Customer lifetime value (CLV) is a key metric for every customer-centric marketer. Predicting the future value of a customer more accurately and reliably, would help to increase the marketing efficiency. Thus, its importance is widely acknowledged in industry and academia. But surveys show that CLV measurement is often a challenge in business practice. Retailers or other non-contractual businesses often fail to accurately predict customer purchase behavior. In particular, in the medium and long term.
Two reasons are key for this: (1) In non-contractual settings, customers do not formally announce when they will stop purchasing from a business. This contrasts contractual business settings such as insurance firms and poses a great challenge for modeling the future purchase behavior of customers. (2) Further, many businesses are subject to seasonal patterns. They experience for example a summer dip as many regular customers are on holidays or they observe significant increases related to special shopping events like Black Friday or Christmas.
The novel approach accounts for all these challenges and provides accurate and reliable estimates of the future value for each individual customer. Recent benchmarks also show that this probability-based approach not only provides better and more reliable prediction accuracy than machine learning approaches but is also faster to compute and does not require specialized computing infrastructure. By providing an accompanying open-source software, it is readily applicable for any business.
The novelty of the proposed approach is to include previously neglected, but from a practical point of view crucial, context variables in the statistical modeling. For the first time, it is possible to consider the effects of customer characteristics such as income and place of residence as well as dynamic effects such as shopping events. Although this seems logical and perhaps even overdue from a content point of view, the challenge lay in the statistical complexity that such an undertaking entails.
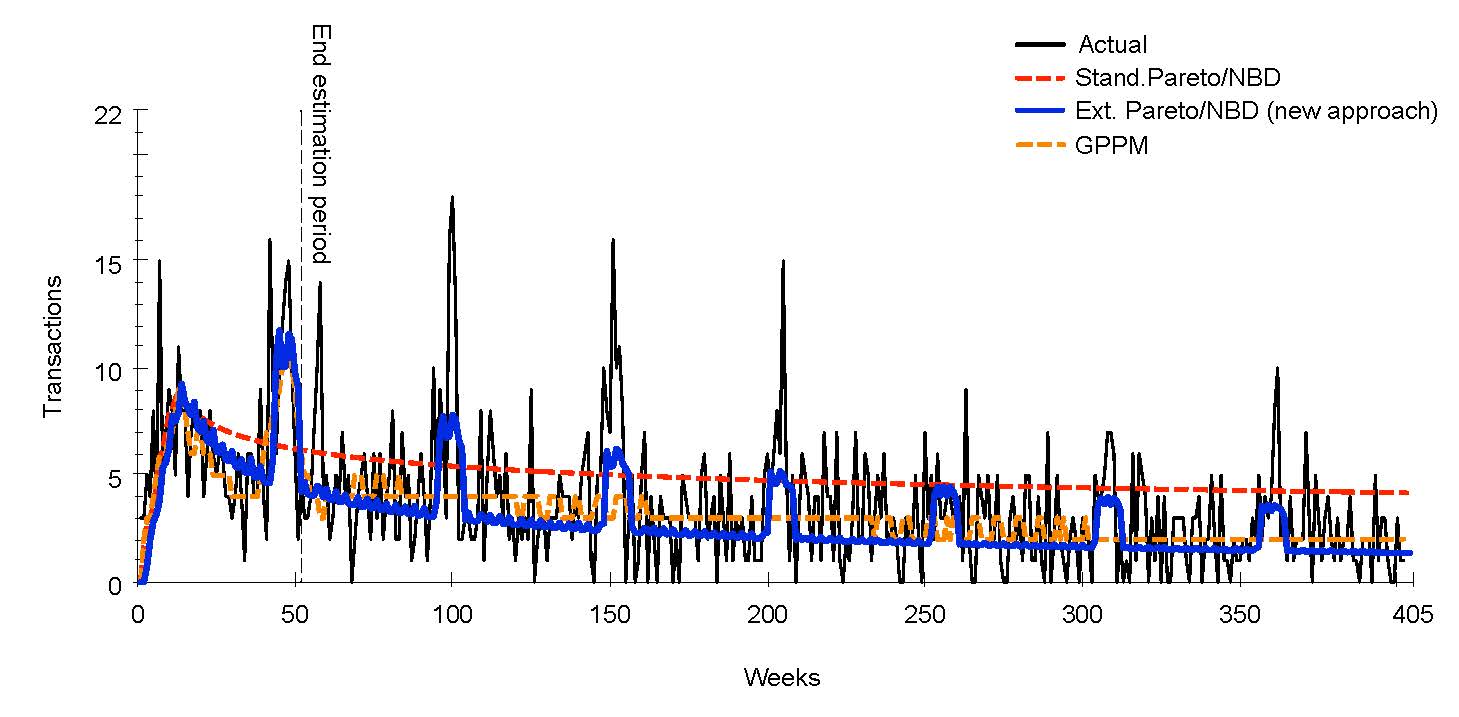
To guarantee reliability of the results across a wide variety of scenarios in corporate practice, this study considered data from three different industries. In addition, several alternative statistical models were calculated as benchmarks, this included widely used „rules of thumb“, established traditional statistical models and latest machine learning approaches. Furthermore, short-, medium-, and long-term forecast periods were considered to account for the widely varying planning horizons in practice. The added value of the proposed novel approach could thus be demonstrated over a broad database. The exemplary performance is shown in Figure 1.
Figure 1: Comparison of the aggregated performance of the extended Pareto/NBD Model with other approaches
How to use this novel approach as a data analyst
To make the application of this novel approach as easy as possible in practice, an open-source software called „CLVTools“ was developed (www.clvtools.com). CLVTools is a software package for the statistical programming environment R. Beyond the latest work presented here, CVLTools also includes implementations of further complementary and alternative modeling techniques to predict CLV. To date, this software has been downloaded more than 30,000 times.
In its simplest form, without considering any contextual factors, the estimation of CLV only requires a minimal amount of data. At its core, three input variables of customers purchase history are required. This data is available for any firm: a customer identifier (Id), the purchase date, and the purchase amount. Exemplary input data is shown in Table 1.
Table 1: Exemplary input data for the probabilistic modelling
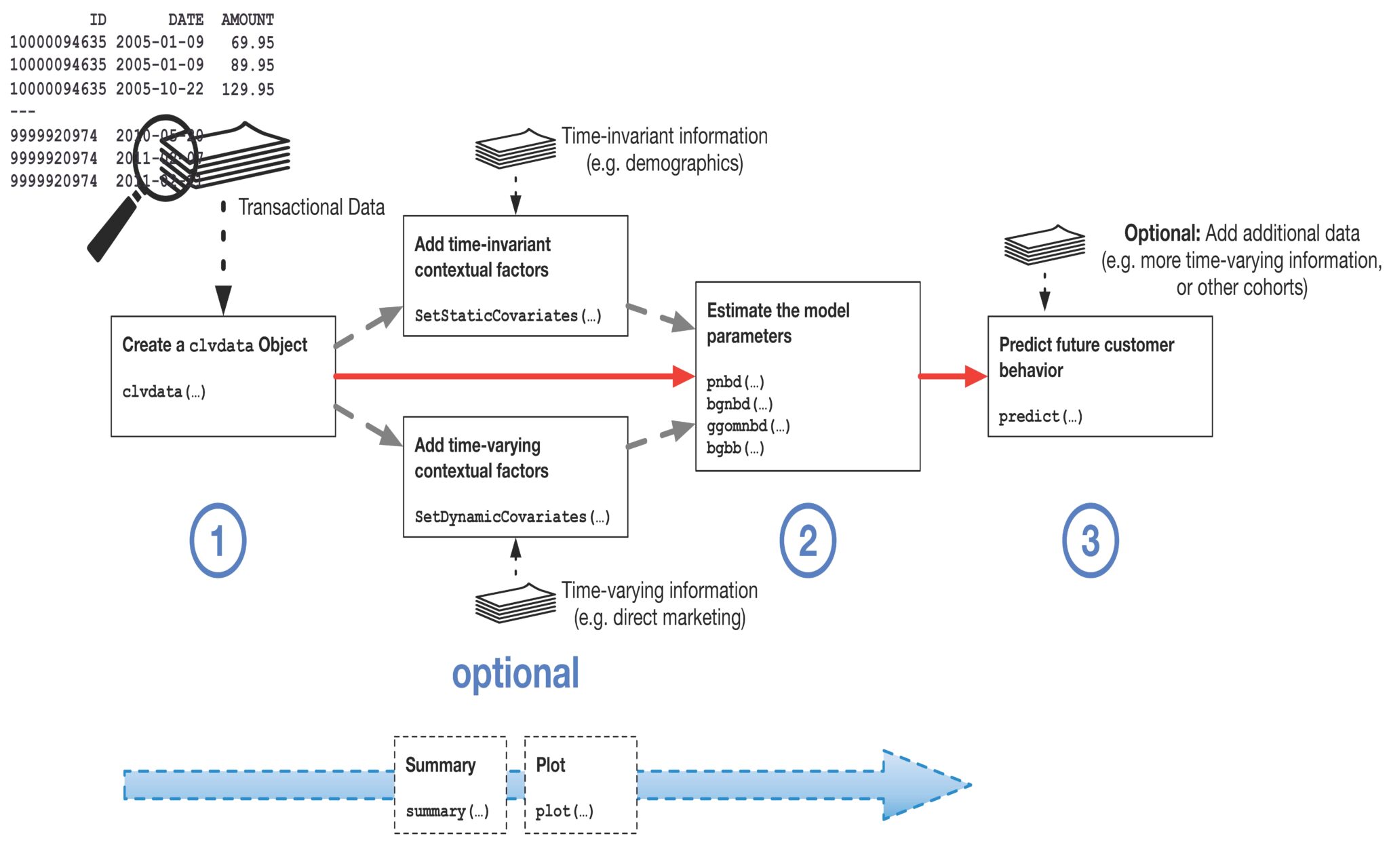
Using the CLVTools package in R only three steps are required to predict customer lifetime value in simplest application case: • Step 1: Import the historical customer purchase data. • Step 2: Estimate the model parameters. • Step 3: Predict the customer purchase behavior. Figure 2 summarizes the workflow and avai-lable options of CLVTools.
Figure 2: Workflow for CLVTools
Multiple options to check and plot the data along this workflow are provided. Moreover, advanced model features and alternative model options are available. See https://www.clvtools.com/articles/CLVTools.html for a detailed walkthrough.
Marketing practice thus has a new, freely available tool at its disposal to better coordinate customer-centric marketing activities. Customer value as a central marketing metric is used in a variety of ways, e.g., to individualize coupons, to determine the most effective marketing channels or to allocate resources for win-back campaigns. An accurate calculation of the customer value based on our proposed approach helps to significantly improve the customer-specific personalization and thus the marketing efficiency.
Research Team
Patrick Bachmann (ETH Zurich) Markus Meierer (University of Geneva) Jeffrey Näf (ETH Zurich) Patrik Schilter (Crealytics GmbH)
Patrick Bachmann
Post Doctoral Researcher ETH Zurich
Markus Meierer
Assistant Professor of Marketing Analytics University of Geneva
Für eine professionelle und aktive Marktbearbeitung im Privatkundenbereich sind auch Energieversorgungsunternehmen (EVU) auf Geo- und Konsumdaten angewiesen. In aller Regel verfügen Energieversorger über entsprechende Informationen aber höchstens für ihr eigenes Versorgungsgebiet, bzw. für einen Teil ihrer privaten Stromkunden. Aus diesem Grund haben das Schweizer Marktforschungsinstitut LINK und die Data-Science-Spezialisten von Novalytica gemeinsam den EVU Marktatlas B2C konzipiert und 2022 erstmals umgesetzt. Das Studienkonzept basiert auf Expertengesprächen und Fachinputs aus der Branche, berücksichtigt Befragungs- und öffentlich zugängliche Sekundärdaten und bietet auf dieser Grundlage mikrogeografische Analysemöglichkeiten.
