Reduzierungen schliessen, welche die subjektive Preiswahrnehmung von Konsument:innen beeinflussen. Damit ist die richtig eingesetzte optische Preisgestaltung ein geeignetes Mittel zur Steigerung von Abverkäufen.
Weil Beeinflussungsprozesse hingegen individuell ablaufen und im LEH nur einer von vielen Faktoren sind, mussten weitere relevante Moderationsfaktoren berücksichtigt werden. Der Fokus lag auf Faktoren, die zuvor nur wenig oder gar nicht betrachtet wurden. Dabei beeinflussen die Reduzierungstiefe und die Anzahl der Reduzierungen den Effekt der Stimulus-Gruppe auf den relativen Abverkauf positiv. Das bedeutet: Je höher die Reduzierung ist und je häufiger ein Produkt reduziert wird, desto besser ist der Abverkauf mit Preisschildern, die eine prozentuale Reduzierungsdarstellung haben. Ausserdem ist der Effekt der Abverkaufssteigerung besonders hoch bei Non-Food-Produkten.
Dahingegen moderieren sowohl der Produktpreis (unter 100 €), die Lebensdauer und die Woche der Reduzierung den Effekt der Stimulus-Gruppe auf den relativen Abverkauf nicht. Die besseren Abverkäufe bei dem Preisschild mit einer prozentualen Reduzierung sind also unabhängig von diesen Faktoren.
Implikationen für die Praxis
Die wichtigste Erkenntnis für die Praxis ist, dass Preisschilder mit einer prozentualen Reduzierung bei Produkten unter 100 € zu höheren Abverkäufen führen. Vor allem im LEH ist dieses Ergebnis von zentraler Bedeutung, weil dieser nur selten Produkte über 100 € verkauft. Weitergehend können auf zwei Ebenen Implikationen für die Praxis getroffen werden. Zum einen auf Konsument:innenseite, zum anderen auf Seite der Einflussfaktoren im LEH. Alle Implikationen beziehen sich auf den Ausgangspunkt, dass die Abverkäufe bei der prozentualen Reduzierungsdarstellung höher sind und von verschiedenen Faktoren beeinflusst werden. Auf Konsument:innenseite führen höhere Reduzierungen zu einem höher wahrgenommenen Wert des Angebotes. Dies geht einher mit dem Trend, dass die relativen Abverkäufe steigen, je höher die Reduzierung ist. Demgegenüber hat die Reduzierungstiefe keinen Einfluss auf die wahrgenommene Qualität des Produktes der Konsument:innen. Selbst hohe Reduzierungen führen also nicht zu schlechteren Qualitätsbewertungen und damit auch nicht zu potenziell schlechteren Abverkäufen.
Auf Seite des LEH ist festzuhalten, dass höhere Reduzierungen zu besseren Abverkäufen führen. Ausserdem konnte festgestellt werden, dass selbst bei geringen Reduzierungen mit einer prozentualen Reduzierung eine Steigerung der Abverkäufe erzielt wurde. Es existieren also nicht – wie zuvor angenommen – gewisse Schwellenwerte, bei denen eine Reduzierung wirkt. Lebensmitteleinzelhändler sollten daher geringe Reduzierungstiefen nicht per se ausschliessen. Vielmehr sollte die optimale Reduzierungstiefe abgewogen werden, um Gewinne zu maximieren und Verluste zu vermeiden. Gleiches gilt für die Anzahl an Reduzierungen, weil mit jeder Reduzierung auch die Reduzierungstiefe ansteigt. Ausserdem konnte vor allem der Abverkauf von Non-Food-Produkten durch die prozentuale Darstellung gesteigert werden. Der Grossteil der Aktionsartikel setzt sich aus diesen zusammen, weswegen diese Erkenntnis von besonderer Relevanz ist.
Leonie Bodden
Gewinnerin Nachwuchsforscherinpreis 2024 des bvm/vmö/Swiss Insights
Die Autorin Leonie Bodden absolvierte ihren Master Kommunikationsmanagement und -analyse an der Uni Hohenheim. Aktuell ist sie als Produktmanagerin für die digitalen Produkte der Motor Presse Stuttgart GmbH & Co. KG tätig. Für ihre Masterarbeit «It’s all about the Price Tag: Ein empirischer Vergleich von prozentualen vs. Absoluten Preisveränderungen im LEH-Kontext» wurde sie mit dem Nachwuchsforscherinpreis 2024 der DACH-Verbände (bvm/vmö/Swiss Insights) ausgezeichnet.
Das Ende physischer Geschäfte wurde schon häufig eingeläutet, doch die Realität sieht anders aus. Ein Blick auf die Umsatzzahlen zeigt, dass der stationäre Einzelhandel noch immer etwa 75 % des weltweiten Einzelhandelsumsatzes ausmacht (Coppola 2023). Selbst grosse Online-Riesen wie Amazon und Alibaba haben die anhaltende Relevanz stationärer Geschäfte erkannt und investieren gezielt in deren Ausbau.
Dennoch haben sich die Erwartungen an den stationären Handel gewandelt. In einer Zeit, in der Kund:innen mit wenigen Klicks von überall aus einkaufen können, stellen sie auch höhere Anforderungen an physische Geschäfte. Immer häufiger wünschen sie sich ein einzigartiges Einkaufserlebnis. Um den neuen Ansprüchen gerecht zu werden, stehen viele Einzelhändler:innen vor der Herausforderung, das Werteversprechen ihrer physischen Geschäfte neu zu definieren
Fünf Vorteile physischer Geschäfte
Auch in der heutigen Zeit hat der stationäre Einzelhandel besondere Möglichkeiten, um Kund:innen in die physischen Geschäfte zu locken. In ihrer Multi-Methoden Studie «The future of physical stores: Creating reasons for customers to visit» identifizieren Els Breugelmans (KU Leuven), Lina Altenburg (KU Leuven), Felix Lehmkuhle (Universität Münster), Manfred Krafft (Universität Münster), Lien Lamey (KU Leuven) und Anne L. Roggeveen (Babson College) fünf zentrale Vorteile, die physische Geschäfte ihren Kund:innen bieten können:
Entdeckung: Viele Kund:innen möchten sich vor dem Kauf eines Produkts gut informieren – besonders bei teuren Artikeln oder unsicheren Käufen, z. B. frischen Lebensmitteln. Im stationären Geschäft haben sie die Möglichkeit, direkt mit den Produkten und den Mitarbeiter:innen in Kontakt zu treten. Während sie beim Onlinekauf oft nur Bilder und Produktbeschreibungen sehen, können sie im physischen Geschäft all ihre Sinne nutzen. Einzelhändler:innen können interaktive Bereiche einrichten oder Veranstaltungen anbieten, bei denen die Kund:innen Produkte erleben und testen können. Diese multisensorische Erfahrung stärkt nicht nur das Vertrauen in die Kaufentscheidung, sondern fördert auch eine emotionale Bindung zum Produkt und zur Marke.
Bequemlichkeit: Bequemlichkeit spielt eine entscheidende Rolle beim Einkaufserlebnis und umfasst die Erleichterung, Beschleunigung und Reduzierung des Aufwands. Physische Geschäfte können hier durch flexible Öffnungszeiten, zentrale Standorte, ausreichend Parkplätze und die Nähe zu anderen Geschäften punkten. Ein wesentlicher Vorteil gegenüber dem Onlinehandel ist die Möglichkeit, Produkte sofort mitzunehmen, ohne auf den Versand warten zu müssen. Darüber hinaus können Zusatzangebote wie Click-and-Collect, bei denen Kunden online bestellen und die Ware im Geschäft abholen, den Einkaufsvorgang erleichtern.
Personalisierung: Personalisierung zielt darauf ab, die Customer Journey individuell auf die Bedürfnisse der Kund:innen abzustimmen. In physischen Geschäften können Mitarbeiter:innen direkt mit den Kund:innen interagieren, um ihre Wünsche besser zu verstehen und das Angebot entsprechend anzupassen. Innovative Technologien wie intelligente Umkleidekabinen sowie AR- und VR-Anwendungen eröffnen zudem neue Möglichkeiten. Ein spannender Ansatz ist die kollaborative Personalisierung, bei der Mitarbeiter:innen und Kund:innen gemeinsam Produkte gestalten – wie beispielsweise bei Build-A-Bear. Zusätzlich bieten persönliche Einkaufsberater:innen wertvolle Unterstützung, beantworten Fragen und optimieren so das Einkaufserlebnis.
Gemeinschaft: Gerade in der Pandemie wurde deutlich, wie wichtig persönliche Interaktionen sind. Einzelhändler:innen, die ihre Geschäfte zu Orten der Begegnung gestalten, können eine starke Kundenbindung aufbauen. Veranstaltungen, Sportkurse, Co-Working-Bereiche und gastronomische Angebote fördern nicht nur den Austausch, sondern verwandeln den Besuch in ein echtes Erlebnis und laden zum Verweilen ein. Solche Initiativen helfen dabei, eine lebendige Community aufzubauen. Regelmässige Events im Geschäft binden die Kund:innen aktiv ein und vermitteln ein Gefühl der Zugehörigkeit. Ausserdem helfen sie, die Bedürfnisse der Kund:innen besser zu verstehen und sich kontinuierlich weiterzuentwickeln.
Shoppertainment: Einzelhändler:innen können ihre Geschäfte kreativ gestalten, um den Kund:innen ein unterhaltsames Erlebnis zu bieten. Ein Sportladen kann beispielsweise einen kleinen Sport-Court einrichten, auf dem die Besucher:innen ihre Fähigkeiten ausprobieren. Veranstaltungen wie Ausstellungen lokaler Künstler:innen bieten weitere Anreize, im Geschäft vorbeizuschauen. Ein Ansatz, der insbesondere in der Modebranche Anklang findet, besteht in der Einrichtung eines «Green Screen Raums», in dem Kund:innen Fotos machen und ihre Erlebnisse auf Social Media teilen können. Wichtig ist, dass all diese Massnahmen letztlich darauf abzielen, den Verkauf von Produkten zu fördern und den Umsatz zu steigern.
Herausforderungen einer Transformation
Um sich den ändernden Kundenbedürfnissen anzupassen, gestalten viele Einzelhändler:innen ihre Geschäfte umfassend um. Dabei liegt die Vermutung nahe, dass eine Neugestaltung automatisch zu höheren Umsätzen führt. Doch aus der Forschung wissen wir, dass viele Menschen dazu neigen, am Vertrauten festzuhalten (Endowment-Effekt; Thaler 1980).
Bei der Transformation eines Geschäfts rücken meist bestimmte Produktkategorien in den Fokus, während andere in Sortimentsumfang und -komposition sowie ihrer Platzierung auf der Ladenfläche unverändert bleiben. Legt ein Geschäft beispielsweise einen Fokus auf Frische, bleiben verpackte Lebensmittel oft unverändert. Um den wirtschaftlichen Erfolg einer solchen Transformation zu bewerten, ist es allerdings wichtig, auch mögliche Umsatzeffekte auf die unveränderten Kategorien in den Blick zu nehmen.
Felix Lehmkuhle (Universität Münster), Els Breugelmans (KU Leuven), Marleen Hermans (Radboud Universität), Manfred Krafft (Universität Münster), Mirja Kroschke (Universität Münster) und Murali Mantrala (Kansas Universität) zeigen in ihrer Forschungsarbeit «What’s Happening to My Unchanged Categories – Differential Effects of a Store Transformation» (derzeit unter Begutachtung beim Journal of Retailing), dass auch unveränderte Kategorien von Umsatzeffekten betroffen sein können und wie diese mit den Eigenschaften der Kategorien zusammenhängen. Die Autor:innen analysieren in Zusammenarbeit mit einem grossen deutschen Hypermarkt, der sein Geschäftskonzept von preis- auf erlebnisorientiert umgestellt hat, die Umsatzeffekte bei Bestandskund:innen über einen Zeitraum von drei Jahren. Sie stellen fest, dass der Umsatz in einer durchschnittlichen unveränderten Kategorie (mit typischen Merkmalen) nach der Transformation sinkt. Obwohl die Autor:innen nicht davon ausgehen, dass dieser Effekt allgemeingültig ist, verdeutlicht das Ergebnis ihrer Arbeit, wie wichtig es ist, potenzielle Auswirkungen auf unveränderte Kategorien zu berücksichtigen.
Um mögliche Effekte besser abzuschätzen, können Einzelhandelsmanager:innen die Eigenschaften der unveränderten Kategorien heranziehen. Die Autor:innen beobachten einen besonders starken Umsatzrückgang bei Kategorien, die Kund:innen mit höherer Impulsivität oder finanziellem Risiko verbinden. Auf der anderen Seite können unveränderte Kategorien, die zum Gesamtfokus des neu gestalteten Geschäfts passen, auch weniger stark betroffen sein oder sogar profitieren. In der Fallstudie legt das umgestaltete Geschäft grossen Wert auf Frische. Entsprechend stellen die Autor:innen fest, dass unveränderte Kategorien, die typischerweise mit Frische assoziiert werden, einen geringeren Umsatzrückgang verzeichnen.
Die Transformation eines Geschäfts beeinflusst nicht nur das umgestaltete Geschäft, sondern auch die Attraktivität der umliegenden Geschäfte. Da umfangreiche Veränderungen viel Geld kosten und Zeit in Anspruch nehmen, gehen Einzelhändler:innen in der Regel schrittweise vor. Daher findet man transformierte Geschäfte nicht selten in der Nähe (noch) unveränderter Geschäfte derselben Kette. In einer weiteren Forschungsarbeit («What’s Happening to My Nearby Stores? The Own- and Cross-effect of a Radical Store Transformation on Existing Customers») untersuchen die Autor:innen der vorherigen Studie eben solche Konstellationen und fokussieren sich insbesondere auf das Wechselverhalten der Kund:innen zwischen den Geschäften. Sie zeigen, dass der Umsatz der Bestandskund:innen im transformierten Geschäft sinken kann, während die benachbarten, unveränderten Geschäfte Umsatzgewinne verzeichnen. Obwohl die Bestandskund:innen das transformierte Geschäft häufiger besuchen, geben sie dort weniger aus. Ihre Ausgaben in den unveränderten Geschäften steigen hingegen.
