
Eine Bürgerin sucht nach Daten der öffentlichen Statistik in der Schweiz: Die Wahrscheinlichkeit ist hoch, dass damit eine digitale Odyssee beginnt, statt, dass die Suche nach einer kurzen Suchmaschinenanfrage endet. Denn selbst für erfahrene Recherchierende ist es nicht immer leicht, Daten zu finden: Befinden sich die gesuchten Daten vertikal auf Ebene Bund, Kantone oder Gemeinden? Und welche Behörde oder welches Amt stellt innerhalb einer Ebene die Daten bereit? Die Suchmaschinen haben Mühe, die gesuchten Informationen zu indizieren, da sie sich in verschiedenen Applikationen oder sogar Dokumenten befinden. So klicken sich die Bürger durch, bis sie die gewünschten Informationen erhalten – oder bis sie die zuständige Stelle gefunden haben, bei der sie ihre Anfrage platzieren können.
Machine learning to the rescue?
Können wir nicht einen Algorithmus trainieren, uns die richtigen Antworten auf unsere Fragen zu liefern? Ist es nicht genau das, was Google und Co. machen und nicht immer schaffen? Unsere Schlussfolgerung ist: Wenn die Daten nicht «richtig aufbereitet» sind, dann fehlen die Grundlagen für die Anwendung eines fortgeschrittenen Algorithmus.
Die benötigten Daten der Schweizer Behörden stehen qualitativ hochwertig zur Verfügung. Trotzdem ist es nahezu unmöglich, einen Algorithmus im Umgang mit diesen Daten so zu trainieren, dass er die Frage «was ist der Anteil der registrierten Elektroautos im Kanton Zürich» korrekt beantwortet.
Das seit längerer Zeit bekannte Problem von maschinell nicht lesbaren Datenformaten wie Excel oder PDF spielt dabei nur eine kleine Rolle. Vor allem fehlt es in der Schweiz an einheitlichen Ansätzen für Datenstrukturen; nicht nur zwischen den verschiedenen Datenproduzenten, sondern sogar innerhalb deren jeweiligen Datenportalen. Die Probleme sind:
- Qualität (wahr und nicht suggestiv)
- Ohne menschliches Zutun sind zeitliche Elemente, räumliche Elemente, Dimensionen und Attribute nicht identifizierbar.
- Die Daten sind uneinheitlich sowohl im «Long-Format» wie auch im «Wide-Format» –
- zusätzlich findet man manchmal sogar Kreuztabellen oder gar Listen.
- Es fehlt eine Standardisierung der verwendeten Codes und Labels.
- Die Definitionen der relevanten Daten sind nicht in jedem Fall harmonisiert – beispielsweise errechnen Bund, Kantone und Gemeinden die Bevölkerungszahlen der Stadt Zürich leicht unterschiedlich.
- Spalten gleicher Datenkategorien sind unterschiedlich benannt
Als Konsequenz dieser unterschiedlichen Datenstrukturen ist der Bau jeglicher datensatzübergreifenden Applikation mit beträchtlichem Aufwand verbunden – unabhängig davon, ob es sich um eine High End Machine-Learning-Lösung oder um ein simples Indikatorenportal handelt. Selbst wenn nur die Daten aus einem einzigen Datenportal eingelesen werden, kann die Menge der eingelesenen Datasets nicht beliebig vergrössert werden, da man für jedes Dataset einen separaten Code schreiben muss.
Standards and data harmonization to the rescue!
Hier setzen wir mit dem Projekt statbot.swiss an. Finanziert wird es durch eGov Schweiz, geleitet vom Bundesamt für Statistik und der Konferenz der regionalen statistischen Ämter der Schweiz. Technologische Partner sind die Zürcher Hochschule für angewandte Wissenschaften (ZHAW) sowie das Swiss Data Science Center (SDSC).
Das Projekt besteht aus zwei Teilen: Im chronologisch zweiten Teil experimentieren Forschende der Zürcher Hochschule für angewandte Wissenschaften an einem Machine-Learning-Algorithmus, der natürliche Sprache in Datenbankabfragen übersetzen kann [1]. Dieser soll die Antworten in Form von Datenwerten, Tabellen oder Grafiken anzeigen. Das aktuelle Projekt setzt dabei den Fokus absichtlich und bescheiden auf die Abklärung der Machbarkeit und der technischen Limitierungen.
Im bereits abgeschlossenen ersten Teil des Projekts haben wir ein Open Source Data Warehouse [2] gebaut, das Daten aus unterschiedlichen Quellen an einem Ort integriert und harmonisiert. Es lädt die Daten aus unterschiedlichen Schnittstellen, führt die gesamte Transformation («ETL») aus und erstellt alle Daten in einer einheitlichen, definierten Datenstruktur mit dazugehörenden Mapping-Tabellen für Dimensionen. Ziel war auch, die Datenstandardisierung und -harmonisierung voranzubringen.