Methodischer Ansatz
Die Studie basiert auf der Hochrechnung einer umfangreichen Primärdatenerhebung auf die gesamte Schweiz. LINK führte im vierten Quartal 2021 eine Befragung von mehr als 10’000 Privatkunden im Alter zwischen 18 und 79 Jahren in der Schweiz durch, die auf Basis von Region, Alter und Geschlecht quotiert wurde und deren Stichprobe damit an der Bevölkerungsverteilung gemäss Bundesamt für Statistik ausgerichtet ist. Das Beantworten des Fragebogens dauerte ca. 10 Minuten und beinhaltete diverse Themen rund um die Einstellung gegenüber Energiethemen, der Marken- und Kundenwahrnehmung von Energieversorgern und dem Potenzial von Energieprodukten. Novalytica kombinierte alsdann eine Vielzahl öffentlich verfügbarer Geodaten.
Neben Daten des Bundesamtes für Statistik, des Gebäuderegisters, des Handelsregisters oder kantonaler Geoportale umfasste diese Recherche auch online verfügbare Quellen wie Immobilieninserate. Neben Datenpunkten zur Wohnsituation (u. a. Gebäudetyp, Baujahr, Renovationen, Preis-/Mietniveau, Grösse), welche bei Fragen rund um Energie zentral sind und gleichzeitig einiges über die Haushalte preisgeben, sind auch Datenpunkte zur Soziodemographie (u. a. Alter, Haushaltsgrösse, Anteil Nicht-Schweizer) auf Ebene Hektar vorhanden. Die aus diesen Quellen kombinierten Daten werden aufbereitet und können so jeder Strasse und Adresse aus den Befragungsdaten zugeordnet werden.
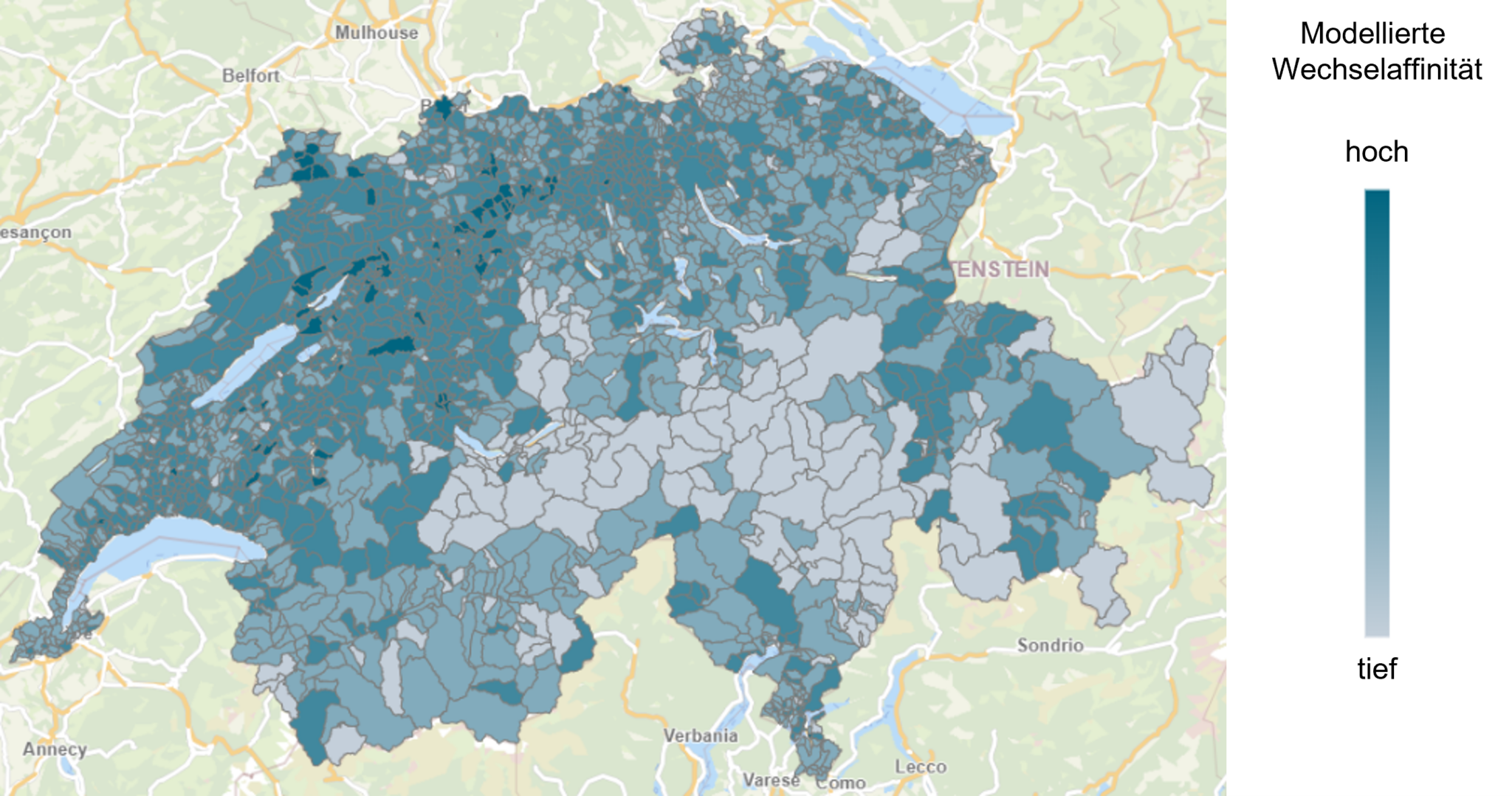
Die Ergebnisse der Privatkundenbefragung wurden anschliessend mit den Geodaten verbunden. Mittels der Machine-Learning-basierten Modellierung Gradient Boosting werden die Survey-Antworten auf Gemeinde- und Hektarebene hochgerechnet. Das Modell ermittelt Zusammenhänge zwischen den einzelnen Variablen und erstellt basierend darauf eine Schätzung. Korreliert beispielsweise die durchschnittliche Haushaltsgrösse oder der Anteil Einfamilienhäuser mit der Wechselwahrscheinlichkeit, wird dies vom Modell berücksichtigt. Zur Illustration des Vorgehens zeigt Abbildung 1 beispielhaft das Resultat eines Modells für die Schätzung der Wechselbereitschaft privater Stromkunden aggregiert auf Gemeindeebene.
Abbildung 1: Modellierte Wechselaffinität auf Ebene Gemeinde
Qualitätsaspekte bei öffentlich zugänglichen Daten und der Modellierung
Ein wesentlicher Teil der genutzten Sekundärdaten stammt von offiziellen Quellen wie dem BfS, was eine hohe Datenqualität sicherstellt. Allerdings haben diese oft einen Time Lag: So sind verschiedene Datenquellen dort derzeit nur Stand Ende 2019 verfügbar. Angesichts der sich in Immobilienbestand und Bevölkerung vergleichsweise langsam entfaltenden Veränderungen über die Zeit hinweg dürfte dies die Aussagen aber nicht wesentlich beeinflussen. Zudem wurden aktuelle Online-Quellen genutzt und im Hintergrund automatisch aktualisiert, um gleichzeitig maximale Abdeckung und bestmögliche Datenaktualität zu erreichen.
Befragungs- und öffentliche Datenquellen wurden, wenn möglich, über die genaue Hausnummer verbunden, ansonsten mit Durchschnittswerten für die Strasse. Nur Observationen mit Strassenangabe flossen in die Modellierung ein. Nach dem gängigen Vorgehen bei der Entwicklung von Machine-Learning-Modellen wurden sogenannte Test-Stichproben gebildet, welche zur Qualitätsprüfung eines Modells verwendet werden und verhindern, dass ein Modell nur innerhalb der Stichprobe gute Resultate liefert. Dieser Prozess wurde aus Qualitätsgründen mehrmals durchlaufen.
Analysemöglichkeiten im EVU Marktatlas 2022
Die Ergebnisse werden in einem selbst zu bedienenden Datenportal zur Verfügung gestellt, das online im Browser, d.h. ohne eine lokale Installation, abrufbar ist. In das Datenportal fliessen sowohl die deskriptiven Befragungsergebnisse, als auch die modellierten und auf geografische Einheiten extrapolierten Indikatoren mit ein.
Bei der mikrogeografischen Analyse im Rahmen der Studie ist es möglich, Hochrechnungen bis auf Hektar, Gemeinde oder Versorgungsgebiet zu fahren. Die entsprechenden Analysen zu Wechselbereitschaft, Marktpotenzialen für Energieprodukte oder Markenbekanntheit zeigen, dass es zwar klare regionale Unterschiede gibt, diese sich in der Regel aber nicht homogen über Versorgungsgebiete oder Gemeinden verteilen. Bei der Bewerbung gewisser Leistungen wie beispielsweise Wärmepumpen oder Photovoltaik macht es demnach Sinn, eine differenzierte Marketing- und Vertriebsstrategie umzusetzen, um sich auf besonders erfolgversprechende regionale Zielgruppen zu konzentrieren – dies verspricht mehr Effektivität und Effizienz.
Abbildung 2: Lokale Potenziale für Premium-Stromprodukte in der Stadt Bern
Abbildung 2 zeigt eine Beispielauswertung in Form einer regionalen Hektaranalyse für die Stadt Bern hinsichtlich des Marktpotenzials für Premium-Stromprodukte. Eine differenzierte Marketingstrategie, auch im Hinblick auf geografische Merkmale, kann so nachhaltig geplant und begründbar verfolgt werden. Die geografische Extrapolation von Befragungsdaten mittels Datenanreicherung von grossen, öffentlich zugänglichen Sekundärdatenquellen und auf Machine Learning basierten Korrelationsmodellen ist eine spannende Weiterentwicklung klassischer Marktforschungs-Studiendesigns. Durch die Kombination von Meinungs- und Einstellungsdaten mit Strukturdaten profitieren schlussendlich beide Datenquellen, da sie sich erkenntnistheoretisch gegenseitig anreichern.
Die Einsatzmöglichkeiten dieses Ansatzes sind in dieser Form auf Branchen und Business Cases beschränkt, für welche eine geografische Analyseperspektive relevant ist. Im besten Fall kann er aber auch einen Ausblick darstellen, wie die klassische Marktforschung im Zeitalter immer grösserer, automatisierter Datenströme eine relevante Rolle spielen kann.
Stefan Reiser
Mitglied der Geschäftsleitung und Managing Director für Marketingforschung, LINK
Derzeit steigen die Preise in fast allen Produktkategorien – Experten sprechen schon von einer Inflation 2.0. Zusätzlich befeuern globale Unruhen sowie anhaltende Lieferengpässe und Warenmängel die Preissteigerungen. Die Inflation sowie die damit verbundenen steigenden Preise sorgen für finanzielle Unsicherheit bei den Konsumenten. Nur 34 Prozent der Verbraucher weltweit glauben, dass sich ihre wirtschaftliche Situation in zwölf Monaten verbessern wird – 2019 waren es noch 41 Prozent.
Gerade in diesen unsicheren Zeiten müssen Business Leader Risiken managen und neue Wachstumsmöglichkeiten schnell und zielgerichtet identifizieren. Hierbei ist Agilität heutzutage zu Recht ein massgeblicher Erfolgsfaktor. Mit einer agilen Arbeitsweise sind Unternehmen in der Lage, flexibel auf neue Herausforderungen zu reagieren, schneller Entscheidungen zu treffen und so der Konkurrenz einen Schritt voraus zu sein.
Ondrej Szabo, Regional Director gfknewron, beschreibt im folgenden Artikel, wie Unternehmen mit der Datenplattform gfknewron agil und flexibel entscheiden können.
Daten und Insights müssen immer zeitnah validiert werden, um auf volatile Marktbedingungen aber auch auf sich ändernde Konsumentenverhalten und Ansprüche zu reagieren oder ihnen vorzugreifen. Markt- und Konsumentendaten bieten die ideale Basis für unternehmerische Entscheidungen und um nachhaltiges Wachstum zu schaffen. Das gelingt jedoch nur, wenn einige kritische Faktoren beachtet werden. Einerseits müssen Daten und Insights in real time bereitgestellt werden, ein Verzug um Tage oder gar Wochen kann zu einem deutlichen Nachteil führen. Des Weiteren sind marktspezifische Insights ein Muss – der Schweizer Konsument reagiert und kauft anders als der Österreichische und dieser unterscheidet sich wiederum vom Deutschen. Doch sowohl zeitnahe als auch marktspezifische Insights helfen nur bedingt, wenn sie nicht im Sinne einer Demokratisierung in weiten Teilen des Unternehmens zugänglich gemacht werden.