Allerdings reagieren nicht alle Kund:innen gleich. Kund:innen, die durch ihr Einkaufsverhalten vor der Transformation gezeigt haben, dass sie Merkmale des neuen Ladenformats schätzen (bspw. frische Produkte), begegnen der Neuerung positiver und sollten daher gezielt auf die neuen Angebote aufmerksam gemacht werden. Bestandskund:innen, die in der Vergangenheit eine besonders hohe Verbundenheit zum alten Geschäft gezeigt haben, reagieren auf die Veränderung kritischer. Einzelhandelsmanager:innen sollten diesen Kund:innen helfen, sich in der neuen Umgebung zurechtzufinden oder sie an die unveränderten Geschäfte in der nahen Umgebung erinnern.
Nach wie vor bieten physische Geschäfte Vorteile, die stationäre Einzelhändler:innen nutzen können, um wettbewerbsfähig zu bleiben. Allerdings führt nicht jede Neuerung automatisch zum Erfolg. Bei einer umfangreichen Transformation sollten auch mögliche Umsatzeffekte auf die unveränderten Kategorien in Betracht gezogen werden. Ausserdem ist es wichtig, mögliche negative Reaktionen der Bestandskund:innen zu berücksichtigen. Interessanterweise können gerade die naheliegenden, (noch) nicht umgewandelten Geschäfte helfen, kritischen Bestandskund:innen eine Alternative zu bieten und sie so von der Abwanderung zur Konkurrenz abzuhalten.
Dr. Felix Lehmkuhle
Gewinner Nachwuchsforscherpreis 2024 des bvm/vmö/Swiss Insights
Der Autor Dr. Felix Lehmkuhle studierte BWL in Münster und absolvierte einen Doppel-Master in Marketing & Finance sowie Marketing Intelligence. Danach promovierte er im Quantitativen Marketing. Er ist Experte für datengetriebene Entscheidungen und war als Dozent für Marketing Analytics tätig. Für seine Dissertation «Is New Always Better? The Future of Physical Stores» wurde er mit dem Nachwuchsforscherpreis 2024 der DACH-Verbände (bvm/vmö/Swiss Insights) ausgezeichnet.
Durch die Verarbeitung grosser Mengen unstrukturierter qualitativer Daten kann generative KI differenzierte Analysen und Berichte erstellen und so Zeit und Kosten erheblich reduzieren. Die Technologie eignet sich hervorragend für Aufgaben wie die Analyse und Zusammenfassung von qualitativen Interviews und Gruppendiskussionen. Generative KI hat jedoch Schwierigkeiten, strategische Schlussfolgerungen auf den Punkt zu bringen; eine Aufgabe, die am besten weiterhin erfahrenen Forschenden überlassen wird. Mit dem «ChatYourData»-Ansatz lassen sich qualitative Daten unmittelbar in Produktinnovationen oder Kommunikationskonzepte umsetzen. Die generative KI verspricht, qualitative Erkenntnisse wettbewerbsfähiger und zugänglicher zu machen, und könnte so zum Game-Changer für die Markt- und Sozialforschung werden.
Die Rolle der generativen KI in der der qualitativen Markt- und Sozialforschung
Mit der Veröffentlichung von ChatGPT im Herbst 2022 sind die Möglichkeiten der generativen KI einer breiten Öffentlichkeit bewusst geworden. Insbesondere die Leistungen der hochentwickelten Sprachmodelle (Large Language Models) beim Schreiben und Redigieren von Texten sind auf den ersten Blick erstaunlich. In der qualitativen Markt- und Sozialforschung steht die Sprache im Zentrum – in Form von Tiefeninterviews, Gruppendiskussionen oder anderen digitalen Formen des Dialogs. Die aktuelle Generation der generativen KI ist deshalb prädestiniert, qualitative Forschung voranzubringen. Entsprechende Methoden nutzen auch projektive Verfahren wie Visualisierungen, um ein vertieftes Verständnis von Emotionen und Einstellungen zu gewinnen. Die Übersetzung von Sprache in Bilder und umgekehrt ist die Stärke von visuellen generativen Modellen wie Dalle, Midjourney und anderen.
Die qualitative Markt- und Sozialforschung ist eine unverzichtbare Ergänzung zur besser bekannten und viel häufiger eingesetzten strukturierten («quantitativen») Umfrageforschung. Die qualitative Forschung ist explorativ und ermöglicht es den Teilnehmenden, ihre Gedanken und Gefühle in ihren eigenen Worten auszudrücken. Dies kann zu Erkenntnissen führen, die in einer strukturierten Umfrage vielleicht nicht erwartet oder erfasst worden wären. Qualitative Erkenntnisse liefern Erklärungen zum «Wie?» und «Weshalb?» hinter den quantitativen Zahlen.
Bisher hatte die qualitative Markt- und Sozialforschung den Ruf, zeitaufwändig und teuer zu sein. Durch die Nutzung von generativer KI kann sie nun effizienter, schneller und besser werden. Dies wird zu einem Revival der qualitativen Methoden führen.
Dieser Artikel untersucht die potenziellen Verbesserungen und Herausforderungen von generativer KI in der qualitativen Verbraucherforschung und konzentriert sich dabei auf die konkreten Anwendungen.
Was ist generative KI?
Generative KI bezieht sich auf eine Teilmenge von Technologien der künstlichen Intelligenz, die neue Inhalte generieren können, einschliesslich Text, Bild und Audio. Generative KI gibt es schon lange. Bereits im letzten Jahrhundert wurden Versuche gestartet mit Computern, die eine menschenähnliche Fähigkeit zur Konversation beherrschten. Der aktuelle Durchbruch ist auf Fortschritte in der Hardware, in den theoretischen Konzepten und in den eingesetzten Algorithmen zurückzuführen.
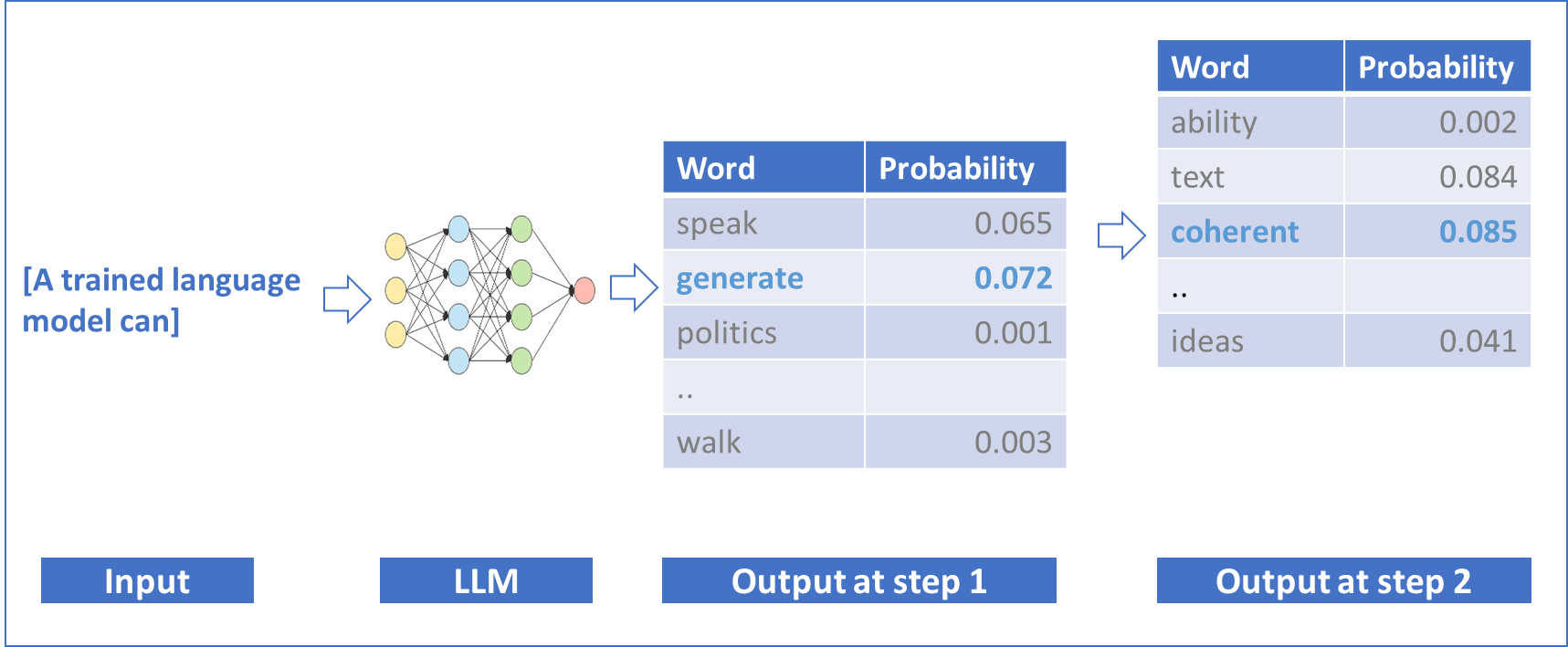
Neue theoretische Konzepte Die modernen generativen KI-Modelle fokussieren nicht auf abstrakte grammatikalische und semantische Regeln, sondern darauf, wie Sprache verwendet wird. Zentral ist die Annahme, dass die Bedeutung eines Wortes im Kontext seiner Verwendung liegt. Umgekehrt folgt daraus, dass die Wahrscheinlichkeit eines Wortes aufgrund des Kontextes vorausgesagt werden kann. Dies machen sich die Entwickler der Large Language Models wie OpenAI, Mistral oder Gemini zunutze: Sie trainieren die Sprachmodelle darauf, immer das nächstfolgende Wort eines Satzes oder eines Textes vorherzusagen. Der Vorteil dieses Ansatzes liegt darin, dass für das Training grosse Mengen bestehender Texte verwendet werden können, die nicht manuell vorbereitet werden müssen (kein kostenintensives Labeling bzw. keine Annotation). Der vergleichsweise einfache Ansatz, aus dem Kontext den jeweils wahrscheinlichsten Output vorherzusagen, funktioniert überraschend gut – auch für inhaltlich anspruchsvolle und komplexe Aufgabenstellungen.
Neue Algorithmen Für das Training werden bewährte Algorithmen in Form neuronaler Netzwerke mit einer hohen Anzahl an Schichten eingesetzt – deshalb auch «Deep Learning» genannt. Der Durchbruch für die generative KI basiert auf einem spezifischen, relativ neuen Typ neuronaler Netzwerke: Transformer Modelle, die in der Lage sind, vergleichsweise lange Textsequenzen parallel zu verarbeiten und gleichzeitig die besonders relevanten Textstellen höher zu gewichten.
Die sogenannten Foundation Models, die einen Satz oder einen anderen Kontext ergänzen können, bilden allerdings nur den ersten Schritt zur Entwicklung eines KI-Sprachmodells. Ein funktionsfähiges Modell, das Fragen beantworten und Anweisungen ausführen kann, braucht weitere Schritte:
Foundation Model: Wir können Text generieren, indem wir ein Wort nach dem anderen vorhersagen.
In einem zweiten Schritt, dem Instruction Finetuning, wird das Modell darauf trainiert, spezifische Anweisungen zu befolgen, also zum Beispiel eine Zusammenfassung zu erstellen, einen Blog-Artikel zu schreiben oder eine Wissensfrage zu beantworten.
Der dritte Schritt, Reinforcement Learning from Human Input, optimiert die Qualität des Outputs so, dass die Erwartungen der Zielgruppen möglichst gut erfüllt werden. Dazu bewerten Hunderte von Testpersonen die Resultate manuell, was dann wiederum ins Training des Modells einfliesst.
Neue Hardware Die meisten technologischen Revolutionen der letzten Jahrzehnte basieren wesentlich auf sprunghaften Entwicklungen der Hardware. Bei der generativen KI sind dies neue Prozessoren, die ideal auf die Deep Learning Algorithmen abgestimmt sind, obwohl sie ursprünglich für Bildverarbeitung entwickelt wurden.
Implikationen für die Anwendung in der qualitativen Markt- und Sozialforschung
Das zugrundeliegende «Foundation Modell» einer modernen KI-Lösung basiert auf der beobachteten Verwendung von Sprache, die einerseits sprachliche Fähigkeiten wie Grammatik und Wortschatz, anderseits aber auch das Wissen über die Welt spiegelt. Die sprachlichen Fähigkeiten und das Fachwissen können in diesen Modellen also nicht klar getrennt werden. Das ist ein wichtiger Punkt, wenn wir generative KI, konkret die bekannten Large Language Models, für die qualitative Marktforschung einsetzen wollen.
Nehmen wir an, wir analysieren zum Beispiel Transkripte von Tiefeninterviews zum Thema «Schokolade» mithilfe von generativer KI. Das implizite «Weltwissen» des KI-Modells aufgrund der Trainingsdaten ist dabei immer mit im Spiel. Viele der Trainings-Texte wurden im Internet gesammelt oder stammen und aus digitalisierten Bibliotheken. Im Fall von Schokolade sind zum Beispiel nicht nur der Genuss, sondern auch Aspekte der Gesundheit, der Nachhaltigkeit und des Masshaltens relativ stark im Vorwissen der Modelle verankert.