[1] Die ZHAW leitet das Projekt «INODE – Intelligent Open Data Exploration», das vom EU-Forschungsprogramm Horizon 2020 mit knapp 6 Millionen Euro gefördert wird.).
[2] https://renkulab.io/gitlab/christian.ruiz/statbot-swiss
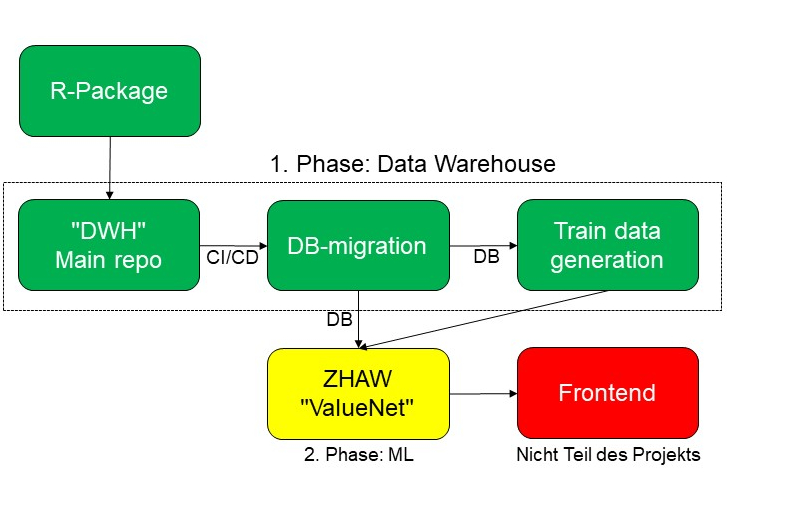
Das Hinzufügen der Daten ist dabei skalierbar: wir konnten Stand heute über 240 «Statbot-Datasets» mit Inputdaten sowohl aus dem Bundesamt für Statistik wie auch aus sechs weiteren regionalen Statistikämtern hinzufügen. Wir haben dabei einen Prozess geschaffen, der keine Programmierung durch Mitarbeitende von teilnehmenden Statistikämtern benötigt. Stattdessen brauchen diese nur das sprichwörtliche Rezept anzugeben, wie die Daten verarbeitet werden sollen: Für einen Milchshake müssen die Früchte gewaschen, geschält, dann in den Mixer gegeben und am Ende mit Milch gemischt werden. Die Reihenfolge dieser Schritte gibt der Mitarbeitende ein einziges Mal ein, dann kann die Maschine regelmässig die aktuellsten Inputdaten holen und die notwendigen Transformationen durchführen.
Wichtig ist dabei auch, dass dieser Endzustand aller Datasets gleich ist, wobei wir hier eine Lösung gefunden haben, die sich an bisherigen Ansätzen orientiert [3]. Als zusätzlicher Schritt müssen daher Dimensionen «harmonisiert» werden. Jede Dimension wie Geschlecht oder Staatsangehörigkeit hat dabei gewisse Codes. Wenn die Standardcodes (üblicherweise aus dem Bundesamt für Statistik) verwendet werden, läuft das Matching ohne grösseren Zusatzaufwand. Ansonsten können neue Mappings hinzugefügt werden, um eine flexible Zuordnung herzustellen.
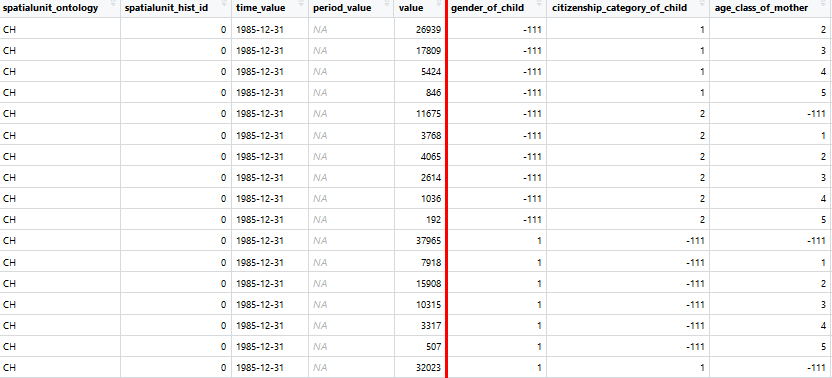
Das Resultat sind relationale Daten in einer definierten Struktur mit einheitlichen Spaltenbezeichnungen, Zuordnung von Raum, Zeit, Dimensionen sowie Attributen und klar bestimmten Kodierungen [4].