Um auf neue Trends oder disruptive Marktveränderungen zu reagieren, müssen Unternehmen in kurzer Zeit belastbare Entscheidungen treffen. Flexibilität und Schnelligkeit sind klare Business-Erfolgsfaktoren.
Die «Single Source of Truth» verkürzt Abstimmungs-runden zwischen Unternehmensbereichen
Dies gelingt jedoch selten in siloartig organisierten Unternehmen: Wenn der Head of Product nur die Produktanforderungen kennt, die Geschäftsleitung auf den Unternehmenszahlen sitzt, nur die Sales-Abteilung die Kundennachfrage erfasst und lediglich das Marketing die neuesten Trends verfolgt – wie soll das Unternehmen hier schnell eine Entscheidung herbeiführen? Oft führt das zu nicht endenden, kontroversen Abstimmungsrunden – agil ist das nicht.
Oft fehlt eine von allen anerkannte Datengrundlage, eine «Single Source of Truth». Dies löst schwierige Entscheidungsprozesse aus. Anderen Abteilungen Zugriff auf die spezifischen Tools und Daten zu verschaffen, scheitert an Zugriffsrechten oder unterschiedlich strukturierten Dashboards, die mehr verwirren als informieren. Eine zentrale digitale Datenplattform kann dieses Problem lösen und Unternehmen zu mehr Agilität und Sicherheit verhelfen.
Allen Entscheidungsträgern in einem Unternehmen Zugriff auf alle relevanten Daten und Insights zu geben, die in einer gemeinsamen Plattform liegen, hilft bekannte Probleme im Entscheidungsprozess zu beheben.
Denn oft fehlt in Unternehmen eine gemeinsame Informationsbasis. Mit einer zentralen digitalen Plattform, die unternehmenseigene und externe Daten anschaulich aufbereitet, werden viele Abstimmungen überflüssig.
Zudem liegen oft keine objektiven Daten für die Entscheidungsfindung vor, oder die Datengrundlage ist aufgrund der sich rasch verändernden Marktverhältnisse schon wieder veraltet. Bauchgefühl ist zwar ein wertvoller Indikator bei der Entscheidungsfindung, aber digital aufgearbeitete Daten zu Absatzzahlen, Marktposition im Wettbewerb oder zum aktuellen Einkaufsverhalten der Konsumenten ermöglichen faktenbasierte Entscheidungen anstatt eines Blindfluges.
Demokratisierung von Daten, Tools und Insights
In einem interdisziplinären Projekt möchten wir nun die Ideen des Life Engineerings und den daraus Eine Single Source of Truth und die damit einhergehende Demokratisierung von Daten und Insights stärkt die Resilienz eines Unternehmens ungemein. Damit ändern sich Prozesse und Arbeitsweisen hin zu einem agilen Business – eine Änderung, die notwendig ist, um schneller und flexibler auf Veränderungen reagieren zu können.
DeLonghi Deutschland beispielsweise hat sich bewusst für mehr Flexibilität entschieden: Auf Basis von aktuellen Daten in der digitalen Datenplattform gfknewron bespricht das Management-Team täglich die Lage und das geplante Vorgehen. Alle Teilnehmer sind in Echtzeit über den eigenen Geschäftsbereich informiert. Wie Susanne Harring, Geschäftsführerin von DeLonghi Deutschland GmbH auf dem GfK Insight Summit letztes Jahr sagte: «Nach nur zwei Wochen Übergangszeit war das Meeting eine gesetzte und geschätzte Grösse in den täglichen Abläufen von DeLonghi, die niemand mehr missen wollte.»
Digitalisierung der Geschäftsmodelle, daten-basiertes Arbeiten und agiles Denken sind Grundvoraussetzungen für Erfolg in einem Zeitalter der globalen Unsicherheiten. Wir haben bei GfK die Herausforderungen einer solchen Umstellung in den letzten Jahren selbst gespürt, als wir uns vom klassischen Marktforscher zum digitalen Datenunternehmen gewandelt haben. Aufgrund dieser Erfahrung kennen wir die typischen Herausforderungen und können anderen Unternehmen wichtige Hilfestellungen auf ihrem Weg zu Agilität und datenbasierten Entscheidungen geben.
Der Autor Ondrej Szabo ist Regional Director bei der GfK Schweiz und verantwortet den Vertrieb von softwarebasierten Market Intelligence Lösungen für DACH und Osteuropa. Zuvor hielt er verschiedene Management und Sales Positionen bei der GfK in Europa, Lateinamerika und Asien.
In China wird zunächst ausprobiert, innoviert und entwickelt und später erst reguliert. Diese Vorgehensweise war im vergangenen Jahr auch bei der Regulierung der Tech-Unternehmen zu beobachten. Nachdem die chinesischen Digitalunternehmen in den letzten Jahren recht frei wachsen und sich entfalten konnten, wurden sie dem Staat nach und nach zu mächtig, was zu umfassenden Regulierungen geführt hat.
Besonders betroffen waren Didi Chuxing mit einem daraus resultierenden Delisting von der US-Börse, aber auch Tech-Giganten wie Alibaba, Meituan und Pinduoduo, die hohe Bussgelder bezahlen mussten. Ausserdem griff die Regierung stark in den Bereich E-Commerce ein. So erhielt Chinas Livestreaming-Queen Viya eine Geldstrafe von über 200 Millionen US-Dollar wegen Steuerhinterziehung.
Auf der einen Seite verfolgte die chinesische Regierung das Ziel, mehr Kontrolle zu erlangen und die Macht der immer einflussreicheren privaten Unternehmen einzuschränken. Westliche Medien berichteten vor allem negativ über die Tech-Regulierungen. Dabei übersahen sie, dass damit auch tatsächlich wettbewerbswidrige Praktiken und illegale Informationsveröffentlichungen unterbunden werden sollten.
So waren bis vor Kurzem auf vielen chinesischen Plattformen Links und Bezahlmethoden anderer Anbieter nicht zugelassen. WeChat enthielt beispielsweise keine Links zum Alibaba-Ökosystem und Tmall liess die Bezahlung mit WeChat Pay nicht zu. Ausserdem gab es in den sozialen Medien viele Skandale um den Missbrauch und die illegale Veröffentlichung von Nutzerdaten. Teil der Regulierung waren Richtlinien, die in der Vergangenheit gefehlt hatten.
Gibt es in China einen Datenschutz?
Oft wird im sogenannten Westen angenommen, dass es in China keinen Datenschutz gibt. Die Wahrheit ist aber, dass Daten in China anders geschützt werden als im Westen. In der kollektivistischen chinesischen Gesellschaft ist das Gemeinwohl wichtiger als das Individuum und eine vertrauenswürdige Gesellschaft ist bedeutender als die Privatsphäre des Einzelnen. Das führt dazu, dass sich die chinesische Bevölkerung bisher wenig Gedanken darüber machte, wer ihre Daten sammelt und wozu. Das war eine gute Grundlage für die schnelle Entwicklung der Digitalisierung und vor allem der Künstlichen Intelligenz in China.
In den letzten Jahren konnten die chinesischen Bürger:innen allerdings immer öfter beobachten, wie Unternehmen ihre personenbezogenen Daten sammelten und ausnutzten. Sie reagierten mit zahlreichen Klagen gegen Firmen und Plattformen wegen Datenmissbrauchs. Dies hatte zur Folge, dass der chinesische Staat neue Gesetze zur Erhöhung der Datensicherheit und zum Schutz persönlicher Daten erliess. Seit 2021 gibt es in China beispielsweise ein Zivilgesetzbuch, das unter anderem die Nutzung persönlicher Daten regelt. Auch Gesetze wie das Data Security Law oder das Personal Information Protection Law sind Folgen des gestiegenen Bewusstseins für Datenschutz.
Das führt dazu, dass sich der chinesische Datenschutz zunehmend der DSGVO annähert. Privatsphäre wird allerdings nach wie vor nicht als ein persönliches Recht, sondern als Staatsgut angesehen. Persönliche Daten sind somit vor Privatunternehmen und anderen Staaten geschützt, sie stehen der chinesischen Regierung aber weiterhin zur Verfügung.
Um dem Datenmissbrauch durch private Tech-Unternehmen vorzubeugen, räumte die Regierung im vergangenen Jahr wie bereits erwähnt in Chinas Tech-Szene auf und verschärfte die Regulierung. Das hatte beispielsweise zur Folge, dass die neueste Version der Messaging-App WeChat eine Liste in den Einstellungen enthält, in der die gesammelten Daten (einschliesslich der Kontakte und des Standorts) der Nutzer:innen aufgeführt sind, damit diese einen besseren Überblick darüber erhalten, welche Informationen über sie der Plattform zur Verfügung stehen. Damit will WeChat-Betreiber Tencent die neuen, strengen Anforderungen an den Datenschutz erfüllen.
Im Jahr 2022 werden vermutlich weitere grosse chinesische Technologieunternehmen Umstrukturierungen vornehmen, um Bereiche mit sensiblen Daten auszugliedern und damit den neuen Regeln besser zu entsprechen. Betroffen könnten E-Commerce-Riesen wie Pinduoduo, Ride-Hailing-Apps und möglicherweise sogar Elektroauto-Unternehmen wie NIO oder Xpeng sein. Der regulatorische Druck wird noch zunehmen, da China eine harte Linie in Bezug auf die Datenhoheit und den Einsatz von Algorithmen verfolgt.
Die Regulierung von Algorithmen seit dem 1. März 2022
Seit dem 1. März 2022 ist es Unternehmen in China untersagt, personenbezogene Daten zu verwenden, um Nutzer:innen unterschiedliche Preise für ein Produkt oder eine Dienstleistung anzubieten. In der Vergangenheit kam es beispielsweise immer wieder vor, dass in Ride-Hailing-Apps wie Didi Chuxing die Preise für die Kund:innen aufgrund der vorherigen Fahrten oder des Smartphone-Modells des Nutzers variierten. Diese Diskriminierung soll nun durch eine Regulierung jener Algorithmen verhindert werden, die Inhalte filtern, Suchergebnisse steuern, Preise festlegen oder Videos empfehlen.
Unternehmen müssen in Folge dessen die Nutzer:innen nun darüber benachrichtigen, wenn sie auf ihren Plattformen Algorithmen verwenden, um Empfehlungen abzugeben. Ausserdem sollen die User:innen eine Opt-Out-Möglichkeit erhalten und sich gegen die Nutzung von personenbezogenen Daten in Empfehlungsalgorithmen entscheiden können. Die Option, solche Empfehlungen abzulehnen, wird derzeit insbesondere in den Bereichen Ride-Hailing, E-Commerce, Social Media und Streaming eingesetzt.
Unternehmen sollen in ihren Apps die Nutzer:innen auch nicht zur Sucht oder zu übermässigem Konsum verleiten. So führen Tech-Giganten wie ByteDance (Betreiber von Tiktok und anderen KI-basierten Plattformen) beispielsweise neue Funktionen ein, um mit den Regulierungen konform zu sein. Auf Douyin (chinesische Version von Tiktok) bekommen die User:innen seit Kurzem 5 Sekunden lange Videos zu sehen, wenn sie zu viel Zeit in der App verbracht haben. Diese Kurz-Videos fordern sie auf, sich abzumelden, um nicht süchtig nach den algorithmisch kuratierten Feeds zu werden.
Zum einen sind diese Regulierungen eine Top-Down-Eindämmung der Macht der grossen Tech-Plattformen durch die chinesische Regierung. Die Einschränkung von Empfehlungsalgorithmen ermöglicht es zudem, die Verbreitung von Inhalten in den sozialen Medien besser zu kontrollieren. Zum anderen können die Regulierungen aber auch als Bottom-Up-Aufrufe aus der Bevölkerung angesehen werden, denn die chinesischen Bürger:innen verlangen zunehmend nach mehr Kontrolle über ihre persönlichen Daten und sie wollen wissen, wie die Tech-Unternehmen diese einsetzen und weiterverwenden.