Das ist an sich kein Nachteil der generativen KI. Tatsächlich ist Sprachverständnis ohne ein Verständnis der Wirklichkeit nicht möglich. Eine qualitative Marktforscherin wird Texte immer auch vor dem Hintergrund ihres Vorwissens analysieren. Entscheidend ist, dies bewusst zu reflektieren. Diese Reflexion fehlt den Sprachmodellen. Um eine angemessene, möglichst unverzerrte Analyse von qualitativen Konsumentenaussagen zu gewährleisten, braucht es also sorgfältig ausgearbeitete Kontrollmechanismen. Unter diesen Voraussetzungen kann KI sogar zu einer besseren Qualität qualitativer Insights beitragen: Forschende mit weniger Erfahrung haben manchmal einen sehr persönlichen Zugang zu den untersuchten Themen und bringen so unbewusst einen starken Bias ein. Bei Large Language Modellen fällt diese persönlich-subjektive Komponente der Analyse weg.
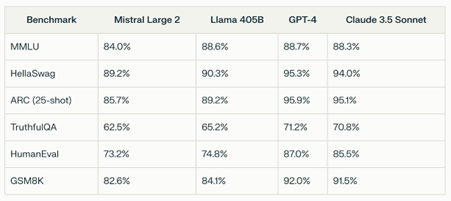
Die Qualität der Zusammenfassung von Transkripten beispielsweise hängt stark davon ab, wie gut das jeweilige Modell genau für diese Aufgabe trainiert wurde (Instruction Finetuning – siehe oben). Bei GPT, Gemini, Mistral, Claude und Llama funktionieren Zusammenfassungen sehr gut. Diese Disziplin beherrschen aber auch viele kleinere, günstigere Modelle.
Etwas anspruchsvoller wird es, wenn bestimmte relevante Themen aus einer Reihe von langen Transkripten extrahiert werden sollen, zum Beispiel die Motive oder die Barrieren des Schokoladekonsums aus mehreren Tiefeninterviews. Die führenden Modelle (GPT-4, Mistral Large oder Anthropic Claude Opus) machen dies ziemlich gut, ohne fremde Informationen aus ihrem impliziten «Wissen» in die Ergebnisse zu schmuggeln.
Auf welche Tasks ein Large Language Modell spezifisch trainiert wurde, ist allerdings oft nicht transparent. Hier hilft nur «Trial and Error», um die besten Lösungen zu identifizieren.
Qualitätskriterien Formale Qualitätskriterien, die für die Überprüfung und Evaluation von Large Language Models entwickelt wurden, sind nur beschränkt hilfreich.
Für die Bewertung der Qualität einer Text-Zusammenfassung gibt es die ROUGE-Metrik (Recall-Oriented Understudy for Gisting Evaluation). Der Score vergleicht eine durch Experten erstellte Referenz-Zusammenfassung mit dem Output eines KI-Modells. Für qualitative Ad-hoc-Studien liegt eine solche Referenz-Zusammenfassung in der Regel nicht vor. Dazu kommt, dass der ROUGE-Score primär die Wörter in den Zusammenfassungen vergleicht und auszählt, was etwas zu kurz greift.
In der Literatur werden oft standardisierte Performance-Messungen für konkurrierende Large Language Models publiziert. Diese Indices basieren auf Wissensfragen, z. B. Prüfungen für amerikanische College-Studierende, «Reasoning» oder dem Schreiben von korrekten Programmier-Codes. Diese Kriterien sagen wenig über die Leistungsfähigkeit im Rahmen von qualitativer Markt- oder Sozialforschung aus.
Beim Einsatz von generativer KI in der qualitativen Forschung muss die Qualität des Outputs vorderhand von der Studienleitung sorgfältig geprüft werden. Wünschenswert wäre die Entwicklung von standardisierten automatisierten Qualitäts-Scores zur Unterstützung. Ein Beispiel dafür wäre ein Vergleich der Topics, die in den Input-Daten aufscheinen, mit jenen in Zusammenfassungen und Interpretationen.
Use-Cases für Marketing und Produktentwicklung
Die möglichen Anwendungsfälle der generativen KI in der qualitativen Markt- und Sozialforschung sind sehr breit. Vieles steckt noch in den Kinderschuhen. Es braucht Zeit und finanzielle Ressourcen, um spezifische Tools zu entwickeln und insbesondere die Qualitätskontrollen zu institutionalisieren. Als Illustration dienen drei konkrete Use-Cases, die der Autor erfolgreich umgesetzt hat. Beim ersten Anwendungsfall geht es um die naheliegende Umsetzung von Effizienz und Zeitgewinn. Der zwei weiteren Use-Cases schauen eher in die Zukunft und sind noch experimentell.
Use Case 1: Generative AI als Forschungsassistentin für mehr Effizienz und Qualität Im Kontext der Markt- und Sozialforschung ist die generative KI besonders wertvoll aufgrund ihrer Fähigkeit, grosse unstrukturierte Datenmengen zu verarbeiten und nuancierte Analysen und Berichte zu erstellen.
Ein erster Anwendungsfall aus der Praxis illustriert das Vorgehen. Die strategische Fragestellung bestand darin, Erwartungen und Wünsche der Privatkundinnen und -kunden bei der Wahl einer Versicherung zu verstehen.
Als Datengrundlage standen 20 frei geführte Interviews von je ca. 40 Minuten Dauer in Schweizerdeutsch und Französisch zur Verfügung. Die Interviews wurden automatisch transkribiert und durch freie Mitarbeitende manuell nachbearbeitet.
Ziel des Projektes war, die Qualität einer automatisierten Analyse mittels generativer KI einer vorläufigen Prüfung zu unterziehen. Die ursprüngliche Analyse wurde durch erfahrene qualitative Marktforscherinnen mit «manuell» realisiert. Erst zu einem späteren Zeitpunkt wurde die Analyse mithilfe von KI (im Wesentlichen mit dem GPT4-Modell von OpenAI) wiederholt.
Es stellte sich heraus, dass die Themenextraktion (z. B. Bedürfnisse, erwartete Angebots- merkmale, Wechselgründe) sehr gut funktioniert. Im Vergleich zum manuell erstellten Bericht wurden praktisch 100 % der Themen erkannt und in den Zusammenfassungen erwähnt.
Hochentwickelte Modelle wie ChatGPT4 schaffen auch eine gute, nahtlose Integration der Originalsprachen z. B. in einen englischen Bericht. Dies gilt allerdings nur für weit verbreitete Sprachen – in Europa z. B. Deutsch, Französisch, Italienisch und Spanisch.
Bei der qualitativen Analyse geht es nicht darum, Kategorien oder Themen auszuzählen Dennoch macht es Sinn, typische Argumentationsmuster von vereinzelten Argumenten zu differenzieren. Kann die generative KI bei der Analyse von Themen in einem umfangreichen Text-Datensatz relevante von weniger relevanten Themen unterscheiden? Im Test mit 20 Interviews zum Thema «Versicherung» hat das gut funktioniert.
Die Analyse-Ergebnisse in Reports des Qualitativen Consumer Research werden oft mit wörtlichen Zitaten illustriert. Mit einem entsprechenden Prompt liefert das KI-Modell passende Zitate, die in ca. 80 % der Fälle nicht modifiziert sind. Teilweise werden die Zitate leicht umformuliert. Auch diese zeitaufwändige Aufgabe erledigt die KI also mit hoher Zuverlässigkeit.
KI kann Empfehlungen formulieren. Das Projekt hat allerdings gezeigt, dass die KI kaum in der Lage ist, die entscheidenden Schlussfolgerungen und Insights unter Berücksichtigung der strategischen Fragestellung, der Marktsituation und des Business Modells der Auftraggeberin zu formulieren. Diese Aufgabe sollte unbedingt eine Senior Marktforscherin oder ein erfahrener Insight-Spezialist übernehmen.
Dies ist ganz klar kein Argument gegen den Einsatz von KI in der qualitativen Marktforschung. Die Ergebnisse verschiedener Projekte zeigen, dass – im Vergleich zum bisherigen, vollständig manuellen Vorgehen – 40 bis 60 % des gesamten Zeitaufwandes eingespart wird. Damit macht KI qualitative Consumer Insights für Auftraggeber sowohl in Bezug auf die Kosten wie auch auf eine agile Umsetzung deutlich attraktiver und somit wettbewerbsfähiger.
Use Case 2: Jenseits von statischen Insight-Reports Consumer Insight Reports verstauben oft im Archiv der Auftraggebenden. Mit generativer KI ergeben sich vollkommen neue, bisher nicht mögliche Wege, um End-Usern einen Mehrwert zu liefern.
Im konkreten Anwendungsfall wurden acht Tiefeninterviews zum Thema «Schokoladekonsum» durchgeführt. Die KI wurde spezifisch darauf trainiert, innovative Produktkonzepte zu entwickeln, die anschliessend in einer strukturierten quantitativen Online-Erhebung validiert werden können.
Das Konzept wurde also durch das KI-Tool unmittelbar auf Basis der ungefilterten Konsumentenbedürfnisse und unter Berücksichtigung der Sprache der Konsumentinnen und Konsumenten erstellt. Im Test hat die KI plausible, klar formulierte Konzepte entwickelt, die auf relevanten Konsumentenerwartungen aufbauen. Inwieweit diese Ideen bei den Zielgruppen besser oder mindestens gleich gut abschneiden wie von Expertinnen formulierte Konzepte, ist in einem weiteren Schritt zu prüfen.
Durch diesen «Prompt Your Data»-Ansatz gewinnen qualitative Konsumentendaten enorm an Wert. Die Daten können jederzeit auf aktuelle Hypothesen und Innovationsideen abgefragt werden. Die Daten stehen live als «Voice of Consumer» zur Verfügung, ohne Informationsverlust durch Zusammenfassung in einem statischen Bericht.
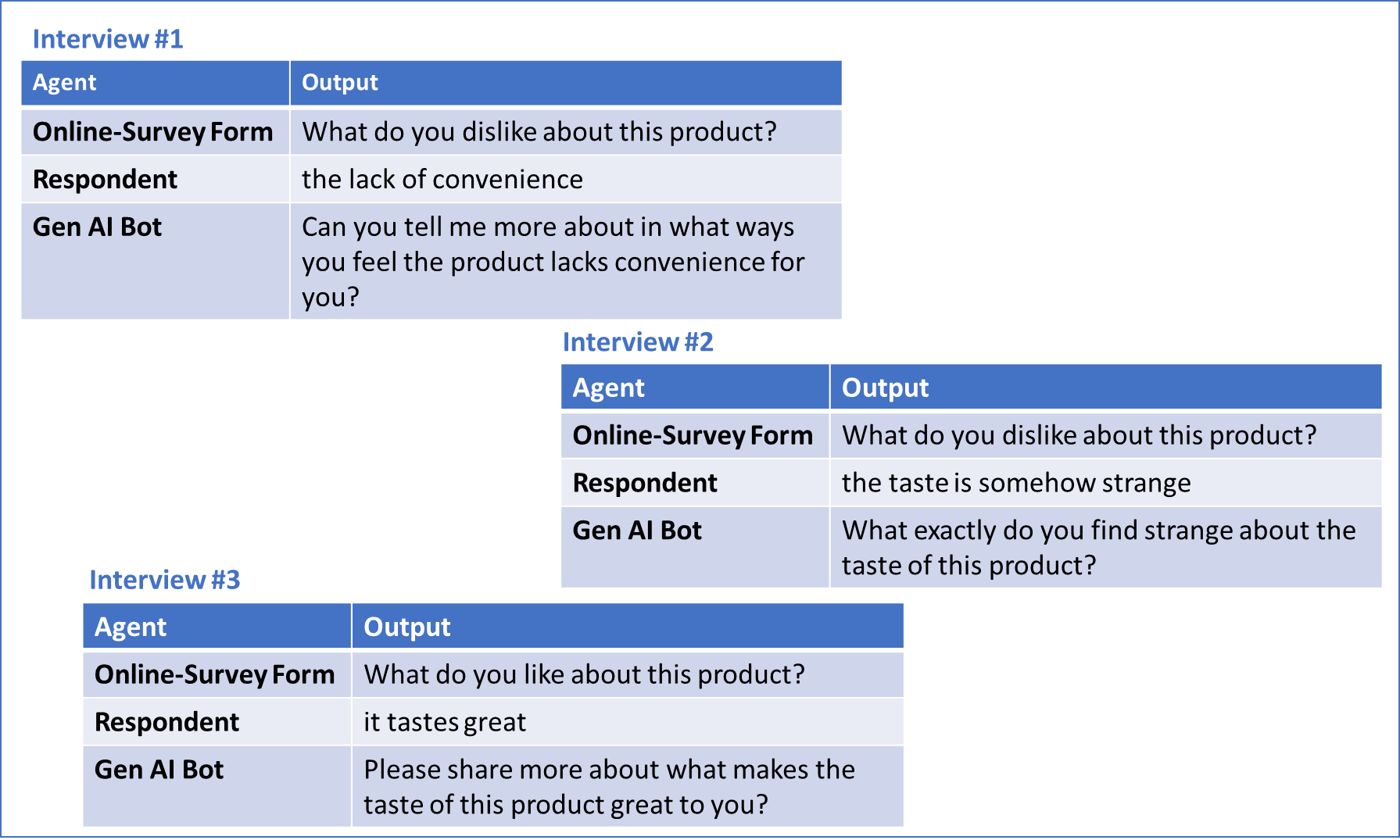
Use-Case 3: Neutrales Nachfassen bei offenen Fragen in Online-Interviews Offene Fragen in strukturierten Interviews liefern vertiefte Erkenntnisse zum «Warum?» hinter dem «Was?» der quantitativen Auswertungen. Mit einer gezielten Nachfrage kann eine Interviewerin differenziertere und detailliertere Antworten erhalten. Bei Online-Interviews war ein solches neutrales, motivierendes Nachfragen bisher kaum möglich. Generative KI hat das Potenzial, diese Aufgabe abwechslungsreich und ohne Suggestivfragen zu erfüllen. Als Input benötigt ein entsprechend trainiertes Modell die ursprüngliche Frage plus die Antworten der Befragten. Die folgende Darstellung illustriert, wie ein solcher Dialog abläuft.