Diese «Statbot-Datasets» sind somit einheitlich strukturiert. Damit ist es leichter, daraus datensatzübergreifende Applikationen zu bauen, beispielsweise eine Machine-Learning-Lösung wie im zweiten Teil des Projekts oder ganz andere Applikationen, die nun auf solche bereinigten Daten zugreifen könnten.
[3] Es orientiert sich sowohl an der Linked Data Lösung von Statistik Stadt Zürich wie auch am SDMX-Format, welches u.a. von Eurostat verwendet wird. Die Überlegungen gehen dabei noch weiter, ob sogar diese Formate generiert werden könnten.
[4] Momentan fehlt eine Vorgabe für eine «definierte Struktur» von Statistikdaten in Schweizer Statistikämtern. Diese funktionale Vorgangsweise könnte auch als Bottom-up-Lösung dienen, um einer Harmonisierung schrittweise näher zu kommen.
Weiteres Potenzial
Das Projekt lehrt uns viel über Machine Learning. In Machine-Learning-Projekten geht es um weit mehr als den Gebrauch der Algorithmen. Viel Arbeit muss in Grundlagenarbeit gesteckt werden, um die Daten für Algorithmen überhaupt brauchbar zu machen. Dazu gehört auch die Bereitstellung von «Trainingsdaten», also Paare von Fragen in natürlicher Sprache und passenden Antworten in Form von Datenbankabfragen. Die werden dann verwendet, um den Algorithmus zu trainieren. Hier haben wir mit zusätzlichen Sprachinformationen gearbeitet, um sinnvollere Sätze zu generieren, die aber dennoch etwas hölzern erscheinen.
Die klare Trennung von Inhalt und Bezeichnung und die einheitliche Strukturierung und Harmonisierung der Bezeichnungen im Data Warehouse werden es darüber hinaus erlauben, automatisiert hochwertige «Linked Open Data» zu generieren. Linked Open Data sind Daten, die schnittstellenartig per HTTP abgerufen werden können, und die auf weitere Ressourcen verweisen können.
Dies würde vernetzte Datenlösungen ermöglichen, welche Daten aus den verschiedensten Quellen kombinieren könnten und es würde ein semantischer Datenraum geschaffen werden. Das wäre ein zusätzlicher Mehrwert für Nutzende, Firmen sowie das gesamte Statistiksystem der Schweiz, da es weitere maschinelle Anwendungen ermöglichen würde.
Ein Projekt-Teilnehmer hat kürzlich Folgendes treffend formuliert: «Auch nach dem offiziellen Ende des Projekts statbot.swiss glaube ich, dass das Data Warehouse bestehen bleiben wird… Es ist womöglich das erste Mal in der Schweiz, dass öffentliche Daten von verschiedenen Datenproduzenten an einem Ort in einer gemeinsamen, harmonisierten Struktur vorhanden sind.». Die Datenbedürfnisse der potentiellen Machine-Learning-Anwendung haben somit als wesentliche Anforderung dazu geführt, Daten zu strukturieren und zu harmonisieren. Dieses Resultat – das Data Warehouse – könnte viel Potenzial für andere Anwendungen haben.
Ich erinnere an dieser Stelle zunächst an die Bürgerin, die hoffentlich in der Zwischenzeit die gesuchten Daten gefunden hat. Jede Entwicklung, egal ob ein Data Warehouse, ein Bot oder eine andere Anwendung, muss direkt oder indirekt auf die Bedürfnisse der Bürger ausgerichtet sein. Öffentliche Behördendaten sollten einfacher auffindbar, vernetzter und leichter in andere Applikationen integrierbar werden.
Hier möchten wir mit der Community durch persönliche Gespräche, Events und Online stärker ins Gespräch kommen. Einerseits möchten wir die Datenbedürfnisse der Nutzenden besser kennen, um darauf bedarfsorientiert entwickeln zu können. Andererseits können wir damit leichter Lösungen wie den Bot in einer frühen Phase testen und Feedback integrieren. Wenn Sie Interesse haben, können Sie mir gerne formlos eine E-Mail mit Betreff statbot.swiss schreiben.

Dr. Christian Ruiz
Projektleiter Machine Learning
Statistisches Amt Kanton Zürich
christian.ruiz@statistik.ji.zh.ch
+41 43 259 75 12
Der Autor
Dr. Christian Ruiz leitet aktuell das Machine Learning im Statistischen Amt Kanton Zürich. Er hat 13 Jahre Erfahrung in Data Science und 6 Jahre Erfahrung in der praktischen Entwicklung von Machine-Learning-Anwendungen. Er ist Mitgründer von zwei Startups im Bereich Deep Learning, hat drei weitere Machine-Learning-Projekte umgesetzt und andere Projekte begleitet.
Download Artikel
Swiss Insights News #12
Alle SWISS INSIGHTS News finden Sie hier: SWISS INSIGHTS NEWS