Doch diese neuen Regulierungen von Algorithmen beinhalten auch erhebliche technische Herausforderungen. In der Theorie sind die vorgesehenen Einschränkungen sehr umfassend und weitreichend. Wie kann aber das Verhalten eines Algorithmus, das mit neuem Input ständig dazulernt, genau überwacht werden? Und wie kann sichergestellt werden, dass Algorithmen nach Ansicht der Behörden richtig eingesetzt werden? Es ist noch nicht abzusehen, wie diese Regulierungen in der Praxis genau umgesetzt werden.
China als Vorbild für westliche Länder?
Eine weitere Frage bleibt offen: Facebook, Google und Co. werden in der westlichen Digitallandschaft immer mächtiger und stehen oft im Verdacht, sich wettbewerbswidrig zu verhalten, Desinformation zu betreiben und Daten zu missbrauchen. Inwieweit kann die chinesische Regulierung als Modell und Vorbild für westliche Länder dienen?
Auch die EU versucht seit mehreren Jahren, die Macht und den Einfluss der Tech-Unternehmen einzuschränken. Doch sie stösst damit oft an ihre Grenzen, denn es ist nicht einfach, die richtigen Massnahmen und ein passendes Regelwerk zu finden. Es gibt viele Diskussionen und Entwürfe, die Schwierigkeit liegt aber vor allem in der Verabschiedung der Verordnungen. Oft dauert es mehrere Jahre, bis theoretische Diskussionen zur tatsächlichen Implementierung von handfesten Regulierungen führen. Dazu kommen rechtliche Herausforderungen und die Abwehr durch die Tech-Giganten. China hingegen führt solche Änderungen sehr schnell ein. Die Regulierung von Algorithmen wurde im Herbst 2021 das erste Mal öffentlich diskutiert. Innerhalb weniger Monate arbeiteten die Zuständigen die Regeln aus, die am 1. März 2022 bereits in Kraft getreten sind.
Vielleicht kann in Zukunft genau dieser «China Speed» und die Regulierung von KI und Algorithmen in China als Inspiration und Vorbild für westliche Länder dienen. Wenn solche Richtlinien in jenem grossen Ausmass in China funktionieren, werden sie vielleicht auch für andere Länder adaptierbar sein. Das chinesische Modell wird aufgrund des Misstrauens gegenüber gewissen chinesischen Technologien wahrscheinlich nicht direkt akzeptiert werden. Es ist aber möglich, dass es beispielsweise europäischen Gesetzgebern als Inspiration dient. Denn obwohl das Modell nicht eins zu eins übernommen werden wird, kann die Entwicklung in China auf jeden Fall erste Impulse für westliche Lösungen liefern.
Alexandra Stefanov Sinologin und Gründerin von China Impulse
Die Autorin Alexandra Stefanov hat Sinologie und Transkulturelle Studien in Heidelberg (DE), Tianjin (CN) und Shanghai (CN) studiert. Sie ist Gründerin von China Impulse, Co-Autorin des Buchs «Digitalisierung Made in China – Wie China mit KI und Co. Wirtschaft, Handel und Marketing transformiert», Co-Herausgeberin des Magazins «China im Blickpunkt» und Host des Podcasts «China Impulse – Zukunftstrends aus dem Reich der Mitte». Mit China Impulse macht Alexandra Stefanov Unternehmen fit für die Zukunft, indem sie ihnen die neusten Digitalisierungstrends aus China präsentiert und digitale Best Practices an die Hand gibt. Im Rahmen von Vorträgen, Workshops, Beratungen, Podcast-Interviews und einem monatlichen Tech-Newsflash gibt sie Einblicke in die chinesische Digitalwelt und zeigt auf, was wir in Europa daraus für unsere eigene Digitalisierung lernen können.
Digitale Technologien wie die künstliche Intelligenz (KI) setzen sich zunehmend durch. Es gibt unterschiedliche Ansichten darüber, was KI leisten kann und was nicht. Problematisch ist, dass es keine Anforderungen an die Transparenz der KI gibt, ja nicht einmal klar ist, was genau mit KI gemeint ist.
Das Herzstück der heutigen KI sind die Daten, mit denen sie gefüttert wird. Doch im Gegensatz zu Öl, mit dem sie oft verglichen werden, sind diese Daten lebendig, weil sie auch von uns Menschen produziert werden. Sind die Daten unvollständig, veraltet oder gar falsch, lernt die KI auf falschen Annahmen, was letztlich zu unbefriedigenden Leistungen und Unmut bei den Nutzern führt.
Darüber hinaus können Datensätze bestimmte Verzerrungen, Vorurteile und Voreingenommenheiten enthalten, die zu Diskriminierung führen, insbesondere bei Entscheidungen, die auf personenbezogenen Daten basieren.
Hubert Österle hat die Disziplin des Life Engineering entwickelt, um genau solchen Gefahren oder Problemen entgegenwirken zu können. Er berücksichtigt dabei auch ethische Aspekte der KI-Entwicklung und -Nutzung. Laut Österle H. (Österle H. , 2020) besteht die Aufgabe des Life Engineering darin, Regeln für digitale Systeme zu entwickeln, die auf das menschliche Wohlbefinden ausgerichtet sind. Life Engineering ist eine Weiterentwicklung des Business Engineering, jedoch mit einem anderen Fokus: statt auf dem Unternehmen (Gewinnorientierung) liegt der auf der Gesellschaft (Lebensqualität). Mit dem Fokus auf «Human» wird beim Life Engineering nicht die Gesellschaft als Einheit, sondern der einzelne Mensch als zentraler Punkt der Betrachtung gesehen.
Bessere KI-Chatbots dank dem Turing-Test?
Beeinflusst durch die technologischen und wissenschaftlichen Fortschritte in der KI sowie durch die wachsende Akzeptanz nicht-menschlicher Kommunikationspartner hat in letzter Zeit die Zahl der Unternehmen zugenommen, welche Chatbots oder Conversational Agents (CAs) zur Automatisierung ihrer Kundenkontaktpunkte einsetzen. Man kann eigentlich schon sagen, dass KI-basierte CAs wie Amazons Alexa oder Apples Siri zu einer wichtigen Serviceschnittstelle zwischen Anbietern und Nutzern geworden sind.
Zunächst sieht es so aus, als ob diese Digitalen Assistenten dazu entwickelt werden, ihre Nutzer im Alltag als intelligente persönliche Assistenten zu unterstützen. Die Chatbots simulieren dabei die menschliche Kommunikation und können im Vergleich zu anderen Software-Lösungen menschliche Eigenschaften besser annehmen.
Um zu testen, ob ein Conversational Agent so gut ist wie ein menschlicher Gesprächspartner, können Unternehmen den bereits existierenden Turing-Test anwenden. Dieser 1950 von Alan Turing entwickelte Test beschreibt eine Möglichkeit, die Intelligenz von Maschinen zu testen. Beim Turing-Test unterhält sich ein menschlicher Fragesteller mit zwei bis drei anderen Gesprächspartnern. Die Konversation findet ausschliesslich per Chat statt. Das Interessante an dem Gespräch ist, dass einer der Gesprächspartner eine Maschine ist und die anderen ein oder zwei echte Menschen.
Der Fragesteller weiss nicht, hinter welchem Gesprächspartner sich die Maschine verbirgt. Der Interviewer hat die Aufgabe, mindestens zehn Minuten lang intensiv Fragen zu stellen. Am Ende muss er entscheiden, welcher seiner Gesprächspartner ein Mensch und welcher eine Maschine ist.
Wenn der Fragesteller nicht eindeutig herausfindet, wer eine Maschine ist, hat der Chatbot oder die Maschine den Turing-Test bestanden. Allerdings werden beim Turing Test keinerlei ethische Aspekte berücksichtigt. Es geht nicht darum, ob sich ein Conversational Agent für den User ethisch korrekt verhält, sondern nur, wie nah sein Verhalten dem eines durchschnittlichen menschlichen Gesprächspartners kommt.
Der Ethik-Check für Bots
In einem interdisziplinären Projekt möchten wir nun die Ideen des Life Engineerings und den daraus resultierenden Ideen zur Entwicklung ethischer Systeme mit denen des Turing-Tests kombinieren. Das Ziel ist ein Ethik-Check für Chatbots.
Inspiriert vom Turing-Test, der herausfinden soll, wie menschenähnlich sich eine KI verhält, wollen wir ethisch korrekte Bots identifizieren und denjenigen, die es noch nicht sind, Hinweise zur Optimierung geben. Um ethisch korrekte Bots als solche zu definieren, müssen wir zunächst festlegen, was ethisch korrekt in unserer Sprache und Kultur bedeutet. Und wir müssen berücksichtigen, dass sich diese Werte im Laufe der Zeit ändern können.
Anschliessend müssen wir Verfahren definieren, wie die zuvor entwickelten ethischen Kriterien gemessen werden können. Darauf folgt eine Bewertung, der sich jeder Bot unterziehen kann, um eine Einschätzung des Zustands seiner ethischen Korrektheit einschliesslich eines eventuellen Verbesserungspotenzials zu erhalten. Die Bewertung wird zunächst von Menschen durchgeführt, es ist aber denkbar, dass in Zukunft auch Bots in der Lage sein werden, die Bewertung vornehmen.
Der Ethik-Check für Conversational Agents ist in zweifacher Hinsicht neu. Zum einen gibt es weder in der Forschung noch in der Praxis anerkannte und weit verbreitete Richtlinien für Chatbot-Projekte. Zum anderen gibt es, abgesehen vom Turing-Test, keine Benchmarks oder andere Tests, die Conversational Agents bewerten und gleichzeitig Optimierungsmöglichkeiten aufzeigen. Unser Projekt kombiniert beide Aspekte in einer Anwendung.
Im Gegensatz zum Turing-Test, bei dem ein Mensch mit einer Conversational AI chattet, soll unser Ethik-Check am Ende direkt von einem Chatbot durchgeführt werden. Der Chatbot verfügt dann über die definierten Ethik-regeln, weiss, welche Fragen er stellen muss und kann die Antworten des zu testenden Chatbots mit den von uns definierten Benchmarks abgleichen und bewerten. Das Ergebnis ist ein vollautomatischer Ethik-Check, der zudem transparent ist, da er genau aufzeigt, welche Kriterien in welchem Umfang in den Entscheidungsprozess eingeflossen sind.
Bevor eine Ethikprüfung stattfinden kann, muss definiert werden, was ethisch korrekt bedeutet. Ethik ist nicht universell. Ethik ist etwas, das sich ständig weiterentwickelt und stark von der Kultur geprägt ist.
Wir definieren daher zuerst ethische Standards für eine spezifische Region. Als erste haben wir den deutschsprachigen Raum ausgewählt. Wir nennen diese Region Smart Region, da wir unsere Standards auf der Grundlage der Ideen von Smart Cities entwickeln wollen. Diese beziehen die Bürgerinnen und Bürger typischerweise in den Prozess der Ideenfindung und Entwicklung ein.
Mit Hilfe der verschiedenen Forschungsmethoden Literaturrecherche, Umfragen, Experteninterviews und Fokusgruppen werden wir ethische Standards für Chat- und Voicebots entwickeln und erste Ansätze präsentieren, wie diese gemessen werden können.
Für die Fokusgruppen werden Experten aus verschiedenen Disziplinen ausgewählt. Im Mittelpunkt stehen Psychologie, Datenschutz, Informatik, Digitalisierung, Bildung, Data Science, Marketing, Wirtschaft. Um sich ändernden ethischen Werten gerecht zu werden, integrieren wir einen Mechanismus zur kontinuierlichen Anpassung an die aktuell geltenden Normen.
In weiteren Iterationen können konkrete Methoden oder Fragen entwickelt werden, um herauszufinden, wie ethisch korrekt sich ein Bot verhält. Anbieter, meist Unternehmen, die Bots für ihre Kunden und Mitarbeiter einsetzen, erhalten zudem Anregungen, wie sie ihre Bots ethisch korrekter reagieren lassen können.
An diesem Punkt haben wir wahrscheinlich eine weitere Herausforderung, nämlich dass viele KI-Projekte auf spezifische Anwendungsfälle ausgerichtet sind. Wir müssen es also schaffen, die ethische Korrektheit trotz dieser Einschränkungen zu messen, und möglicherweise Regeln dafür definieren.