Ethik und Datenschutz
Viele Fragen der Ethik, des Datenschutzes und des Urheberrechts sind im Kontext der generativen KI noch nicht gelöst. Auch sind Urteile im Rahmen der neuen Gesetzgebung – insbesondere auch die Implikationen des EU AI Act – noch ausstehend. Markt- und Sozialforscherinnen tun deshalb gut daran, die bisherigen Grundsätze auch bei der Anwendung der KI zu befolgen, insbesondere die Anonymisierung der Daten zum frühest möglichen Zeitpunkt. Automatisierte Tools, die PII wie Namen oder Orte ausfiltern können, bieten dabei Unterstützung. Selbstverständlich muss die Weitergabe von individualisierten Erkenntnissen für Marketing-Zwecke weiterhin ausgeschlossen bleiben. Eine Herausforderung ist die Tatsache, dass die leistungsfähigsten KI-Modelle von OpenAI, Google und Anthropic auf Servern in den USA laufen. Dies ist in der Schweiz und in der EU trotz der Verfügbarkeit eines DPA (Data Processing Agreements) z. B. von OpenAI ein Problem. Als vorläufige Lösung können Modelle genutzt werden, die auf Schweizer oder EU-Servern laufen.
Der Autor Dr. Stefan Oglesby ist Inhaber der data IQ AG und Gründer von insight-lab.ai, einer Plattform für die Analyse und interaktive Nutzung qualitativer Consumer Insights. Er hat langjährige Erfahrung in der qualitativen und quantitativen Marktforschung auf Auftraggeber- und Institutsseite.
Der Appetit auf pflanzliche Proteine wächst weltweit. Konsument:innen sind sich zunehmend der negativen Umweltfolgen durch die Produktion von tierischen Lebensmitteln, der Tierwohlproblematik und der möglichen gesundheitlichen Risiken eines übermässigen Fleisch- und Milchproduktekonsums bewusst. Als Reaktion auf diesen steigenden Trend zur Reduktion tierischer Produkte bemühen sich Lebensmittelhersteller, Alternativen zu Fleisch- und Milchprodukten zu entwickeln; Alternativen, die nicht nur eine ausreichende Versorgung mit Nahrungsmitteln besser gewährleisten, sondern auch ein mit tierischen Produkten vergleichbares sensorisches Erlebnis bieten.
Konsument:innen, insb. Flexitarier:innen, welche den Konsum von tierischen Produkten bewusst reduzieren, erwarten bei pflanzlichen Proteinalternativen in Bezug auf Aussehen, Aroma, Geschmack und Textur ein ähnliches sensorisches Erlebnis wie bei den tierischen Analogien. Dies stellt die Produktentwickler:innen vor komplexe Aufgaben: «Wie kann man den rahmigen Geschmack von Milch nachahmen?» oder «Wie lässt sich die fleischige Textur eines Burgers mit Pflanzenproteinen reproduzieren?». Ähnliche Herausforderungen stellen sich bei Käse-Alternativen: «Wie kann man auf pflanzlicher Basis die charakteristische Konsistenz und das unverwechselbare Aroma von Käse nachbilden?». Marktforschungsinstitute spielen eine entscheidende Rolle, wenn es darum geht, die Erwartungen der Konsument:innen zu identifizieren und den Herstellern die notwendigen Einblicke zu liefern. Durch sensorische Tests und umfassende Verbraucherbefragungen können wertvolle Daten gewonnen werden, welche die Grundlage für die Entwicklung und Optimierung entsprechender veganer Produkte bilden.
Konsumententest von pflanzenbasierten Käse-Alternativen
Pflanzliche Fleischersatzprodukte konnten in den letzten Jahren im schweizerischen Lebensmittelhandel eine beachtliche Regalfläche erobern – auch mit neuen, in der Schweiz gegründeten Marken. Dagegen gelten pflanzliche Käse-Alternativen noch immer als Nischenprodukte. Da die Schweiz ein «Käse-Land» ist, hat die IG-Sensorik Schweiz dieses Thema im Jahr 2023 im Rahmen eines Forschungsprojektes etwas genauer unter die Lupe genommen. Als Mitglied der IG-Sensorik Schweiz war das Marktforschungsinstitut SensoPLUS Projektpartner bei dieser Studie, die als Zusammenarbeit von sechs schweizerischen, in der Lebensmittelsensorik tätigen Institutionen durchgeführt wurde*.
Ziel des Projektes war, die sensorische Konsumentenwahrnehmung von pflanzenbasierten Käse-Alternativen zu evaluieren und dabei Konsumenten-Insights über den bestehenden Markt dieser Produkt-Nische zu erhalten. Sechs im Handel erhältliche Käse-Alternativen wurden beurteilt, davon zwei «Typ Weichkäse», zwei «Typ Halbhartkäse am Stück» und zwei «Typ Halbhartkäse in Scheiben».
Die Konsumentenbefragung wurde mittels eines Central Location Tests bei 245 Flexitarier:innen durchgeführt. Gesamteindruck und Aussehen wurden anhand der in der Lebensmittelbranche üblichen hedonischen 9-Punkte-Skala bewertet. Wesentliche Produkteigenschaften betreffend Geschmack/Aroma und Konsistenz wurden mit einer JAR-Skala (JAR = Just about right) beurteilt. Für weitere produktbeschreibende Informationen wurde die bei sensorischen Konsumententests bewährte CATA-Methode (CATA = Check-all-that-apply) verwendet. Dabei konnten aus 39 produktspezifischen Merkmalen zu Aussehen, Konsistenz und Geschmack/Aroma die für das jeweilige Produkt zutreffenden angeklickt werden.
Für die Datenerfassung des Konsumententestes wurde die vom SensoPLUS-Software-Team entwickelte Sensorik-Software SensoTASTE verwendet.
Grosses Potenzial für Optimierung
Die Studie der IG-Sensorik Schweiz zeigte, dass die sensorischen Eigenschaften von pflanzenbasierten Käse-Alternativen den Konsumentenerwartungen noch nicht ausreichend entsprachen. Ein einziges Produkt wies für den Gesamteindruck auf der hedonischen 9er-Skala einen Mittelwert auf, welcher auf der positiven Seite lag (siehe Abbildung 1). Mit einem Wert von 5.8 war diese Akzeptanz jedoch auch nicht wirklich überzeugend. Die Datenanalyse der JAR-Bewertungen und der CATA-Methode identifizierten Einflussfaktoren für negative Auswirkungen auf den Gesamteindruck. Diese lagen insbesondere im Bereich der Konsistenz, zum Beispiel Eigenschaften wie fest, gummig, elastisch oder mehlig, aber auch in den Bereichen Aussehen und Aroma.
Die eher tiefe hedonische Beliebtheit beeinflusste auch die Kaufabsicht. Beim am besten bewerteten Produkt wurde eine Kaufwahrscheinlichkeit von 52 % ermittelt. Die weiteren Produkte würden mit einer mittleren Wahrscheinlichkeit von 17 % bis zu 36 % gekauft werden.
Die Studienteilnehmenden beurteilten pflanzliche Alternativen im Vergleich zu tierischer Milch und Milcherzeugnissen positiver in Bezug auf Trend, Tierwohl, Klimafreundlichkeit und Gesundheitsaspekte (Abbildung 2). Die pflanzenbasierten Alternativen wurden jedoch als weniger schmackhaft wahrgenommen als das vergleichbare tierische Produkt, dies insbesondere von jenen Flexitarier:innen, welche regelmässig Fleisch konsumieren Nachhaltigkeits- und Tierwohlaspekte allein reichen also nicht aus, um Konsument:innen zu einem wiederkehrenden Kauf zu bewegen.
Gesamteindruck und Aussehen von Käse-Alternativen mittels hedonischer 9er-Skala
Abbildung 1: Gesamteindruck (satter Farbton) und Aussehen (blasser Farbton) mit Mittelwert, Standardabweichung und Signifikanz (unterschiedliche Buchstaben, p=0.05) von ausgewählten Käse-Alternativen (n=245); Poster Eurosense, 2024, IG Sensorik Schweiz
Um pflanzliche Ersatzprodukte dauerhaft in die Ernährung zu integrieren, muss auch das Geschmackserlebnis die Erwartungen erfüllen. Ziel der Lebensmittelbranche sollte es daher sein, das sensorische Profil von pflanzenbasierten Proteinalternativen weiter zu optimieren. Die Marktforschungsinstitute können mit gezielten Analysen und Tests dazu beitragen, die Lücken zwischen Konsumentenerwartungen und den tatsächlichen Produkteigenschaften zu schliessen. In diesem Sinne hat die IG-Sensorik Schweiz nun eine Folgeprojekt zu Fleischalternativen gestartet.
Abbildung 2: Vergleich tierischer Milch und Milcherzeugnisse zu pflanzlichen Alternativen; Präsentation DACH 3-Länder-Tagung Sensorik, 2023, IG Sensorik Schweiz
*Projektzusammenarbeit Käse-Alternativen, IG Sensorik Schweiz: Hochschulen (ETHZ, ZHAW, BFH), Forschungsinstitution (Agroscope) und Marktforschungsinstitute (SAM und SensoPLUS). Für detaillierte Projekt-Information, auch zu der neben der Konsumentenbefragung durchgeführten sensorischen Produktprofilierung, der Nährwertanalyse und zum Life Cycle Assessment, dürfen Sie gerne Kontakt aufnehmen.
Die Autorin Susanne Aegler leitet das Marketing und die Sensorik bei SensoPLUS. Sie ist Lebensmittel- Ingenieurin ETH Zürich und verfügt über einen MSc in Human Nutrition, King’s College, London.
Mit webbasierten Befragungen lassen sich neue Zielgruppen realisieren. Neben der günstigen Zugriffsmöglichkeit, geografischer Unabhängigkeit und logistischen Vorteilen werden aber auch unseriöse Teilnahmen begünstigt. Der Anteil an verschmutzten Daten nimmt zu und die Aussagekraft der Ergebnisse wird vermindert. Weiter kann eine Website im Gegensatz zu einem handfesten PapierFragebogen auch das «Gefühl einer geringeren Verantwortlichkeit vermitteln» (Johnson, 2005, S. 108). Dies stellt eine ernsthafte Bedrohung für die Validität der Online-Forschung dar (Oppenheimer et al., 2009; Reips, 2002, 2009; Meier & Gwerder, 2022).
Im Gegenzug liefern Onlineumfragen meist auch Metadaten wie Ausfüllzeiten insgesamt, Ausfüllzeiten vom Laden der einzelnen Frage bis zu deren Beantwortung, Browserkennung, Betriebssystem, Bildschirmgrösse, IP-Adresse, Mausbewegungen und weitere Informationen, welche nach der Feldphase, wenn alle gesammelten Daten vorliegen, für ein Screening unaufmerksamer Antworten herangezogen werden können (Barge & Gehlbach, 2012; Bauermeister et al., 2012; Meade & Craig, 2012; Meier & Gwerder, 2022).
Mit unserem Artikel möchten wir einen Über-blick über verschiedene Techniken zur Messung der Aufmerksamkeit in Onlineumfragen ermöglichen – Techniken, die durch akademische Erkenntnisse bestätigt oder überprüft wurden und/oder sich in der Praxis bewährt haben, um die Anzahl «schlechter Antworten» zu begrenzen.
Aber was sind «schlechte Antworten»?
Generell werden als «schlecht» jene Antworten angesehen, die nicht die eigentliche Meinung oder das Wissen der Umfrageteilnehmenden wiedergeben, sondern irgendetwas anderes im Sinne eines Messfehlers. Die Gründe, weshalb Teilnehmende «schlechte» Antworten abgeben, sind vielfältig: Sie verweigern das korrekte Ausfüllen und geben stattdessen Fake-Antworten ab, sie sind schlichtweg abgelenkt, wissen die Antworten nicht oder nehmen sich nicht die nötige Zeit, ihre Antworten sorgfältig abzufüllen oder in die Antwortformate einzupassen. Dabei gibt es eine Auslegeordnung, was solche «schlechten» Daten angeht:
Als sogenannte «sinnlose Antworten» oder auch «content responsive faking» (Meade & Craig, 2012; Burns & Christiansen, 2011) werden in der Regel jene Antworten verstanden, bei denen Teilnehmende die Frage an sich aufnehmen und verstehen, aber bewusst keine gültige Antwort geben wollen («intended faking»). Dazu zählen betrügerisches Ausfüllen, z. B. in psychologischen Testverfahren wie dem MMPI2 (Rogers, 2003) oder in Job Assessments (Delgado, 2011) – aber auch bewusstes oder unbewusstes item-bezogenes, sozial erwünschtes Antwortverhalten (Paulhus, 1984).
Demgegenüber stehen «content nonresponsivity» Antworten, die in keinem Zusammenhang zum Inhalt der Fragen stehen (Nichols et al., 1989; Desimone et al., 2018). Sie werden auch als «random response» (Beach, 1989; Berry et al, 1992), «careless responding» (Curran, Kotrba, & Denison, 2010) oder «protocol invalidity» (Johnson, 2005) bezeichnet. Darunter fallen auch die Subkategorien «response sets» (Jandura, Peter, & Küchenhoff, 2012) und «response styles» (Van Vaerenbergh & Thomas, 2012) – alles formale Verschmutzungen von Daten (Meier & Gwerder, 2022), die mehr oder weniger unabhängig von der Fragestellung und nicht zentraler Gegenstand dieses Artikels sind.