In der ersten Phase wird die ethische Prüfung von Menschen durchgeführt. Die Menschen chatten mit dem Bot, stellen die relevanten Fragen, notieren die Antworten und bewerten diese anhand eines zuvor festgelegten Bewertungsrasters. In weiteren Phasen soll das Chatten und die Ethikprüfung von einem Chatbot übernommen werden, sodass langfristig die gesamte Ethikprüfung voll automatisiert werden kann.
Sobald eine KI einen anderen Bot bewerten muss, werden wir auf die Ansätze der Fuzzy-Logik und des Computing With Words (CWW) zurückgreifen. Fuzzy-Systeme können mit unscharfen Daten umgehen und sind daher sehr gut geeignet, wenn es darum geht, die Äusserungen von Menschen oder Bots zu charakterisieren oder ihre ethische Reife zu testen.
Forscher, die Fuzziness anwenden, ordnen Wörter nicht nur in Kategorien ein, sondern berücksichtigen auch ihre Position innerhalb der Kategorie.
Darüber hinaus ist Computing With Words ein auf der Fuzzy-Logik basierendes Rechensystem, in dem die Objekte der Berechnung vor allem Wörter, Sätze und Propositionen aus einer natürlichen Sprache sind, wie wir sie in unseren Chat-Gesprächen verwenden.
Entwicklungsstand des Ethik-Checks
Auf Basis einer ersten Literaturrecherche haben wir erste Design-Richtlinien für ethische Prinzipien definiert. Nun geht es darum, das Feedback unserer definierten Smart Region zu bekommen und dazu wurde unser so genannter Evaluation Bot entwickelt. Dieser Bot stellt alle von uns gefundenen Design-Prinzipien vor und fragt die Nutzer nach ihrer Einschätzung zur ethischen Wichtigkeit der jeweiligen Prinzipien.
Da die Evaluation immer noch läuft, freuen wir uns natürlich über alle User, die sich fünf bis zehn Minuten Zeit nehmen und ihr Feedback unserem Evaluation Bot mitteilen. Der Bot kann hier besucht werden: https://eggheads.ai/chat/2738
Sophie Hundertmark
Doktorandin Institut für Finanzdienstleistungen Zug (IFZ) selbstständige Chatbot-Beraterin Zürich
Die Autorin Sophie Hundertmark gehört zu den ersten Master-Studentinnen in der Schweiz, die zu Chatbots geforscht haben. Seitdem arbeitet sie als selbständige Chatbot Beraterin und ist zudem wissenschaftliche Mitarbeiterin an der Hochschule Luzern. Anfang 2020 hat sie ihren eignen Chatbot Podcast gestartet, unter welchem alle zwei Wochen eine neue Folge herauskommt. Ende 2020 ist ihr erstes Buch erschienen «Digitale Freunde», ein praxisnahes Sachbuch über Chatbots. Seit 2021 ist Sophie Doktorandin an der Universität Fribourg und forscht und publiziert regelmässig zu Conversational Agents und Ethics.
Mittwochmorgen, 10.24 Uhr: Eine neue Anfrage eines langjährigen Kunden trifft im E-Mail-Postfach ein: Er möchte untersuchen, welche Faktoren die Zufriedenheit seiner Kund:innen beeinflussen und ihre Loyalität gegenüber seiner Marke massgeblich prägen. Spannend, denken wir – und möglicherweise gar nicht so einfach zu beantworten, wie man es auf Anhieb erwarten könnte. Ein erstes Gespräch mit unserem Kunden bestätigt diesen Eindruck: Es kristallisiert sich heraus, dass die interessierenden Zusammenhänge komplex sind und anhand einfacher multivariater Analysemethoden (z. B. einer Regressionsanalyse) nur unzureichend modelliert werden können. Zudem wissen wir aus Erfahrung, dass einige der Konstrukte, die unseren Kunden interessieren – z. B. Kundenorientierung oder Corporate Social Responsibility – nicht direkt messbar sind, sondern über mehrere einzelne Fragen erhoben werden sollten. Um die vermuteten Wirkzusammenhänge adäquat abbilden und allenfalls sogar Zusammenhänge entdecken zu können, die so im Vorfeld nicht absehbar sind, bieten wir unserem Kunden ein Forschungsdesign an, das auf einem Strukturgleichungsmodell aufbaut. Doch was sind Strukturgleichungsmodelle genau und wann kommen sie sinnvollerweise zum Einsatz?
Kausale Zusammenhänge ergründen
Der Begriff «Strukturgleichungsmodell» bezeichnet ein statistisches Modell, anhand dessen sich komplexe Zusammenhänge zwischen verschiedenen Grössen (sogenannten Variablen) modellieren lassen. Ein solches Modell bietet sich insbesondere dann an, wenn eines oder mehrere der folgenden Kriterien zutreffen:
Es sollen kausale Wirkzusammenhänge zwischen verschiedenen Variablen untersucht werden. Man möchte also verstehen, wie Variablen inhaltlich zusammenhängen und wie sie sich gegenseitig beeinflussen.
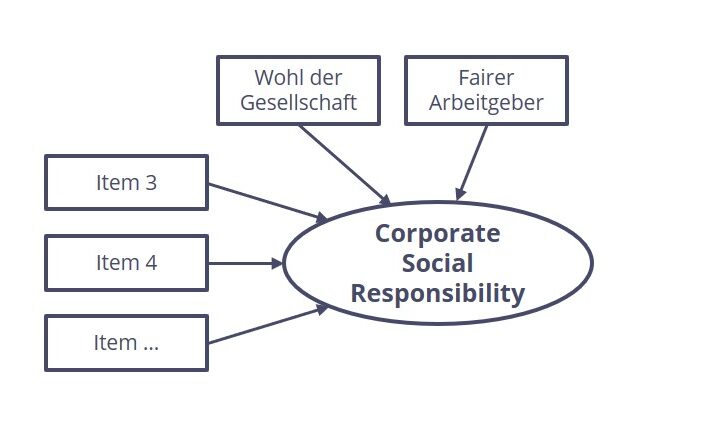
Es werden nicht nur direkt beobachtbare Variablen wie z.B. Kundenzufriedenheit, die über eine Frage erhoben werden können, sondern auch nicht direkt beobachtbare (sogenannte latente) Variablen einbezogen. Letztere werden anhand von mehreren einzelnen Fragen (Items) gemessen. Beispiele für solche latente Konstrukte sind die Corporate Social Responsibility oder auch die Kundenorientierung, die beide mittels mehrerer einzelner Items (auch Treiber genannt) gemessen werden. Bei einem Strukturgleichungsmodell können also sowohl Single Items als auch Multi-Item-Messungen zum Zuge kommen.
Grafik 1: Latentes Konstrukt
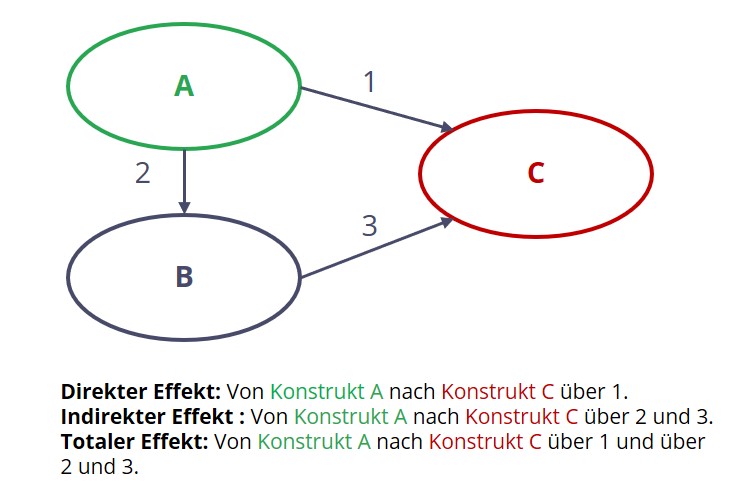
Es besteht die Vermutung, dass einzelne Variablen oder Konstrukte nicht oder nicht nur direkt miteinander in Verbindung stehen, sondern dass auch indirekte Zusammenhänge vorliegen. Dies ist dann der Fall, wenn ein Konstrukt oder ein Treiber über mehrere verschiedene Pfade einen Effekt auf eine andere abhängige Variable hat. Ein Strukturgleichungsmodell fasst die Gesamtheit aller Effekte (direkt und indirekt) zusammen und analysiert sie als totale Wirkung (sogenannte totale Effekte). Dadurch werden Effekte sichtbar, die beispielsweise in einer klassischen Regressionsanalyse nicht entdeckt würden.
Grafik 2: Direkte, indirekte und totale Effekte
Im Falle unseres Kunden sind alle drei Punkte gegeben. Zusätzlich haben wir Grund zur Annahme, dass sich die vermuteten Wirkzusammenhänge zwischen Frauen und Männern unterscheiden, es also mit Blick auf die beiden Zielkonstrukte Kundenzufriedenheit und Loyalität bedeutsame Unterschiede zwischen den Geschlechtern gibt. Anhand von Strukturgleichungsmodellen lassen sich auch solche mutmasslichen Differenzen zwischen Subgruppen untersuchen. Dazu kann eine Multigruppen-Analyse (MGA) gerechnet werden, die prüft, ob sich die spezifizierten Wirkungspfade und Wirkungsbeziehungen zwischen verschiedenen Gruppen unterscheiden. So kann beispielsweise eruiert werden, ob die Loyalität der Frauen stärker durch bestimmte Aspekte geprägt wird als die Loyalität der Männer. Selbstverständlich ist es auch möglich, mittels einer MGA Unterschiede zwischen anderen interessierenden Gruppen – so z.B. Altersgruppen, Kundensegmenten oder auch Kunden vs. Nicht-Kunden – zu untersuchen.
Herausforderungen beim Einsatz von Strukturgleichungsmodellen
Im Falle unseres Kunden sind alle Voraussetzungen für den Einsatz eines Strukturgleichungsmodells gegeben. Doch häufig gibt es auch gute Gründe, auf ein Strukturgleichungsmodell zu verzichten:
Zum einen stellt ein Strukturgleichungsmodell höchste Ansprüche an die Datenqualität: Jedes verwendete latente Konstrukt wird durch mehrere (mindestens drei) passende Einzel-Items abgebildet. Diese müssen anhand entsprechender Modellierungen darauf geprüft werden, ob sie das Konstrukt ausreichend gut beschreiben. Die Messmodelle der einzelnen Konstrukte müssen anschliessend ebenso wie das Strukturmodell als Ganzes einer eingehenden Prüfung auf diverse Kriterien unterzogen werden. Erst wenn alle Kriterien erfüllt sind, kann ein Modell als gut bezeichnet und interpretiert werden. Erhebt man die Daten selbst oder lässt sie wie im Falle unseres Kunden durch ein mit der Materie vertrautes Befragungsinstitut erheben, so können diese Aspekte bereits in der Konzeptionsphase adressiert werden. Arbeitet man hingegen mit Sekundärdaten, so kann dies durchaus zu einer Herausforderung werden. Ein theoriebasiertes Vorgehen bei der Erarbeitung des Strukturgleichungsmodells und seiner einzelnen Komponenten ist in beiden Fällen unabdingbar.