Eine Zwischenkategorie bilden Teilnehmende, die an sich bereit wären, eine gültige Antwort abzugeben, dies aber nicht vollumfänglich tun. Beim Satisficing-Verhalten lesen Befragte die Fragestellung lediglich oberflächlich und geben jene Antwort ab, die ihnen zuerst in den Sinn kommt oder ihnen plausibel erscheint (Krosnick, 1991, 1999; Krosnick, Nayaran, & Smith, 1996;). «Pseudoopinions» (Bishop, Oldendick, Tuchfarber, & Bennett, 1980) und «nonattitudes» (Franzén, 2011; Schuman & Presser, 1980) sind Antworten von Befragten, die nicht über das nötige Wissen verfügen, um eine passende Antwort auszuwählen, die Frage falsch oder gar nicht verstehen oder die Fragen und Antworten nicht oder nicht akkurat genug lesen können. Gerade bei Fragebögen für Kinder ist solches «unintentional random responding» häufig. Auch nicht-item-bezogenes, mehr persönlichkeitsbedingtes, sozial erwünschtes Antwortverhalten fällt in diese Zwischenkategorie. Erwähnt sei auch das Under- and Overreporting als Abweichung hin zu mehr oder weniger wahren Antworten durch zu positiv oder zu negativ konnotierte Fragen.
Umfrageforschende stellen sich dieser Herausforderung verminderter Aufmerksamkeit schon, bevor Daten erhoben werden. Dabei gibt es zwei Grundstrategien: Sie integrieren diskret eingewobene Aufmerksamkeitstests in die Fragebögen, um unaufmerksame Teilnehmende zu entlarven und zugunsten der Datenqualität aus der Analyse auszuschliessen, oder sie integrieren explizite, gut sichtbare Aufmerksamkeitsprompts, um Teilnehmende ganz offen darum zu bitten, aufmerksam zu antworten. Zur Erinnerung: Aus Sicht des traditionellen kognitiven Modells der Umfragebeantwortung (CMSR, Cognitive Model of Survey Response) von Tourangeau, Rips und Rasinski (2000) durchlaufen Antwortende vier Schritte: erstens das Verständnis der Frage, zweitens das Abrufen relevanter Informationen aus dem Gedächtnis, drittens das Bilden eines Urteils aufgrund der abgerufenen Informationen und viertens das Auswählen einer passenden Antwort resp. das Einpassen oder Editieren der Antwort in das vorgegebene Antwortformat. Das nur oberflächliche oder unvollständige Durchlaufen dieser Schritte nennt Krosnick (1991; 1999) «non-optimal response behavior». Diese fehlende Aufmerksamkeit beeinflusst den kognitiven Beantwortungsablauf auf mindestens vier Arten:
Teilnehmende verstehen die Frage nicht richtig, weil sie diese nicht oder nicht seriös gelesen haben. Dadurch werden nicht die richtigen Informationen abgerufen.
Es werden nicht alle Informationen abgerufen, was die Urteilsbildung verzerrt.
Ein Urteil wird heuristisch gebildet und weist eine mangelhafte Reliabilität auf.
Teilnehmende können die passende Antwortkategorie nicht auswählen, weil sie die verfügbaren Optionen nicht genügend aufmerksam verarbeitet haben.
Zusammengefasst: Unaufmerksamkeit führt zu Mess- und Non Response-Fehlern. Unaufmerksamkeit führt auch zu einer Situation, in der «das Rauschen, das durch Teilnehmer entsteht, die die Anweisungen nicht lesen, die Zuverlässigkeit der Daten verringert und die mit der Durchführung von Studien verbundenen Kosten erhöht, da die Anzahl der Teilnehmer, die für ein zuverlässiges Ergebnis erforderlich ist, künstlich erhöht wird» (Oppenheimer et al. 2009, S. 873).
Explizite Ernsthaftigkeitsprüfungen
Was kann nun aber konkret getan werden, um dieses komplexe Datenqualitätsproblem in Antwortdaten zu adressieren? Zunächst: Warum schwierig, wenn es auch einfach geht? Anstatt durch komplizierte Verfahren auf das Verhalten von Teilnehmenden zu schliessen, kann direkt gefragt werden, ob Aufmerksamkeit vorhanden war. Diesen Ansatz verfolgen Ernsthaftigkeitsprüfungen (engl. «seriouseness checks»). Durch Fragen wie «Gibt es Gründe, weshalb wir Ihre Antworten nicht in unsere Analyse einfliessen lassen sollten?» oder «Es wäre sehr hilfreich, wenn Sie uns an dieser Stelle mitteilen könnten, ob Sie ernsthaft teilgenommen haben, sodass wir Ihre Antworten für unsere wissenschaftliche Analyse verwenden können, oder ob Sie sich nur durchgeklickt haben, um sich die Umfrage anzuschauen.», wird den Teilnehmenden die Möglichkeit gegeben, offen zu deklarieren, dass sie die Befragung nicht gewissenhaft ausgefüllt haben (Aust, 2013). Als Antwortmöglichkeiten bieten sich an: «Ich habe ernsthaft teilgenommen» und «Ich habe nur durchgeklickt, bitte verwenden Sie meine Daten nicht für die Analyse» (s. Abbildung 1).
Abbildung 1: Expliziter Seriousness Check am Ende einer Befragung.
Die entsprechende Frage kann entweder zu Beginn (Reips, 2002, 2008, 2009) oder am Ende des Fragebogens platziert werden (Buchanan et al., 2010; Ihme et al., 2009). In der Praxis wird sehr oft die zweite Option bevorzugt, da die Teilnehmenden am Ende der Befragung ihr tatsächliches Verhalten während der Befragung zuverlässiger einschätzen können als ihr geplantes Handeln.
Ernsthaftigkeitsprüfungen wurden auch im Rahmen einer Befragung zu den Bundestagswahlen 2009 untersucht (Aust et al, 2013). Insgesamt gaben 112 (3.2 %) der 3’490 Teilnehmenden an, nicht seriöse Angaben gemacht zu haben. In der anschliessenden Analyse zeigte sich, dass die restlichen 3’378 Teilnehmenden konsistentere Angaben gemacht hatten und dass die Prognose des Wahlergebnisses besser mit der Realität übereinstimmte, wenn die 112 Fälle, die sich selbst als nicht ernsthaft deklariert hatten, ausgeschlossen wurden. Andere Autorinnen und Autoren fanden in unterschiedlichen Kontexten auch Werte in der Höhe von 5 bis 6 % oder 30 bis 50 % (Musch & Klauer, 2002; Reips, 2009). Grundsätzlich dürfte die Menge an unseriösen Teilnahmen stark vom Befragungskontext sowie von den Anreizen der Teilnehmenden abhängen. Beispielsweise ist bei Befragungen, bei welchen am Ende eine Belohnung winkt, mit sehr tiefen Selbstdeklarationsquoten zu rechnen, da die Teilnehmenden befürchten, auf eine Gewinnchance verzichten zu müssen, wenn sie zugeben, unseriös ausgefüllt zu haben. Dies hängt wohl stark davon ab, wie Ernsthaftigkeitsprüfung und «Gewinnseite» verquickt sind.
Die Herausforderung bei diesem direkten Ansatz liegt grundsätzlich in einer geschickten Formulierung, welche die Teilnehmenden zu einer ehrlichen Antwort motiviert, sie gleichzeitig aber nicht vor den Kopf stösst. Auch gibt es Befragungen, bei denen dieser Ansatz aufgrund der Beziehung zu den Teilnehmenden weniger geeignet ist. Beispielsweise besteht bei einer offenkundigen Ernsthaftigkeitsprüfung am Ende einer Kundenzufriedenheitsbefragung das Risiko, Kundinnen und Kunden, welche sich die Zeit für die Befragung genommen haben, zu verärgern oder zu irritieren, was bei diesem Anwendungsfeld von den Auftraggebenden weniger gut toleriert würde. Bei Panel-Befragungen und Studien hingegen eignet sich dieser Ansatz besser, solange eine ehrliche Antwort auf diese Frage den Erhalt der Incentivierung für die Umfrage nicht verhindert.
Fischers Fritz fischt rote Heringe
Eine weitere Methode zur Identifizierung von Aufmerksamkeit besteht darin, offenkundig falsche oder absurde Antworten in einen Fragebogen einzubauen. Was aber hat das mit Fischen zu tun? Im englischen Sprachgebrauch bezeichnet ein Red Herring (roter Hering) ein Element, das in die Irre führt oder von einer relevanten oder wichtigen Frage ablenkt.
In der Umfrageforschung ist mit einem Red Herring eine Ablenkungsfrage als Massnahme zur Qualitätskontrolle gemeint. In eine Reihe von regulären Fragen werden ungewöhnliche Fragen eingefügt, um damit diejenigen Teilnehmenden zu identifizieren, welche die Umfrage vollständig gelesen und sich mit den Inhalten beschäftigt haben resp. jene, die dies nicht getan haben. Die bei Befragungen zu den sinnvollen, regulären Fragen gehörenden Ablenkungsfragen umrahmen dabei oft die dadurch nicht mehr saliente, «getarnte» Validitätsfrage. Als Hypothese gilt: Wer den roten Hering nicht sieht, ist nicht aufmerksam bei der Sache. Im Folgenden wird auf mehrere solche «Heringsarten» eingegangen, bei welchen Teilnehmende den Datenqualitätsfischern «ins Netz gehen» können.
Fiktive Antworten
In der NZZ-Leserbefragung 2005/2006 ergab sich ein kurioses Ergebnis: 189 von 1’883 Teilnehmenden (10 %) gaben an, dass ihnen das NZZ-Folio-Magazin mit dem Thema «Katastrophen» von allen Folios am besten gefallen habe. Der Clou? Dieses Heft gab es nie. Im Fall der NZZ scheint es plausibel, dass einige der 189 Probanden das Folio mit dem Thema «Katastrophen» wählten, weil sie sich nicht an alle NZZ-Folios erinnern konnten, dies aber nicht zugeben wollten und daher ein Heft mit einem spannend klingenden Titel wählten (Porst, 2014). Dabei ist anzumerken, dass zusätzliche Antwortvorgaben wie «Ich kenne die NZZ-Folio-Magazine nicht», «keine Angabe/weiss nicht» oder «Ich kann mich nicht entscheiden» hilfreiche Ausweichkategorien gewesen wären, die im NZZ-Szenario bei dieser Frage zur Steigerung der Datenqualität beigetragen, jedoch umgekehrt weniger Rückschlüsse auf verminderte Aufmerksamkeit zugelassen hätten.
Zu diesem sogenannten antizipierenden Antwortverhalten im Falle von Unwissen sind historisch zahlreiche Beispiele bekannt. Bishop et al. (1986) beschreiben diesen «pressure to answer» ausführlich. So gaben 70 % der Befragten in einem Fragebogen eine klare Meinung zum «Metallic Metal Act» ab – einem völlig fiktiven Gesetz (Gill, 1947). Gleiches geschah mit 30.8 % zum «Agricultural Trade Act of 1978» (Schuman und Presser, 1981) und mit 26.4 % zum «Monetary Control Bill» (Schuman und Presser, 1981). Auch Werner Wilken, ein aktuell nicht existierender Politiker, wird regelmässig in Umfragen gekannt, aber «man stimmt mit seiner Politik nicht ganz überein» (Porst, 2014). Dies gilt auch für weitere fiktive Politikerinnen und Politiker (EMNID, 1981; Reuband, 2000). Und je höher die formale Schulbildung der Befragten, desto bekannter sind die Fiktiven.
Aber warum ist das so? Die Kognitionspsychologie liefert eine Antwort: Befragungen wird Sinn unterstellt («die Ersteller des Fragebogens werden wohl seriös gearbeitet haben»): sinnlose Antworten widersprechen der Erwartungshaltung der Teilnehmenden. Dazu kommt eine Hemmung, zuzugeben, dass man etwas nicht kennt, das offenbar allgemein bekannt sein muss, da in einem Fragebogen ja kaum Spezialwissen abgefragt wird. Diese Annahmen treffen gehäuft Befragte, von denen viel formales Wissen erwartet wird. Stellt sich dann noch die Frage, ob man mit seiner Politik einverstanden ist, müssen die Flunkerer erneut lügen. Da sie ihn nicht kennen, liegt es nahe, dass die Politik nicht den eigenen Präferenzen entspricht. Fragen mit fiktiven Antworten sind also nur eingeschränkt geeignet, um nicht vorhandene Aufmerksamkeit zu erkennen. Sie widerspiegeln häufig nur die menschliche Eigenschaft, sich nicht blamieren zu wollen und deshalb möglichst passende oder konsistente Kommunikation zu selekieren.
Bogus-Items
Sogenannte «Bogus-Items» bergen das Risiko von heuristischen, spekulativen oder sozial erwünschten Ersatzantworten wie im vorherigen Abschnitt beschrieben deutlich weniger, weil die «richtige» Antwort sehr offensichtlich ist. Es handelt sich dabei zum Beispiel um Aussagen wie «Wasser ist nass», bei denen auf einer Zustimmungsskala eigentlich nur «stimme voll und ganz zu» adäquat ist.
Wer diese Frage mit «stimme ganz und gar nicht zu» beantwortet, hat höchstwahrscheinlich den Fragetext nicht aufmerksam genug gelesen (Gummer et al., 2021). Eine ähnliche Bogus-Frage ist «Ich wurde am 30. Februar geboren» (Beach, 1989) oder «I am currently filling out a questionnaire» (Hargittai, 2009; Meade & Craig, 2012). Bogus-Items werden oft in längere Abfolgen von Likert-Skalen, meist auf derselben Seite («Tabellenfragen») im Sandwich eingebettet.
Es wird also Aufmerksamkeit gemessen – und lediglich bei nicht offenkundig oder extrem genug formulierten Items auch die Tendenz, Nichtwissen mit Vermutungen zu kaschieren. Eine falsche Antwort lässt bei geeigneten Bogus-Items tatsächlich kaum Zweifel offen, dass Teilnehmende unaufmerksam oder absichtlich falsch geantwortet haben: Die Wahrscheinlichkeit, dass jemand falsch positiv als unaufmerksame Person klassifiziert wird, ist also geringer. Aber Vorsicht: In Item-Batterien mit einem untergemischten Bogus-Item, in welchen a) alle Items die gleiche Skalenrichtung aufweisen und b) das Bogus-Item auch die richtige Antwort in dieser Richtung anbietet, können falsch negative Antworten entstehen – Nichtaufmerksamkeit bleibt dann unentdeckt, weil bei allen Items und zum Beispiel auch beim Bogus-Item «I am currently filling out a questionnaire» die «stimme voll und ganz zu»-Antwort – ohne zu lesen oder nachzudenken – ausgewählt wurde.
Teilnehmende erwarten in den meisten Umfragekontexten keine «Trick»-Items und laufen Gefahr, mit einer Zustimmungstendenz zu antworten, sobald das Item nur ausreichend schwammig formuliert ist (Meade & Craig, 2012). So könnten einige Teilnehmende dem Item «Meine Freunde vergleichen mich mit einem Pudel» tatsächlich willentlich zustimmen, weil Pudel soziale, verträgliche Tiere sind und Teilnehmende annehmen könnten, genau dies solle latent mit diesem Item «gemessen» werden. Auch hier kommt das kognitionspsychologische Thema «Sinn und Sensemaking» (Weick, 1995) zum Vorschein. Das Ziel von fiktiven Fragen und Bogus-Items ist es also, unaufmerksame Teilnehmende mit einer Antwort zu erwischen, die nicht möglich ist. Bei Bogus-Items (hier sind auch einfache Rechenaufgaben wie «2+3=?» beliebt) kann mit hoher Wahrscheinlichkeit davon ausgegangen werden, dass Teilnehmende, die diese nicht korrekt beantworten, zu wenig aufmerksam sind. Bei fiktiven Fragen/Items dagegen (wie jener zu den NZZ-Folios) ist es möglich, dass auch aufmerksame Personen den Check nicht bestehen. Dies kann jedoch aus Sicht der Datenqualität auch wünschenswert sein: Ist das Ziel der Befragung die Identifikation der besten Magazin-Ausgabe dieses Jahres, sollten optimalerweise nur Personen in der Stichprobe sein, die sich genügend mit dem Magazin auseinandersetzen, um dessen Ausgaben in einer Liste wiederzuerkennen. Es geht dann aber nicht nur um den Ausschluss von Unaufmerksamkeit, sondern auch von weiteren Störvariablen wie Inkompetenz, sozialer Erwünschtheit oder inhaltsunabhängiger Zustimmungstendenz/Akquieszenz (Bauer, 2000).
Der Wirkungsgrad des Einsatzes von Bogus-Items zur Erkennung von Nichtaufmerksamkeit wurde breiter diskutiert (Breitsohl and Steidelmüller, 2018; Curran, 2016; Goldsmith, 1989), es wurde aber nur eine spärliche qualitätsverbessernde Wirkung attestiert und es wurden andere Methoden, zum Beispiel das blosse Einbauen von «Weiss nicht»-Antworten, die einen veritablen Teil der unsicheren oder antwortunwilligen Personen abfangen.
Anweisungsprüfungen (IMC, IRI)
Ein weiterer Ansatz zur Überprüfung der Aufmerksamkeit von Teilnehmenden ist die Integration von Anweisungsprüfungen. Hier erhalten die Teilnehmenden eine klare Anweisung zur Beantwortung. Wer diese Anweisung nicht befolgt, weist einen ungenügenden Grad an Aufmerksamkeit auf.
Anweisungsprüfungen können in Form einer ganzen Frage («Instructional Manipulation Checks» IMC) umgesetzt werden. Diese werden auch «screener» genannt (Berinsky et al., 2014). Ein Beispiel ist das Hinzufügen eines zusätzlichen Satzes am Ende einer Frage – eine Bemerkung, die den Befragten anweist, die Frage zu ignorieren und eine bestimmte Antwort zu geben, zum Beispiel «Bitte ignorieren Sie diese Frage und wählen Sie unten die vierte Antwort an.» (Alvarez & Li, 2021). Weitere Beispiele zeigen Abbildungen 2 und 3.
Abbildung 2: Instructional Manipulation Check mit hohem Schwierigkeitsgrad (Kung, 2018)
Abbildung 3: Instructional Manipulation Checks mit mittlerem Schwierigkeitsgrad (eigenes Beispiel)
Als zweite Form kann ein einzelnes Item innerhalb einer ansonsten inhaltlich relevanten Tabellenfrage implementiert werden («Instructed Response Items» IRI), beispielsweise als fünftes Item von acht mit dem Wortlaut «Wählen Sie in dieser Zeile ‘sehr zufrieden‘ an». (Gummer et al., 2021; DeSimone et al., 2015). Ein weiteres Beispiel zeigt Abbildung 4.
Abbildung 4: Instructed Response Item (IRI) in Zeile 6 (angelehnt an Podsakoff et al., 1990)
IMC und IRI finden in der Umfrageforschung unter anderem aufgrund der relativ einfachen Umsetzung grossen Anklang.
Die Exklusion von Teilnehmenden, welche IMCs nicht bestehen, führt dann zu höherer Konsistenz in der Datenanalyse (Oppenheimer et al., 2009). Das Exkludieren von IRI-Fällen aus dem Datenmaterial wird allerdings kontrovers diskutiert und hat nicht in allen Fällen eine höhere Datenqualität zur Folge (Gummer et al., 2021; Grezki et al., 2015; Anduiza & Galais, 2016). IRIs sind aber wie herkömmliche Methoden definitiv genauso oder teilweise sogar etwas zuverlässiger in der Lage, nichtseriöse Teilnehmende zu identifizieren (Jones et al., 2015; Gummer et al., 2021), beispielsweise mittels Messung der Bearbeitungsdauer (Speeder) oder der Identifikation von Null-Varianz-Antwortverhalten, sogenanntem Straightlining (Meier & Gwerder, 2022).
Moderne Systeme für Onlineumfragen können bei falsch beantworteten IMC und IRI die Frage auch nochmals stellen mit dem Hinweis, dass eine unplausible Antwort gegeben wurde, und der Bitte, die Fragen und Antworten genau zu lesen. Mit dieser alternativen Strategie sollen die fehlbaren Teilnehmenden nicht mehr ausgeschlossen werden. Sie sollen ihre Antworten korrigieren. Und genau dieses erneute Stellen einer IMC, so lange, bis die Teilnehmenden diese bestehen, führt zu erhöhter Aufmerksamkeit in den Folgefragen. Daher sollte diese spezifische Variante von IMC und IRI dann auch in einer der ersten Fragen des Fragebogens umgesetzt oder alternativ vor besonders wichtigen Fragen platziert sein, deren Beantwortung besonders gewissenhaft erfolgen soll. Diese Erkenntnis wurde in weiteren Studien besonders auch für komplexe Folgefragen bestätigt (Miller & Baker-Prewitt, 2009; Hauser & Schwarz, 2015), was den Wert von Anweisungsprüfungen als «moral changer» unterstreicht. Wie bei den Ernsthaftigkeitsprüfungen liegt die Herausforderung der Anweisungsprüfungen bei der Akzeptanz der Befragten. Eine oder in langen Fragebögen zwei IRIs oder IMCs werden von den meisten Teilnehmenden akzeptiert, eine zu hohe Zahl kann Befragte jedoch verärgern und deren Motivation negativ beeinflussen.
Pseudo-Fragen
Eine Alternative zu Anweisungsprüfungen stellen sogenannte «Mock Vignettes» dar, eine kurze Aufmerksamkeitsprüfung («Mock Vignette Check», MVC), die vor der eigentlichen Befragung eingefügt wird. Die Teilnehmenden werden dabei aufgefordert, einen kurzen informativen Text («Vignette») zu lesen und anschliessend einige Fragen dazu zu beantworten. Mit diesen Fragen wird geprüft, ob die Vignette aufmerksam gelesen und korrekt verstanden wurde. Teilnehmende, welche einen eingangs gestellten MVC bestehen, weisen im weiteren Fragebogenverlauf (gemessen an typischen Aufmerksamkeitsmetriken) höhere Aufmerksamkeit aus (Kane et al., 2023). Ausserdem zeigte sich, dass die zu Beginn des Fragebogens gestellten Pseudo-Fragen keinen negativen Effekt auf das Antwortverhalten im restlichen Fragebogen aufweisen, diesen also abgesehen von den Auswirkungen höherer Aufmerksamkeit nicht beeinflussten. Eine solche «Mock Vignette» zu Beginn des Fragebogens könnte mit einer Formatübung kombiniert werden, um die Teilnehmenden auf die Fragetypen vorzubereiten. Zum Beispiel: Diese erste Frage ist inhaltlich nicht relevant. Wir möchten Sie mit dem Ausfüllen vertraut machen und bitten Sie, den folgenden Text trotzdem genau zu lesen und die vier Fragen dazu auf der folgenden Seite korrekt zu beantworten.
Unserer praktischen Erfahrung nach sind solche experimentell anmutenden Checks für Kunden- und Mitarbeitendenbefragungen leider nur eingeschränkt geeignet und werden von Auftraggebenden selten akzeptiert, da Teilnehmende das Gefühl haben könnten, unter einen Generalverdacht mangelnder Aufmerksamkeit gestellt worden zu sein. Gummer et al. (2021) stellen in ihrer Studie denn auch fest, dass ein nicht unerheblicher Teil der Befragten Aufmerksamkeitskontrollen als lästig (16.8 %), verwirrend (10.1 %), manipulierend (10.4 %) oder als Kontrolle empfanden (25.0 %) resp. nicht belehrt werden wollen (24.3 %). Immerhin befand ein Drittel der Stichprobe (31.4 %) Aufmerksamkeitskontrollen als motivierend.
Widersprüchliche Antwort-Paare/-Sets
Widersprüchliche Antworten über zwei oder mehr inhaltlich gleiche Fragen hinweg sind eine weitere Methode, um Aufmerksamkeit zu erkennen. Und sie können in der Regel bei der Betrachtung einzelner Fragebogen relativ einfach identifiziert werden. Geben Teilnehmende bei zwei Fragen, die dasselbe Konstrukt erfassen, komplett unterschiedliche Antworten, oder ist eine bestimmte Antwort-Kombination schlichtweg unmöglich (beispielsweise ein 21-jähriger Student mit 15 Jahren Berufserfahrung), kann dies ein Hinweis darauf sein, dass Befragte dem Fragebogen nicht genügend Aufmerksamkeit schenken. Wenn eine Befragung zahlreiche Tabellenfragen enthält, kann bei der ersten und bei der letzten Tabellenfrage je einmal dasselbe Item eingebaut werden (z. B. «Meine Arbeitsstelle gefällt mir sehr.» und «Ich bin mit meiner Arbeitsstelle sehr zufrieden.»). Es kann dann überprüft werden, ob die Antworten diametral abweichen. Solche Fälle können dann für die Analysen exkludiert werden.
Aber Achtung: Bei heiklen Themen sind auch die aufmerksamen Teilnehmenden nicht a priori willig, wahre Antworten zu geben. In einer aktuellen Online-Studie zu riskantem Cannabisgebrauch fanden sich ähnliche Werte – 45.3 % der Teilnahmen wiesen inkonsistente Antworten auf (Schell et al., 2022). Wie aber sollte nun mit widersprüchlichen Antworten als Indikator für fehlende Aufmerksamkeit verfahren werden? Geeignete Methodiken für die jeweilige Befragung könnten sein (Bauer & Johnson, 2000):
Nichts tun: Auch widersprüchliche Antworten werden für die Analyse verwendet. Die Anzahl gibt lediglich einen Hinweis auf die Datenqualität und relativiert die Ergebnisse und deren Interpretation im Sinne eines Konfidenzintervalls.
Torhüter («Gatekeeper»): Nur die erste Antwort eines Falles wird für die Analyse verwendet. Darauffolgende einzelne Antworten, welche der ersten widersprechen, werden als «missing items» umcodiert. Der Datensatz an sich fliesst mit ein.
Limitierter Ansatz: Es wird eine Liste von besonders wichtigen Fragen definiert. Widerspricht sich ein/e Teilnehmer/in innerhalb dieser wichtigen Fragen, werden alle Antworten der Teilnehmerin/des Teilnehmers bei diesen wichtigen Fragen als «missing items» in die Ergebnisse aufgenommen.
Globaler Ansatz: Sämtliche Fälle mit inkonsistenten Antworten werden aus der Analyse ausgeschlossen.
Ansatz der inhaltlich überwiegenden Beweislage. Der Fragebogen und die besonders wichtigen Fragen aller Befragten, welche widersprüchliche Antworten gaben, werden sorgfältig geprüft und der Fallstatus wird auf der Grundlage der «überwiegenden Beweislage» zugewiesen, die durch die Auswertung der Antworten ermittelt wird (z. B. wenn es darum geht, Fragebögen zu typisieren und einer Kategorie zuzuordnen). Alle Antworten, die dem zugewiesenen Fallstatus widersprechen, werden als «missing items» betrachtet.
Je nach verwendetem Ansatz zum Umgang mit inkonsistenten Antworten ergibt sich eine unterschiedliche Zahl von exkludierten Fällen – 33 bei «nichts tun» bis zu 1374 beim «globalen Ansatz» (Bauer & Johnson, 2000) – und es ergeben sich damit signifikant unterschiedliche Analyseergebnisse. Es ist daher von grosser Bedeutung, die gewählte Methode kritisch zu bewerten und im Auswertungsreport genauestens zu deklarieren.