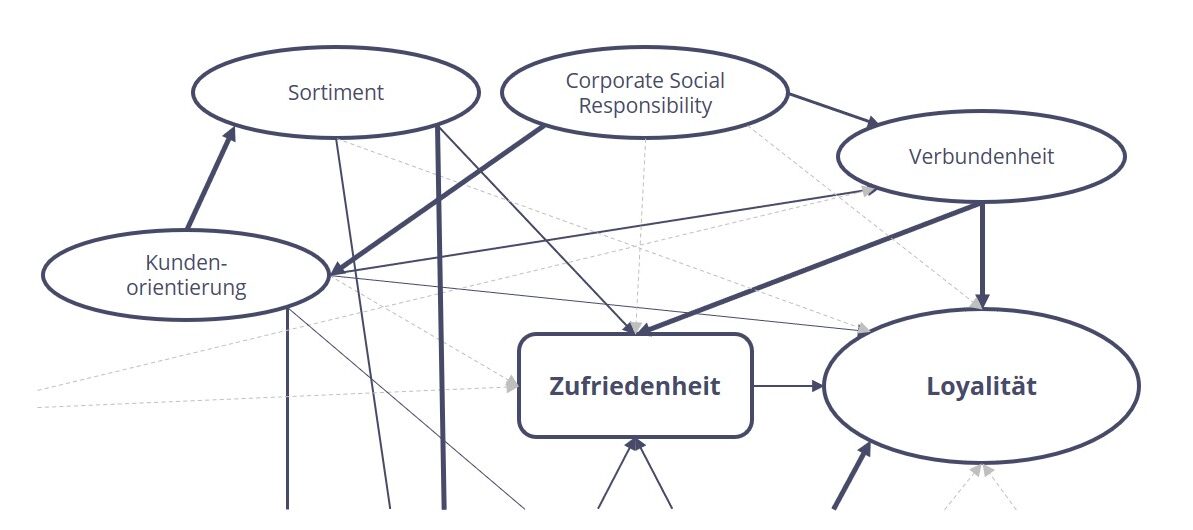
Zum anderen ist ein Strukturgleichungsmodell auch nicht in jedem Fall die geeignetste Methode: Häufig können die interessierenden Zusammenhänge auch mit einfacheren statistischen Verfahren wie zum Beispiel einer Regressionsanalyse gut analysiert werden. Die Komplexität von Strukturgleichungsmodellen bringt mit sich, dass diese nur von Expert:innen – notabene mithilfe spezieller Software – gerechnet und interpretiert werden können. Entsprechend höher sind auch die benötigten zeitlichen und personellen Ressourcen. Im konkreten Fall sollte daher immer ausgehend von der konkreten Fragestellung und gemeinsam mit Expert:innen entschieden werden, welches Vorgehen am sinnvollsten ist.
Grafik 3: Auszug aus einem Strukturgleichungsmodell
Der Mehrwert von Strukturgleichungsmodellen
Doch zurück zu unserem Kunden: Für ihn hat sich der Entscheid, ein Strukturgleichungsmodell rechnen zu lassen, definitiv gelohnt! Dieses hat nämlich gezeigt, dass die Corporate Social Responsibility – ein latentes Konstrukt, das über zehn Einzelfragen erhoben wurde – zwar keinen direkten Effekt auf die Loyalität hat, diese über andere Konstrukte (z.B. die Verbundenheit) aber indirekt dennoch deutlich prägt. Diese Effekte hätte eine klassische Regression nicht aufdecken können, da sie keinen vollständigen Wirkungsmechanismus mit verschiedenen Wirkungspfaden auf verschiedene Konstrukte berechnen kann. Dank des Strukturgleichungsmodells konnte der Einfluss der Corporate Social Responsibility auf die Loyalität nachgewiesen werden.
Eine vertiefte Auswertung einzelner Treiber der Corporate Social Responsibility brachte zudem weitere interessante Ergebnisse zutage: So konnte aufgezeigt werden, dass die drei Einzelaspekte «Fairness gegenüber Wettbewerbern», «Fairer Arbeitgeber» und «Beitrag zum Wohl der Gesellschaft», die das Konstrukt Corporate Social Responsibility im Kern ausmachen, zwar überdurchschnittlich wichtig für die Loyalität der Befragten gegenüber dem Kunden sind, von ersteren aber bislang unterdurchschnittlich bewertet wurden. Dank dieser Analyse, die wiederum alle direkten und indirekten Effekte einbezog, kennt unser Kunde nun diejenigen Aspekte, die das grösste Verbesserungspotenzial haben. Basierend auf diesen Erkenntnissen kann er konkrete Ideen zur Steigerung der Loyalität erarbeiten und Massnahmen im Bereich Corporate Social Responsibility gezielt vorantreiben.
Einsatzmöglichkeiten von Strukturgleichungsmodellen
intervista verfügt über umfassende Erfahrung und Expertise rund um Strukturgleichungsmodelle und weitere multivariate Analysemethoden. Wir setzen Strukturgleichungsmodelle in verschiedenen Bereichen erfolgreich ein, so zum Beispiel in der Werbewirkungsforschung oder in Kundenzufriedenheits- und Imagestudien. Zusätzlich bieten sich Strukturgleichungsmodelle dann an, wenn ein allgemeines Verständnis von Wirkungsabläufen etabliert oder geprüft werden soll.
In order to discuss the topic of ethics in market research we have to draw a distinction between “ethics“ and “compliance“. Ethics refer to a strong association to your organizational values, and “compliance“ evokes a legal obligation to do something like manage risk or adhere to regulations specific to privacy, for example General Data Protection Regulation or GDPR.
Trust is foundational to this topic and we may consider the thesis that there is a trust deficit. Why? In fact, trust should be core to general business and research practice as a whole. Trust as the old adage goes, takes many years to build, seconds to break and forever to repair.
To get from a metaphorical level to current research findings, please consider the following examples:
39% of UK public don’t trust marketers with their personal data.
According to a recent poll by the Global Research Business Network, only 34% of respondents from around the world said they trusted market research companies — similar to the level of trust they have in government.”
How data and research may be abused
The focus on the customer is one aspect of this narrative. For example, researchers may be unaware of the customer’s motives for the research and how the outcomes could be abused. The Cambridge Analytica scandal may indeed be the top of this iceberg. In the market research world, this polarity between consumer, enterprise and the potential for abuse presents questions about the governance model. Who is the target of this research and for what purpose?
In an article first published in 2010 by Marcus J. Schmidt, entitled, “Ethics in Marketing Research”, the author had pointed out some areas that are ripe for abuse such as “The market research agency may disguise errors in the survey or in statistical computations. Sometimes, clients have a hidden agenda and try pressurizing agencies to make them come up with certain prespecified findings. Clients may misuse a methodological framework developed by an agency and agencies may inappropriately reuse a research design worked out exclusively for a specific client.
Data mining techniques certainly have the potential of eroding trust and privacy. Frankly, there is not a day that passes without a breach or an abuse of data privacy being posted. In the end, what is required is a model that encourages transparent handling of data. Paving the path toward creating a “fair data” framework that could be standardized and may go beyond what we see today.
Protecting privacy – there is much more than guidelines
Data Ethics and Enhanced Privacy Techniques intersect with one another. Data Ethics are strategic for organizational boards as there is an opportunity to understand what data transparency research guidelines must be. In fact, the European Union has published recommendations for board level functions in this space. However, data privacy enhancing techniques are indeed a space to follow. The hypothesis is that data is never really anonymized especially when there is reference to so called metadata or data about data.
Self-Sovereign Identity or SSI is an example here. There are several principles that encompass SSI one of which is selective disclosure. Selective disclosure translates to disclosing what is required for the situation. Hence, SSI is contextual.
Earlier this year, Texas launched its Texas x Texas online portal, a single location for residents to access government services and connect with local agencies, and plans to make a TxT mobile app available for download in 2022. Both examples could be considered first steps toward self-sovereign identities (SSIs), where residents’ personally identifiable information is digitized and controlled by each individual, not a government agency.
SSIs are different from a physical form of identity, like a laminated driver’s license or a paper vaccination card. Physical IDs can contain a variety of information related to a person’s identity (birth date, home address, etc.). With a digital SSI, users control what and how much information they share and whom they share it with, and they can choose to provide only the information necessary to complete a transaction. No information is kept by the organization asking for identification, and everything remains in the user’s control.
It’s not unusual for residents to interact with their local agencies multiple times every year. One person might renew a driver’s license, apply for a building permit and pay taxes in a single month. Each interaction requires signing in to different portals, with different credentials, and filling out the same personal information, even if not all of that information is required for the transaction.
With an SSI, the individual only gives out what is required for that specific transaction and can dictate how that data is used. For example, a person applying for a liquor license for a business may not be required to provide home address. With an SSI, they don’t have to — they can just provide whatever information is necessary to complete the transaction. The same goes for something like a vaccine passport — there‘s no need for a Social Security number to be shared during the validation process. It‘s enough for a user to verify vaccine status — no other personal details are required.
More tools enhancing privacy
The toolkit against data leakage includes Differential Privacy, Homomorphic Encryption, Secure Multiparty Computation, Zero Knowledge Proofs or ZKPs. This is an alphabet soup of Privacy Enhanced Techniques or PETS. In fact, Gartner believes that over half of organizations will implements PETS by 2025. Differential Privacy applies a mathematical definition to privacy itself. Homomorphic Encryption [HE] permits computations to be performed on encrypted data without access to the secret key. We commonly see HE used in cloud implementations with a variety of use cases that include healthcare as an example.
Secure Multiparty Computation or sMPC can be thought of as a cryptographic primitive where functions can be jointly computed without revealing the outputs. We have been witnessing the commercialization of Zero Knowledge Proofs or ZKPs over these past several years. The application is that I can prove something is true without revealing the data that proves it. One common use case cited is age, “I am between the age of x and y.” Bringing academia and enterprises together for ZKP has been the motivation for the Zero Knowledge Proof Standards Group.
Understanding how these PETs can be applied in market research is an industry opportunity. Finally, what kind of Ethics-Trust Barometer do you want to create? We have only discussed the tip of the iceberg on this topic on making the case of ethics in market research. I do look forward to continuing the discussion further!
Monique Morrow
The Humanized Internet
Senior Distinguished Architect for emerging technologies at Syniverse Technologies
The autor With over 25 years’ experience as a global technology leader, Monique Morrow is Senior Distinguished Architect for emerging technologies at Syniverse Technologies where her main role and responsibilities are to provide thought leadership and to develop the strategic direction and vision for Syniverse‘s emerging technologies across the company, partners and industry forum. Monique‘s expertise are in cybersecurity, privacy, mobile payments, ethics in extended reality and distributed ledger technologies for example, blockchain.
Der Umgang mit Daten soll das wichtigste Thema im Marketing 2022 werden. Wer sein Business im Griff haben will, muss die dazugehörigen Daten im Griff haben. Dabei mangelt es im Marketing nicht an Daten, zumindest theoretisch nicht. Die Herausforderung besteht vielmehr darin, Daten nutzbar zu machen. Datenhoheit bedeutet, die Daten zu besitzen und alle Möglichkeiten zu haben, sie zu verarbeiten und zu interpretieren. In diesem Text geht es um den sicheren und sinnvollen Umgang mit Daten, die passenden Tools und Strategien, um Daten zu nutzen.
Mit mehr Technologie im Marketing wird die Frage nach Datenhoheit wichtiger
Viele der Technologie-Trends, die in den letzten Jahren im Marketing gehypt wurden, sind mittlerweile in der Praxis angekommen. Investitionen in Technologie nehmen zu. Anders ausgedrückt: Ein steigender Anteil des Marketing-Budgets fliesst in Tools, welche Kundendaten analysieren.
Damit wird Datenhoheit immer wichtiger, denn wer ihre:seine Daten im Griff hat, hat auch ihr:sein Business im Griff. Im Marketing sehen wir eine alltäglich gewordene Auseinandersetzung mit Daten, Automatisierung und AI.
Die Herausforderungen: Datenschutz, Datensicherheit und Datenhoheit
Datenschutz und Datensicherheit sind nicht gleich Datenhoheit. Vielleicht fangen wir aber erst einmal bei der Datenunsicherheit an: Unternehmen sind nach wie vor verunsichert, gar paralysiert, wenn es um den sicheren Umgang mit Daten geht. Dabei drehen sich die Fragen nicht nur um das Speichern der Daten, sondern vor allem darum, wie wir denn aus Daten etwas machen können. Schnell werden die grossen Datensammler als «Kraken» und «Manipulierer» bezeichnet.
Doch was Facebook & Co. mit Daten machen, ist die falsche Frage: Es geht vielmehr darum, Unternehmen Instrumente an die Hand zu geben, damit sie ihre eine eigene Datenstrategie aufbauen können.
Viele tun das, was ein Tool kann: Sie begnügen sich mit dem, was dessen vorgefertigtes Dashboard bietet. Sie digitalisieren also reaktiv statt proaktiv. Doch Daten, die über die Kundeninteraktionen gesammelt werden, bergen Potenzial, das viele noch nicht ausschöpfen.
Marketer:innen, die ihre Daten wirklich im Griff haben wollen, brauchen eine Lösung und ein Setup, in dem sie sich nicht Sorgen machen müssen um ihre Daten oder darum, ob sie datenschutzkonform damit arbeiten. Zentral dabei ist erst einmal, dass es ihre Daten sind und bleiben; dass sie in ihrer eigenen Datenbank liegen. Diese Datenhoheit ist die Grundlage für eine ganzheitliche Datenstrategie.
Wie wir Datenhoheit erreichen
Datenhoheit bedeutet, dass die Wählen Sie ein Tool, dass Ihnen die freie Wahl lässt, wo Sie die Daten speichern und welches diese nicht zwingend einem Software zuführt. Bei Aivie erhalten Kund:innen ein (datenschutzkonformes) Hosting ihres Tools und somit auch ihrer Daten.
Dazu baut Aivie auf Open Source Technologie. Das bedeutet, die zugrundeliegende Technologie ist frei verfügbar. Jede:r kann sie nutzen, für sich anpassen und einsetzen. Entgegen manchen Ängsten bedeutet Open Source nicht, dass alle Zugriff auf die eigene Anwendung haben.
Mit Open Source haben wir alle Möglichkeiten für maximalen Datenschutz, denn wir können die Technologie genau so aufsetzen, wie wir möchten. Wir hosten die Daten sicher in der Schweiz oder auf Servern in Europa, die den höchsten Standards entsprechen. Alternativ auch «on premise», heisst auf von Kund:innen gewünschten, eigenen Servern. Die Daten sind und bleiben damit in der Hoheit des jeweiligen Unternehmens. Auf dieser Grundlage bauen wir Marketing Automation auf: Kenne deine Kunden, besitze deine Daten – beherrsche dein Business!
Neben Datenhoheit hat uns der Open-Source-Ansatz auch damit überzeugt, dass wir und die Kund:innen mit der offenen Technologie unzählige Möglichkeiten haben, weitere Tools und Funktionalitäten zu integrieren. Das geht mit entsprechenden Schnittstellen, sogenannte APIs, Webhooks oder Plugins. Auch bei der Auswahl von zu integrierenden Tools beschäftigt uns natürlich die Frage nach dem Umgang mit Daten.
Wie wir uns für ein Marketing Tool entscheiden
Im Grunde geht es darum, dass Systeme miteinander kommunizieren und automatisch Daten austauschen können. Wir arbeiten zum Beispiel an besseren Integrationen mit Google und Social Media Ads und an Schnittstellen zu offline Touchpoints.
Diese Indikatoren sind wesentlich bei der Entscheidung für oder gegen ein bestimmtes Tool:
Grösse und Offenheit der Entwickler- Community
Gängige Programmiersprache, Verfügbarkeit und Kosten Entwicklung
Open Source (offener Code) Anteil
APIs (wie viel lassen die Schnittstellen zu)
Können existierende Tools verbunden werden (zu einer end-to-end Customer Journey)?
Wie teuer ist das Tool in 5-10 Jahren (hohe Wechselkosten, bzw. Gefahr Locked-in zu sein)?
Was sind die Total Cost of Ownership? (TCO)
Inwiefern wird die Customer Experience dadurch verbessert?
Wenn Customer Experience und State-of-the-Art-Technologie zusammenpassen, kombinieren wir die Tools mit den entsprechenden Integrationen zu einem sinnvollen MarTech Stack.
Einen MarTech Stack aufbauen
Während es sich für Grossunternehmen und Konzerne unter Umständen lohnt, eigene Lösungen zu entwickeln, setzen kleine und mittlere Unternehmen auf Kombinationen von vorkonfektionierten Lösungen – einen MarTech Stack. Dieser beinhaltet Lösungen für Marketing Automation, CRM, eCommerce, Bestell- und Bezahlprozesse. So kommen Unternehmen dann schon mal auf über zehn verschiedene Tools, die Daten untereinander austauschen.
Fragen, die uns bei der Wahl der passenden Tools begegnen, sind insbesondere:
Wem gehören die Daten?
Welche rechtlichen Rahmenbedingungen gilt es zu berücksichtigen?
Wozu verpflichte ich mich genau?
Gibt es Beratung und Support?
Wie geschieht die Integration von neuen MarTech Tools mit dem vorhandenen CRM?
Wie gestalten sich die Schnittstellen mit eCommerce bzw. eigenen Apps und Websites generell?
Welche Prozesse können wir über das Marketing hinaus automatisieren?
Wie steht es um die Benutzerfreundlichkeit und Anpassbarkeit an meine Bedürfnisse?
Grundsätzlich geht ja alles. Die Frage ist, mit welchem Tool oder welcher Technologie man effektiv und effizient zum Ziel kommt. Daher gilt es nicht nur zu prüfen, was heute unter dem Gesichtspunkt der Convenience an Integrationen mit eigenen Tools möglich sein muss, sondern auch kritisch und vorausschauend die Offenheit der Systeme für künftige Integrationen zu ermitteln.
Daten nutzen für zunehmende Personalisierung eine Frage der Skills
Die Personalisierung wird stetig zunehmen. Kund:innen fordern sie. Sie mögen es bekanntlich nicht, wenn sie sich wiederholen, Prozesse mehrfach durchlaufen müssen oder Botschaften erhalten, die für sie keine Relevanz haben. Das ist Zeit- und Energieverschwendung und somit frustrierend.
Kund:innen zu kennen bedeutet ihre Daten lesen und auswerten zu können. Dafür benötigen wir nicht nur die passenden Tools, sondern auch die entsprechenden analytischen Skills.
Als Dozentin an der Hochschule erlebe ich das praktisch in allen Kursen: Die Teilnehmer:innen kennen alle schon irgendwelche Tools. Praktisch jede:r hat schon diverse Marketing- oder Kommunikations-Tools ausprobiert. Jedoch mangelt es an den Skills im Umgang mit den Daten, welche die Tools liefern. Viele schauen nur die ganz einfachen Statistiken an: in der Regel aggregierte Daten. Zu wenige integrieren individuelle Interaktionsdaten und nutzen sie, um ihre Kommunikation zu verbessern.
Eine verbesserte Kommunikation bedeutet eine persönlichere Ansprache – im richtigen Moment die passende Botschaft. Dafür müssen die Nutzer:innen wissen, wo ihre Kund:innen aktuell stehen. Das lässt sich in aus Interaktionsdaten erkennen.
Interaktionsdaten und kontinuierliches Kund:innen-Feedback
Entscheidend ist, das Verhalten von Besucher:innen und Kund:innen zu nutzen und entsprechend zu reagieren. Also auf Trigger mit den passenden nächsten Inhalten und Angeboten zu reagieren. Aus meiner Sicht bieten die Möglichkeiten mit Marketing Automation im entscheidenden Moment die richtigen Fragen zu stellen aktuell das grösste, noch wenig genutzte Potenzial.
Persönlich arbeite ich nach dem Prinzip, dass ich mit jeder Interaktion etwas erreichen, aber auch etwas lernen möchte. Erreichen bedeutet in der Regel eine Form der Conversion, ein nächster Schritt. Das Lernen kommt in vielen Fällen noch etwas zu kurz. Klar kann ich auch aus der Conversion lernen. Ein Beispiel, das wir alle kennen, ist, wenn wir nach einem Bestell- oder Onboarding-Prozess gefragt werden, wie zufrieden wir mit der Interaktion sind. Oder wenn wir nach einem Kauf oder Konsum gefragt werden, wie gut wir das Produkt oder den Service finden.
aivie: Continuous Profiling mit Formularen
Viele Unternehmen geben nach wie vor grosse Marktforschungsstudien in Auftrag, z. B. einmal im Jahr, in der Hoffnung, die Antworten auf die strategischen Fragen von potenziellen Kund:innen zu bekommen. Eine jährliche MaFo-Befragung mag zwar hilfreich sein, sie ist im digitalen Umfeld jedoch nicht hinreichend.
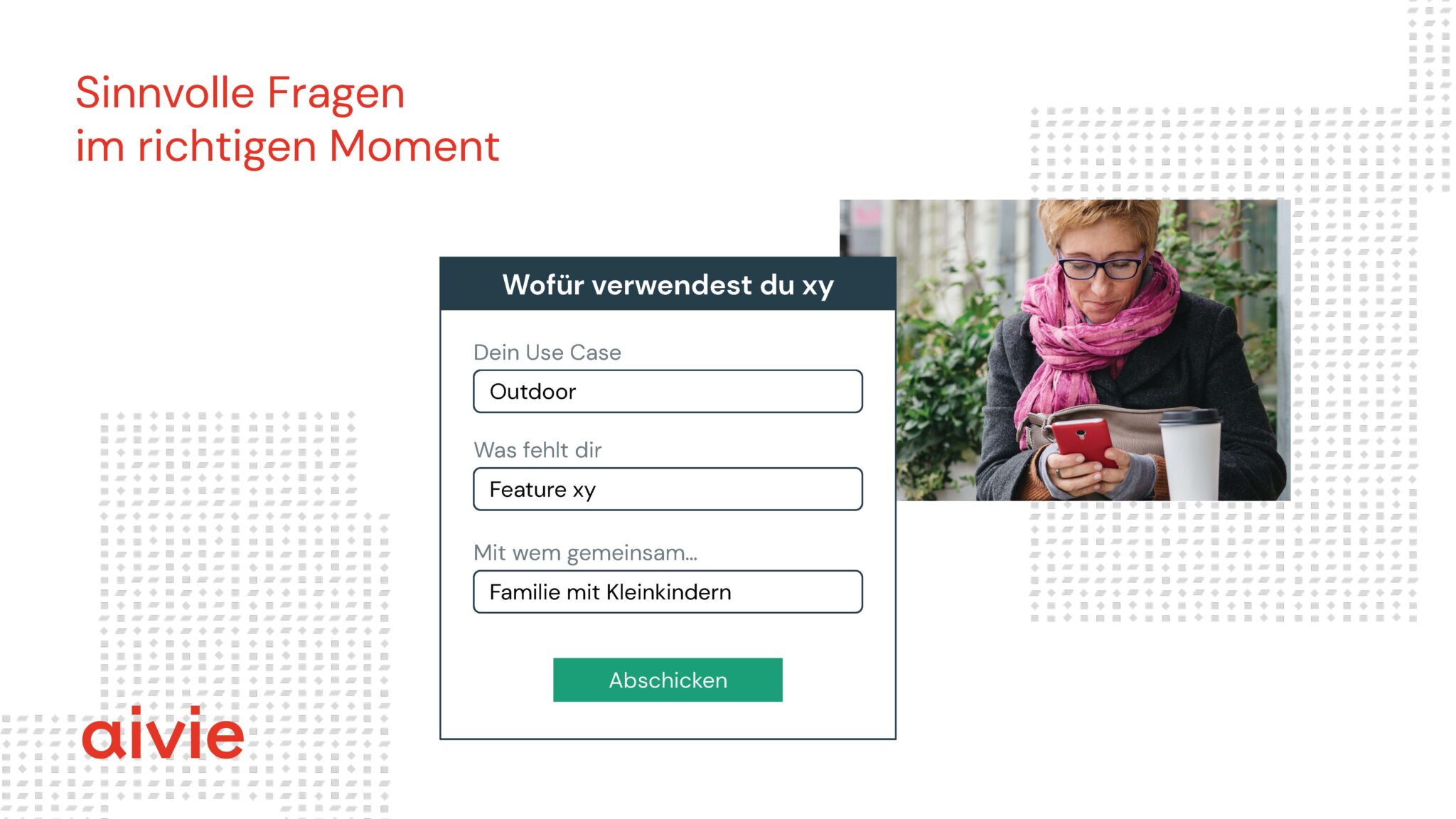
Wer in der entscheidenden Situation, im Moment der Interaktion, ein bisschen tiefer geht, hat längerfristig einen Nutzen. Z. B. können wir bei einem Bestellprozess zwischendurch auch fragen, wozu genau das Bestellte verwendet werden soll oder was als Erstes damit gemacht wird. Das liefert uns weitere Hinweise für die Use Cases und ist in dem Moment eine angemessene Frage. Im Gespräch würden wir diese ohne weiteres stellen. Nach einem Kauf oder Konsum könnten wir z. B. fragen, in welcher Situation das Produkt oder der Services bisher schon hilfreich war oder wem man schon davon erzählt hat. Das gibt uns wiederum Hinweise für die Kommunikation der Benefits unseres Angebots. Grundsätzlich geht es uns ja immer darum zu erfahren, warum und wozu Besucher:innen und Kund:innen tun, was sie tun, also die Intention hinter ihrem Verhalten zu erkennen.