Umgepolte Items
Eine Spezialform widersprüchlicher Angaben sind doppelte Items, von denen eines rotiert ist. Solche «Fallen» (wir sind wieder bei roten Heringen) müssen dann zweimal genau entgegengesetzt beantwortet werden, ansonsten wäre eine Antwort widersprüchlich. Zum Beispiel kann ein Item im ersten Teil des Fragebogens untergebracht werden, ein zweites Item dann gegen Ende, wobei typischerweise dieselbe Likert-Skala verwendet wird. Das zweite Item erfragt denselben Inhalt wie das erste in leicht veränderter Formulierung, wird aber negiert (= rotiert) formuliert. Beispielsweise kann gefragt werden: «Das Produkt gefällt mir im Allgemeinen sehr gut.» (5-er-Skala von «trifft sehr zu» bis «trifft gar nicht zu»). Im weiteren Fragebogenverlauf könnte mit ausreichend grossem Abstand gefragt werden: «Ich finde die Produkte generell mangelhaft.» (5-er-Skala von «trifft sehr zu» bis «trifft gar nicht zu»). Konsistentes, aufmerksames Ausfüllverhalten müsste hier mindestens einigermassen diametrale Ergebnisse erzeugen. Die beiden Skalenwerte innerhalb desselben Falles dürften nach Umpolung eines der beiden Items (Gleichausrichtung) nur eine geringe Varianz aufweisen. Fälle, bei denen diese Bedingung verletzt wurde, könnten wegen Nichtaufmerksamkeit für die Datenanalyse exkludiert werden. Ein konkretes Beispiel zeigt Abbildung 5.
Abbildung 5: Erstes und drittes Item rotiert (angelehnt an Podsakoff et al., 1990)
Es ist allerdings zu bedenken, dass reverse Items unterschiedliche Bedingungen für gute und schwächere Leserinnen und Leser schaffen, da negativ formulierte Items eine höhere Sprachkompetenz und höheren kognitiven Aufwand erfordern und damit einen Bias in die Ergebnisse einsteuern können (Suárez-Alvarez et al., 2018), vor allem bei sprachlich schwächeren Zielgruppen (z. B. bei Kindern und Jugendlichen).
Offensichtliche Fragen
Eine weitere Technik zur Aufmerksamkeitsprüfung sind Fragen, die eine einzige plausible Antwort zulassen, nämlich «trifft zu». Werden solche Fragen auf einer Likert-Skala mit «trifft nicht zu» beantwortet, kann auf mangelnde Aufmerksamkeit geschlossen werden. Beispiel: «Es gibt Menschen, die eine andere Meinung haben als ich» oder «E ist ein Buchstabe». Allerdings ist eine Abstützung auf einzig diese Art von Aufmerksamkeitscheck kaum empfehlenswert und solche Fragen laufen Gefahr, als deutliche Fremdkörper wahrgenommen zu werden, weil deren Funktion von einer Vielzahl an Befragten nicht verstanden wird und sie dadurch irritierend wirken.
A Priori Fakes mit Bots
In den letzten Jahren wurde ein neues Problem erkannt, welches auf den ersten Blick aussieht wie aufmerksamkeitsloses Ausfüllen: das Einsetzen von Botnetzen (automatisierten Scripts, die Formulare ausfüllen) und dedizierten Umfrage-Bots zur Beantwortung kompletter Fragebogen, auch mit offenen Textantworten, bei welchen qualitätsmässig komplett sinnlose, willkürliche Antworten technisch abgefüllt werden. Dabei erzielen Teilnehmende im besten Fall Vergütungen für komplettierte Fragebögen, ohne dass sie selbst tatsächlich Fragen beantworten (Dupuis, 2018; Fullerton und McCullough, 2022). Gegen diese Techniken gibt es wenige wirkungsvolle Massnahmen. Das Abfragen einer anonymen «uniform identifier», einer «einzigartigen Identifikationskennung der Teilnehmenden». So kann beispielsweise in einer Single-Choice-Frage mit einigen Antwortvorgaben das Domizilland der Teilnehmenden abgefragt werden, wobei Bots dann über alle Datensätze hinweg in der Regel eine breite Varianz erzeugen, echte Teilnehmende aber nur das effektive Land auswählen, in dem sie wohnen und in dem die Studie auch durchgeführt wird oder nach dem sie rekrutiert werden – schlichtweg deshalb, weil sie die Frage verstehen (Fullerton & McCullough, 2022). Panels verwenden auch einen Test-Retest-Mechanismus, bei dem gleiche Fragen mit zeitlich stabilen Antworterwartungen über mehrere Fragebögen hinweggestreut sind. Wenn die Antworten der einzelnen Teilnehmenden auf diese Fragen nicht genau oder akzeptabel nahe übereinstimmen, wird der entsprechende Befragte aus dem Datensatz entfernt (Fullerton et al., 2009). Auch Google ReCAPTCHA können zu Beginn eines Online-Fragebogens eingesetzt werden; diese für Menschen einfach zu lösenden kleinen Aufgaben verwenden «eine fortschrittliche Risikoanalyse-Engine und adaptive Herausforderungen, um bösartige Software von missbräuchlichen Aktivitäten auf Ihrer Website abzuhalten» (Google, 2024).
Item Response Theory
Ein elaboriertes Verfahren zur Aufmerksamkeitserkennung post hoc, also nach bereits erfolgter Datenerhebung, stellen auch RaschPersonen-Fit-Indices dar. Sie bieten einen methodisch fortschrittlichen Ansatz zur Erkennung abweichender Antworten und identifizieren atypische Antwortmuster auf Personenebene, die zum Beispiel als Folge von Betrug oder fehlender Aufmerksamkeit auftreten können (Beck et al., 2019; Li & Olejnik, 1997). Dieses Verfahren ist allerdings nur anwendbar in Skalen, die nach der Item Response Theory (IRT) erstellt wurden (van den Wittenboer et al., 1997) und die eine ausreichende Länge und eine volle Range von Itemschwierigkeiten aufweisen. Für die Marktforschungspraxis sind diese Voraussetzungen im Unterschied zu psychologischen Testverfahren oder Kompetenztests oft nicht gegeben.
Guttman Errors
Guttman-Fehler, welche die Grundlage vieler nichtparametrischer Person-Fit-Statistiken bilden, eignen sich auch direkt für eine Posthoc-Erkennung abweichender Antwortmuster: Diese treten dann auf, wenn ein Befragter ein schwieriges Item zu einem Thema richtig und danach ein leichtes Item zum selben Thema falsch beantwortet. Voraussetzung dazu sind auch hier Skalen, die Konstrukte mit mehreren Items unterschiedlicher Schwierigkeit (item difficulty) messen. Guttman-Fehler können dann gezählt oder in Relation zur Gesamtzahl der Items gesetzt werden. So können abweichende Antwortmuster in Daten mit dichotomen Antwortskalen genau identifiziert werden (Emons, 2008; Karabatsos, 2003; Meijer, 1994; Meijer, Egberink, Emons, & Sijtsma, 2008). Beck et al. (2019) zeigen auch weitere Person-Fit-Methoden wie U3 personfit statistic, HT coefficient und standardized log likelihood auf.
Fazit
Eine proaktive Behandlung des Themas «Aufmerksamkeit in Umfragen» kann mit zahl- reichen Methoden umgesetzt werden, womit in der Regel die Datenqualität gesteigert werden kann. Es gibt aber keine eigentlichen Standardmethoden oder klare Empfehlungen. Viel wichtiger ist es, die Methoden den Erfordernissen der einzelnen Befragung und der Zielgruppe anzupassen und – gerade wenn Meinungsforschung für Auftraggebende durchgeführt wird – die Methodenwahl transparent zu begründen und zu dokumentieren. Umfrageverzerrungen werden somit vermindert und die Validität von Studien wird erhöht. Eher seltener führt das Exkludieren von nicht aufmerksamen Teilnehmenden jedoch zu einer thematisch relevanten Verzerrung der Stichprobe – dieses Risiko muss von Fall zu Fall geprüft werden. Aufmerksamkeitsprüfungen haben auch sekundäre Effekte und können aus verschiedenen Gründen die Beteiligung der Befragten erhöhen:
Sie können die Umfragen für Teilnehmende interessanter machen.
Rote Heringe oder Instructional Manipulation Checks unterbrechen die Monotonie einer Umfrage.
Sie halten die Aufmerksamkeit der Befragten aufrecht.
Aufmerksamkeitsprüfungen machen zwar den Fragebogen etwas länger, erhöhen jedoch die Wahrscheinlichkeit, dass die Befragten jede Frage vollständig lesen und verstehen.
Einzelne Teilnehmende ärgern sich über «Fremdkörper» oder «Fallen».
Partizipanten erkennen die Checks und setzen Vertrauen in die Wichtigkeit und Professionalität der Befragung.
Die Datenanalyse kann nach Exklusion betroffener Datensätze zuverlässiger und ressourcenschonender sein.
Ein sehr hoher Anteil an unaufmerksamen Teilnehmenden weist im Pretesting auf einen langen, komplizierten, unverständlichen oder monotonen Fragebogen hin oder darauf, dass die Teilnahmemotivation in der Stichprobe nicht ausreicht – ein Thema, dem allenfalls mit der richtigen Ansprache der Teilnehmenden und mit der Kommunikation des persönlichen immateriellen Profits für die Teilnehmenden begegnet werden könnte. Eine Incentivierung mit Geld kann gefährlich sein und Aufmerksamkeitsprobleme sogar im Sinne einer Jagd auf abgeschlossene Fragebögen verschärfen.
Leiner (2019) empfiehlt generell, als wichtigstes Merkmal von Aufmerksamkeit eine angemessene Ausfülldauer des Fragebogens zu Rate zu ziehen, vor allem, wenn im Fragebogen keine Informationen nachgeschlagen werden müssen oder andere komplexe Fragen gestellt werden, die Unterbrüche generieren.
Möglicherweise können mehrere Methoden und Fragen zur Aufmerksamkeitsprüfung eingesetzt werden, die sich methodologisch ergänzen. Auch die Position von Aufmerksamkeitsfragen innerhalb des Fragebogens sollte bedacht werden. Während die Positionierung am Anfang des Fragebogens auf die Teilnehmenden eher präventive Wirkung auf die weitere Aufmerksamkeit im Fragebogen zeigt und für die Auswertungen ein Signal für eine von Anfang an mangelnde Aufmerksamkeit sein kann (z. B. bei testweise Teilnehmenden, Incentivierungsjägern, Teilnahmen aus Neugier), motivieren zwischendurch gestellte Aufmerksamkeitschecks die Teilnehmenden und «halten sie wach». Gegen Ende der Befragung gestellte Checks dienen meist primär der Identifikation von Teilnehmenden, deren Interesse oder deren Konzentration im Fragebogenverlauf verloren gegangen ist.
Um Teilnehmende nicht zu verärgern oder als Versuchsobjekte zu deklassieren, sollten solche Items jedoch insgesamt vor allem bei fragilen Zielgruppen und allenfalls bei Personen, die nur einmal teilnehmen (z. B. Kunden, Messebesucher etc.), zurückhaltend oder sogar nur in Pretests eingesetzt werden, um eine Kenngrösse für eine allfällige Aufmerksamkeitsproblematik zu erhalten und diese für Konfidenzintervalle der Ergebnisse der Hauptbefragung im Hinterkopf zu behalten.
Raffael Meier ist Mitgründer/CTO von onlineumfragen.com und Pionier der deutschsprachigen Online-umfragetechnologie. Er befasst sich mit gesellschaftlichen, technischen und methodologischen Aspekten von Daten.
Kathrin Staub ist Mitgründerin von onlineumfragen.com und Principal Consultant. Spezialisiert auf die Beratung namhafter nationaler und internationaler Unternehmen in den Bereichen Methodik und Fragebogenkonstruktion.
Nina Gwerder ist ehemalige Lead Consultant bei onlineumfragen.com mit Schwerpunkten in den Themen Statistik, Datenqualität und effektive Auswertung von Onlineumfragen.