Konkret setzen wir das um im Rahmen automatisierter Kampagnen, mit kurzen Formularen, mit einzelnen Fragen. Ich wende diesen Ansatz auch in der Forschung an, um Verhaltens- und Interaktionsdaten anzureichern. Kontinuierliches Kund:innen-Feedback einzuholen, bedeutet schlauer Daten zu sammeln. Instantly, im richtigen Moment, dann, wenn es relevant ist. Mit den angereicherten Interaktionsdaten haben wir Möglichkeiten, mit Data Analytics und Machine Learning zu besseren Erkenntnissen zu gelangen, Kund:innenwissen zu nutzen und proaktiv Lösungen zu gestalten oder vorzuschlagen. Damit lassen sich die Kommunikation und mit ihr die Angebote anpassen: die Value Proposition in jeder Interaktion, die zugrundeliegenden Produkte und Services. Daten geben also auch neue Möglichkeiten, das eigene Angebot, die eigene Wertschöpfung zu definieren.
Kostenloses Webinar am 15. Februar 2022
Sind Sie interessiert an Strategien für einen sicheren und sinnvollen Umgang mit Daten im Marketing?
Datenstrategien und Datenhoheit im Marketing: – Daten sinnvoll integrieren – Daten in automatisierten Kampagnen nutzen – Kontinuierliche Kund:innendaten sammeln und anreichern
Darüber spricht Dr. Sarah Seyr im kostenlosen Webinar am 15. Februar 2022 um 16:00 Uhr online
Wir freuen uns, Ihnen den Swiss Insights Report 2021 der Swiss Data Insights Association zustellen zu dürfen.
Die Verbands-Transformation mit dem zweiten Standbein Data Science schreitet voran. Im Swiss Insights Reports finden sie interessante Artikel sowohl aus der Welt der Data Science wie auch aus der klassischen Marktforschung.
Im letzten Drittel stellen sich einige Mitgliederinstitute vor. Verschaffen Sie sich einen Überblick über die Branche.
Immer mehr Zeit verbringen wir in der digitalen Welt – ob beruflich oder privat. Trotzdem oder gerade deshalb wird es immer schwieriger, das Publikum online anzusprechen. Auch die Online-Marktforschungsbranche und ihre Researcher kämpfen um die Zeit und Aufmerksamkeit der Teilnehmenden, während diese ihre Endgeräte nutzen. Die Response-Rates von E-Mail-Einladungen zu Befragungen sinken besonders bei jungen Menschen. Ähnliches gilt für Forschungs-Apps von Drittanbietern, die unter niedrigen Akzeptanzraten leiden.
Die Digitalisierung ermöglicht es Menschen, sich weltweit und kulturübergreifend zu vernetzen. Sie erleichtert aber auch die Versuche unterschiedlichster Akteure, Einfluss auf Wahlen und Abstimmungen zu nehmen. Die Diskussionen um Fake News, Echokammern und die Polarisierung der Gesellschaften werden aktuell hitzig geführt. Die Frage wie die Digitalisierung die politische Meinungsbildung prägt, ist zurzeit omnipräsent. Die Studie von gfs.bern im Auftrag der TA-SWISS enthält dazu eine Bestandesaufnahme. Sie zeigt, wie das schweizerische Politiksystem der Digitalisierung ausgesetzt ist und wie es darauf reagiert: Neue Chancen stehen neuen Gefahren und Risiken gegenüber. In der Schweiz trifft der digitale Strukturwandel aber vor allem auf eine reife Bevölkerung, die gewohnt ist, mit politischer Reibung umzugehen.
Der digitale Strukturwandel ist eingebettet in die Grundprinzipien der direkten Demokratie. Damit nämlich ein politischer Entscheid getroffen werden kann, sind die Stimmbürger:innen auf die Möglichkeit zur freien Willensbildung angewiesen. Dabei sind die Stimmberechtigten durchaus fähig, sich aus einer Breite und Fülle von Informationen mit unterschiedlicher Ambition und unterschiedlichem Wahrheitsgehalt eine eigene Meinung zu bilden.
Meinungsbildung entsteht aber nicht erst im Twitterfeed, sondern fusst immer auf sogenannten Prädispositionen, auf deren Grundlage die Stimmberechtigten politische Entscheidungen treffen. Diese bestehen aus grundsätzlichen Werthaltungen und Einstellungen, aber auch aus Alltagserfahrungen und Prägungen aus der eigenen Sozialisation. Ist ein Thema stark prädisponiert, nützt auch die lauteste Diskussion auf Social Media nichts, die Meinungen sind gemacht.
Hohes Vertrauen in das politische System Es erstaunt auf einer solchen Basis nicht: Die Schweizer Stimmberechtigten haben ein im internationalen Vergleich ungewohnt hohes Vertrauen in das politische System und stützen den Gesetzgebungsprozess regelmässig an der Urne (in der Legislatur 2016 bis 2019 waren von 17 Gesetzesreferenden nur gerade zwei an der Urne erfolgreich). Die einzelnen Stimmberechtigten haben ein erfolgreich erprobtes Vorgehen, sich in aufgeladenen Kampagnensituationen mit Informationen seitens konträrer Akteurinnen und Akteure eine stimmige Meinung zu bilden, respektive im politischen Diskurs generell zu navigieren.
Alle diese Elemente helfen sichtbar auch bei der Nutzung von Social Media. In Fokusgruppen direkt darauf angesprochen wird in der Folge auch betont, dass sich gerade Junge durchaus fit fühlen, Informationen via Social Media zu prüfen und politisch einzuordnen, nicht zuletzt auch deshalb, weil die wenigsten für politische Meinungsbildung nur Social Media nutzen.
Gefährlich wird es deshalb erst dann, wenn sich ganze Gruppen aus der Informationssuche in der Breite verabschieden und in abgeschlossene Diskurssysteme und damit in Parallelrealitäten zurückziehen. Diese Gruppe entzieht sich sehr bewusst einem Teil der Diskussion, nicht nur im Social-Media-Raum, sondern ganz grundsätzlich.
Die Digitalisierung verändert das politische System der Schweiz Digitalisierung trifft nicht nur auf eingespielte politische Meinungsbildungsprozesse, sondern auch auf ein etabliertes politisches System im Wandel. Das politische System der Schweiz ist grundsätzlich nicht in Stein gemeisselt. Anpassungen der Prozesse und Entscheidungsmechanismen definieren das System immer wieder neu. Aktuell lassen sich in der Schweiz Veränderungen entlang der Konkordanz und ein Erstarken populistischer Kräfte sowie populistischer Politikbildung beobachten. Dabei gibt es starke Hinweise darauf, dass die Digitalisierung der Schweizer Politik nicht ursächlich für Populismus oder abnehmende Konkordanz ist, sondern schon bestehende Entwicklungen unterstützt.
Weltweit werden durchaus laute Diskussionen darüber geführt, inwiefern hauptsächlich Populismus die Demokratie gefährdet und nebensächlich Social Media einen verstärkenden Beitrag dazu leisten. Aktuell kann eine solche Diskussion in der Schweiz aus einer relativ entspannten Situation heraus initiiert werden: Das Vertrauen der Bevölkerung in das politische System und die Behörden ist im internationalen Vergleich hoch, fakultative Referenden sind grossmehrheitlich nicht erfolgreich. Der Diskurs sollte dennoch geführt werden, denn Triebkraft zur Beschleunigung haben die neuen digitalen Formen der Politisierung durchaus, seien es Social Media als Verstärker von populistischen Botschaften, sei es E-Collecting mit der potenziellen Gefahr, ein politisches System mit einer Vielzahl an Referenden zu blockieren.
Chancen und Risiken der Digitalisierung Entlang dieser Grundaspekte bietet die Digitalisierung zahlreiche neue Möglichkeiten um den politischen Alltag einfacher und zugänglicher zu machen. Die Digitalisierung der Schweizer Politik hat sichtbar das Potenzial, einer freien Meinungsbildung zuzudienen. Die Möglichkeiten zum herrschafts- und hindernisfreien direkten Diskurs nehmen zu, die neuen Kommunikationsinstrumente können Inhalte zielgruppengerechter und damit präziser zur Verfügung stellen, und durch digitale Partizipationsformen können neue Zielgruppen, aber auch schwer politisierbare Themen verstärkt in den politischen Diskurs einfliessen.
Allerdings behindern die Geschwindigkeit in der Informationsverbreitung, der niederschwellige Zugang ohne journalistische Qualitätskriterien sowie das Geschäftsmodell der Plattformbetreiber potenziell eine freie Willensbildung. Bei Social Media sind also die Vorteile und die Nachteile hochgradig miteinander verknüpft. Mögliche regulative Eingriffe wären auch Eingriffe in Chancen und insbesondere in die Meinungsäusserungsfreiheit und damit in die freie Willensbildung.
Die Digitalisierung der Schweizer Demokratie bringt ebenso sichtbar eine Reihe von Risiken mit sich, wobei das im öffentlichen Raum am häufigsten diskutierte Thema Missinformation und Desinformation ist. Insgesamt sind solche Fehlinformationen in der politischen Kommunikation nichts Neues, die Digitalisierung hat aber insbesondere die Verbreitungspotenz und –geschwindigkeit massiv erhöht.
Problematisch ist in diesem Kontext, dass Autor:innen von Social-Media-Informationen weder an journalistische Ethik gebunden sind, noch (in den meisten Fällen) über journalistische Fachkompetenz verfügen. Durch den Wegfall dieser traditionellen Gatekeeper-Funktion von journalistisch arbeitenden Redaktionen fallen zentrale Elemente der Qualitätskontrolle und Wahrheitsprüfung weg.
Die Regeln der Plattformen und amerikanische Sichtweisen prägen den Diskurs mit Schlussendlich dürfen wir nicht vergessen: Gerade die grossen Social-Media-Plattformen sind weder für den politischen Diskurs geschaffen worden, noch haben sie einen solchen als übergeordnetes Ziel. Faktisch entscheiden weitgehend die Plattformen, welche Informationen die einzelnen Nutzenden sehen und damit im Rahmen ihrer politischen Willensbildung verarbeiten können. Die Selektionskriterien sind dabei nicht abschliessend transparent und folgen sicher nicht hauptsächlich der Logik politischer Relevanz.
Vielmehr beruht ihr Geschäftsmodell im Kern darauf, dass Nutzerinnen und Nutzer möglichst oft und lange auf den jeweiligen Plattformen verweilen. Dazu kommt ein stark in der amerikanischen Gesellschaft verankertes Verständnis von Meinungsfreiheit: Diese wird wesentlich über andere Rechte des Persönlichkeitsschutzes gestellt, was insbesondere weltweit spürbare Folgen darauf hat, welche Informationen auf diesen Plattformen verfügbar sind. Solange die einzelnen Staaten ausserhalb der USA darauf sowohl ressourcenseitig als auch juristisch nur wenig Einfluss nehmen können, prägt diese amerikanische Sicht auf Meinungsfreiheit, notabene entstanden in einem höchst konkurrenzdominierten dualen Parteiensystem, auch die Diskurskultur in der Schweiz mit.
Die Studie ist eine von insgesamt drei Studien, die im Rahmen des Projekts «Bürger und Institutionen angesichts der Digitalisierung der Demokratie in der Schweiz» im Auftrag von TA-SWISS erarbeitet worden sind und ist unter folgenden Links zum Download verfügbar: Publikationen | TA-SWISS Download pdf
Urs Bieri
Co-Leiter und Mitglied des Verwaltungsrates von gfs.bern
Marco Bürgi
Junior-Projektleiter bei gfs.bern
Zu den Autoren
Urs Bieri ist Co-Leiter und Mitglied des Verwaltungsrates von gfs.bern und beschäftigt sich in der angewandten Forschung seit 25 Jahren mit gesellschaftlichen und politischen Meinungsbildungsprozessen.
Marco Bürgi arbeitet seit 2020 als Junior-Projektleiter beim Forschungsinstitut gfs.bern. Aktuell schliesst er den Master Schweizer und vergleichende Politik an der Universität Bern ab.