[1] Alvarez, R. M., & Li, Y. (2022). Survey Attention and Self-Reported Political Behavior, Public Opinion Quarterly, Volume 86, Issue 4, Winter 2022, Pages 793–811, https://doi.org/10.1093/poq/nfac048 [2] Anduiza, Eva, & Carol Galais (2016). Answering Without Reading: IMCs and Strong Satisficing in Online Surveys. International Journal of Public Opinion Research. doi:10.1093/ijpor/edw007. [3] Aust, F., Diedenhofen, B., Ullrich, S. & Musch, J. (2013). Seriousness checks are useful to improve data validity in online research. Behavioral Research Methods, 45, S. 527-535. [4] Barge, S. & Gehlbach, H. (2012). Using the theory of satisficing to evaluate the quality of survey data. Research in Higher Education, 53(2), 182–200. doi:10 . 1007 / s11162-011-9251-2 [5] Baron-Epel, O., Kaplan, G., Weinstein, R., & Green, M. S. (2010). Extreme and acquiescence bias in a biethnic population. European Journal of Public Health. 20 (5): 543–548. doi:10.1093/eurpub/ckq052. [6] Bauer, E., & Johnson, T. (2000). Editing Data: What Difference Do Consistency Checks Make? American Journal of Epidemology, 151(9), S. 921-926. [7] Bauermeister, J. A., Pingel, E., Zimmerman, M., Couper, M., Carballo-Dieguez, A., & Strecher, V. J. (2012). Data quality in HIV/AIDS webbased surveys: Handling invalid and suspicious data. Field Methods, 24(3), 272– 291. doi:10.1177/1525822X12443097 [8] Beach, D. A. (1989). Identifying the random responder. Journal of Psychology: Interdisciplinary and Applied, 123(1), 101-103. [9] Beck, M. F., Albano, A. D., & Smith, W. M. (2019). Person-Fit as an Index of Inattentive Responding: A Comparison of Methods Using Polytomous Survey Data. Applied psychological measurement, 43(5), 374–387. https://doi.org/10.1177/0146621618798666 [10] Berinsky, A.J., Margolis, M.F., & Sances, M.W. (2014), Separating the Shirkers from the Workers? Making Sure Respondents Pay Attention on Self-Administered Surveys. American Journal of Political Science, 58: 739-753. https://doi.org/10.1111/ajps.12081 [11] Berry, D. T. R., Wetter, M. W., Baer, R. A., Larsen, L., Clark, C., & Monroe, K. (1992). MMPI2 random responding indices: Validation using a self-report methodology. Psychological Assessment, 4(3), 340-345. doi:10.1037/1040-3590.4.3.340 [12] Bishop, G. F., Oldendick, R. W., Tuchfarber, A. J., & Bennett, S. E. (1980). Pseudoopinions on public affairs. Public Opinion Quarterly, 44(2), 198–209. [13] Bishop, G. F., Tuchfarber, A. J., & Oldendick, R. W. (1986). Opinions on Fictitious Issues: The Pressure to Answer Survey Questions. The Public Opinion Quarterly, 50(2), 240–250. http://www.jstor.org/stable/2748887 [14] Breitsohl, H. & Steidelmüller, C. (2018). The impact of insufficient effort responding detection methods on substantive responses: Results from an experiment testing parameter invariance. Applied Psychology, 67(2), 284–308. doi:10.1111/apps.12121 [15] Buchanan, T., Heffernan, T. M., Parrott, A. C., Ling, J., Rodgers, J., & Scholey, A. B. (2010). A short self-report measure of problems with executive function suitable for administration via the internet. Behavior Research Methods, 42, S. 709-714. [16] Burns, G. N., & Christiansen, N. D. (2011). Methods of Measuring Faking Behavior, Human Performance, 24:4, 358-372, DOI: 10.1080/08959285.2011.597473 [17] Curran, P. G. (2016). Methods for the detection of carelessly invalid responses in survey data. Journal of Experimental Social Psychology, 66, 4–19. [18] Delgado, K, Tristan, E., Kung, M (Mei-Chuan) & O’Connell, M. (2011). Mean score and validity differences among bogus item endorsement groups. [19] DeSimone, J. A., Harms, P. D., & DeSimone, A. J. (2015). Best practice recommendations for data screening. Journal of Organizational Behavior, 36(2), 171–181. doi:10.1002/job.1962 [20] Dupuis, M., Meier, E., & Cuneo, F. (2018). Detecting computergenerated random responding in questionnairebased data: A comparison of seven indices. Behavior Research Methods, 51(5), 2228–2237. https://doi.org/10.3758/s13428-018-1103-y [21] EMNID (1981): Die Popularität von Bundesministern – eine methodenkritische Befragung. In:EMNID-Informationen 8: 14-16 [22] Emons W. H. M. (2008). Nonparametric personfit analysis of polytomous item scores. Applied Psychological Measurement, 32, 224-247 [23] Farrell, A., Danish, S., & Howard, C. (1991) Evaluation of data screening methods in surveys of adolescents’ drug use. Psychol Assess, 1991(3), S. 295-298. [24] Franzén, M. (2011). Nonattitudes / pseudoopinions: Definitional problems, critical variables, cognitive components and solutions. (C/D Extended Essay No. 14). Retrieved from http://www.diva- portal.org/smash/get/ diva2:1032161/FULLTEXT01.pdf [25] Fullerton, S., & McCullough, T. (2023). Using quality control checks to overcome pitfalls in the collection of primary data via online platforms. Journal of Marketing Analytics, 11(4), 602–612. doi:10.1057/s41270-023-00249-z [26] Fullerton, S., D. Taylor, and J. Watson. 2009. Webbased instruction and online delivery of classes: Where are we now? American Journal of Business Education 2 (1): 91–100. [27] Gill, S. (1947). How do you stand on sin? Tide, 74(March), 72 [28] Goffin, R. D., & Christinasen, N. D. (2003). Correcting personality tests for faking: A review of popular personality tests and an initial survey of researchers. International Journal of Selection and Assessment, 11: 340–344. [29] Goldsmith, R. E. (1989). Reducing spurious response in a field survey. The Journal of Social Psychology, 129(2), 201–212. doi:10.1080/00224545.1989.9711721 [30] Google (2023). reCAPTCHA protects your website from fraud and abuse without friction https://www.google.com/recaptcha/about/. Accessed 2 June 2024. [31] Greszki, R., Meyer, M., & Schoen, H. (2015). Exploring the Effects of Removing “Too Fast” Responses and Respondents from Web Surveys. Public Opinion Quarterly, 79(2), 471–503. https://doi.org/10.1093/poq/nfu058 [32] Gummer, T., Rossmann, J., & Silber, H. (2021). Using Instructed Response Items as Attention Checks in Web Surveys: Properties and Implementation. Social Methods & Research, 50(1), S. 238-264. [33] Haghighat, R. (2007). The Development of the Brief Social Desirability Scale (BSDS). Europe’s Journal of Psychology, 3(4). https://doi.org/10.5964/ejop.v3i4.417 [34] Hargittai, E. (2009). An update on survey measures of weboriented digital literacy. Social Science Computer Review, 27(1), 130–137. doi:10 . 1177 / 0894439308318213 [35] Hauser, D. & Schwarz, N. (2015). It’s a Trap! Instructional Manipulation Checks Prompt Systematic Thinking on ‘Tricky’ Tasks. Sage Open, 5(2), S. 1-6. [36] Ihme, J. M., Lemke, F., Lieder, K., Martin, F., Müller, J. C., & Schmidt, S. (2009). Comparison of ability tests administered online and in the laboratory. Behavior Research Methods, 41, S. 1183-1189. [37] Jones, M., House, L., & Gao, Z. (2015). Respondent Screeingin and Revealed Preference Axioms: Testing Quarantining Methods for Enhanced Data Quality in Web Panel Surveys. Public Opinion Quarterly, 79(3), S. 687-709. [38] Johnson, J. A. (2005). Ascertaining the validity of individual protocols from webbased personality inventories. Journal of Research in Personality, 39(1), 103–129. doi:10.1016/j.jrp.2004.09.009 [39] Kane, J., Velez, Y., Barbas, J. (2023). Analyze the attentive and bypass bias: Mock vignette checks in survey experiments. Political Science Research and Methods, 11(2), S.293-310. [40] Karabatsos G. (2003). Comparing the aberrant response detection performance of thirty-six personfit statistics. Applied Measurement in Education, 16, 277-298 [41] Kemper, C. J., Beierlein, C., Bensch, D., Kovaleva, A., & Rammstedt, B. (2012). Eine Kurzskala zur Erfassung des Gamma-Faktors sozial erwünschten Antwortverhaltens: Die Kurzskala Soziale Erwünschtheit-Gamma (KSE-G) (GESIS Working Papers 2012|25). Köln: GESIS. [42] Krosnick, J. A. (1991). Response strategies for coping with the cognitive demands of attitude measures in surveys. Applied Cognitive Psychology, 5(3), 213–236. doi:10. 1002/acp.2350050305 [43] Krosnick, J. A. (1999). Survey research. Annual Review of Psychology, 50(1), 537–567. doi:10 . 1146 / annurev. psych.50.1.537 [44] Krosnick, J. A., Narayan, S. S., & Smith, W. R. (1996). Satisficing in surveys: Initial evidence. In M. T. Braverman, & J. K. Slater (Eds.), Advances in Survey Research (pp. 29-44). San Fransisco: Jossey-Bass. [45] Kung, F.Y.H., Kwok, N. and Brown, D.J. (2018), Are Attention Check Questions a Threat to Scale Validity? Applied Psychology, 67: 264-283. https://doi.org/10.1111/apps.12108 [46] Li, M. F., & Olejnik, S. (1997). The power of rasch personfit statistics in detecting unusual response patterns. Applied Psychological Measurement, 21, 215–231. [47] Meade, A. W. & Craig, S. B. (2012). Identifying careless responses in survey data. Psychological Methods, 17(3), 437–455. doi:10.1037/a0028085 [48] Meier, R., & Gwerder, N. (2023). Dirty on the go? Data quality in online surveys between PC and mobile devices. In Swiss Insights (Hrsg.), Swiss Insights Annual Report 2023. [49] Meier, R., & Gwerder, N. (2022). Dirty Data in Online Surveys. How to improve data quality before and after the field phase. In Swiss Insights (Hrsg.), Swiss Insights Annual Report 2022 (S. 51-62). [50] Meijer R. R. (1994). The number of Guttman errors as a simple and powerful personfit statistic. Applied Psychological Measurement, 18, 311-314 [51] Meijer R. R., Egberink I. J. L., Emons W. H. M., Sijtsma K. (2008). Detection and validation of unscalable item score patterns using item response theory: An illustration with Harter’s Self-Perception Profile for children. Journal of Personality Assessment, 90, 227-238 [52] Miller, J. & Baker-Prewitt, J. (2009). Beyond ‘Trapping’ the Undesirable Panelist: The Use of Red Herrings to Reduce Satisficing. Präsentiert an der CASRO Panel Quality Conference, 2. Februar 2009. New Orleans, USA. [53] Nichols, D. S., Greene, R. L., & Schmolck, P. (1989). Criteria for assessing inconsistent patterns of item endorsement on the MMPI: Rationale, development, and empirical trials. Journal of Clinical Psychology, 45(2), 239-250. doi:10.1002/1097-4679(198903)45:2<239::AIDJCLP2270450210>3.0.CO;2-1 [54] Nießen, D., Partsch, M. V., Kemper, C. J., & Rammstedt, B. (2019). Social Desirability-Gamma Short Scale (KSE-G). Zusammenstellung sozialwissenschaftlicher Items und Skalen (ZIS). https://doi.org/10.6102/zis271_exz [55] Oppenheimer, D., Meyvis, T., & Davidenko, N. (2009). Instructional Manipulation Checks: Detecting Satisficing to Increase Statistical Power. Journal of Experimental Social Psychology, 45, S. 867-72. [56] Paulhus, D. L. (1984). Two-component models of socially desirable responding. Journal of Personality and Social Psychology, 46(3), 598-609. [57] Podsakoff, P.M., MacKenzie, S.B., Moorman, R.H., & Fetter, R. (1990). Transformational leader behaviors and their effects on followers’ trust in leader, satisfaction, and organizational citizenship behaviors. Leadership Quarterly, 1(2), 107–142. http://doi.org/10.1016/1048-9843(90)90009-7 [58] Porst, R. (2014). Fragebogen – Ein Arbeitsbuch. 4. Auflage, Wiesbaden: Springer Fachmedien. [59] Reips, U.-D. (2002). Standards for internetbased experimenting. Experimental Psychology, 49, S. 243-256. [60] Reips, U.-D. (2008). How Internetmediated research changes science (S. 268–294). Cambridge, MA: Cambridge University Press. [61] Reips, U.-D. (2009). Internet experiments: Methods, guidelines, metadata. Human Vision and Electronic Imaging XIV, Proceedings of SPIE, 7240, 724008. [62] Reuband, Karl-Heinz (2000): „Pseudo-Opinions“ in Bevölkerungsumfragen. Wie die Bürger fiktive Politiker beurteilen. In: ZA-Informationen 46: 26-38 [63] Rogers, R., Sewell, K. W., Martin, M. A., & Vitacco, M. J. (2003). Detection of feigned mental disorders: A meta-analysis of the MMPI-2 and malingering. Assessment, 10(2), 160-177. doi:10.1177/1073191103010002007 [64] Schell, C., Godinho, A., & Cunningham, J. (2022). Using a consistency check during data collection to identify invalid responding in an online cannabis screening survey. BMC Medical Research methodology, 22(67). [65] Schuman, H. & Presser, S. (1980). Public opinion and public ignorance: The fine line between attitudes and nonattitudes. American Journal of Sociology, 85(5), 1214– 1225. [66] Schuman, H., & Presser, S. (1981). Questions and Answers in Attitude Surveys. New York: Academic Press. [67] Stevens, H. (2017, November 19). Catching a red herring. Chicago Tribune. https://www.chicagotribune.com/lifestyles/ct-tribu-words-work-herring-20110202-story.html [68] Suárez-Alvarez, J., Pedrosa, I., Lozano, L. M., García-Cueto, E., Cuesta, M., & Muñiz, J. (2018). Using reversed items in Likert scales: A questionable practice. Psicothema, 30(2), 149–158. [69] Ross, R.S. (2008). Popularization of ‘red herring’ by English political agitator William Cobbett. In: Comments on Etymology 38:1-2, 2008, S. 62–69. [70] Tett, R. P., & Christiansen, N. D. (2007). Personality tests at the crossroads: A reply to Morgeson, Campion, Dipboye, Hollenbeck, Murphy, and Schmitt. Personnel Psychology, 60: 267–293. [71] Tourangeau, R., Rips, L. J., & Rasinski, K. (Eds.). (2000). The psychology of survey response. Cambridge University Press. https://doi.org/10.1017/CBO9780511819322 [72] Weick, K. E. (1995). Sensemaking in organizations. Thousand Oaks [u.a.] : Sage. [73] van den Wittenboer, G., Hox, J., & de Leeuw, E. (1997). Aberrant Response Patterns in Elderly Respondents: Latent Class Analysis of Respondent Scalability (pp. 155–162). Münster, Germany: Waxman.