
Die 1986 kurz nach dem Start explodierte Challenger-Raumfähre der NASA mit sieben Astronauten[1] und das wegen eines Fehlers in Google Maps versehentlich abgerissene Haus von Lindsey Diaz[2] sind beides Konsequenzen mangelnder Datenqualität.
Als multifaktorieller, unscharfer Begriff ist Datenqualität kein «Messerwert», sondern wird multimodal erarbeitet: bei Online-Befragungen vor der Feldphase mittels elaboriertem Sampling, Fragebogenkonzeption und Pretesting. Aber auch danach in der Analyse und der Bereinigung der gewonnenen Daten. Hinzu kommen Meta-Aspekte der Datenqualität wie Passung der Daten zur Forschungsfrage, Prozesstransparenz, faire Datengewinnung oder proaktiver Datenschutz, die Empowerment für Kunden bewirken.
Datenqualität – was ist das?
57 Millionen Suchergebnisse bei google verdeutlichien die Relevanz des Begriffs «Data Quality». Im täglichen Sprachgebrauch wird der Begriff «Datenqualität» häufig mit der Richtigkeit (Präzision) von Daten gleichgesetzt. Um diese zu erhöhen, werden genauere Messinstrumente, rigorose Datenerhebungsverfahren und komplexe statistische Methoden zum Aggregieren von Daten entwickelt[3]. Auch der Fokus der nachfolgend präsentierten Massnahmen zur Erhöhung der Datenqualität liegt auf der Verbesserung der klassischen Gütekriterien Validität und Reliabilität von Umfrageergebnissen. Darüber hinaus differenzieren Konzepte wie das der Universität Greifswald Datenqualität weiter, hier in die Dimensionen Integrität, Komplettheit und Korrektheit (Konsistenz und Akkuratheit)[4] – und es existieren in der Literatur zahlreiche überlappende Modelle[5].
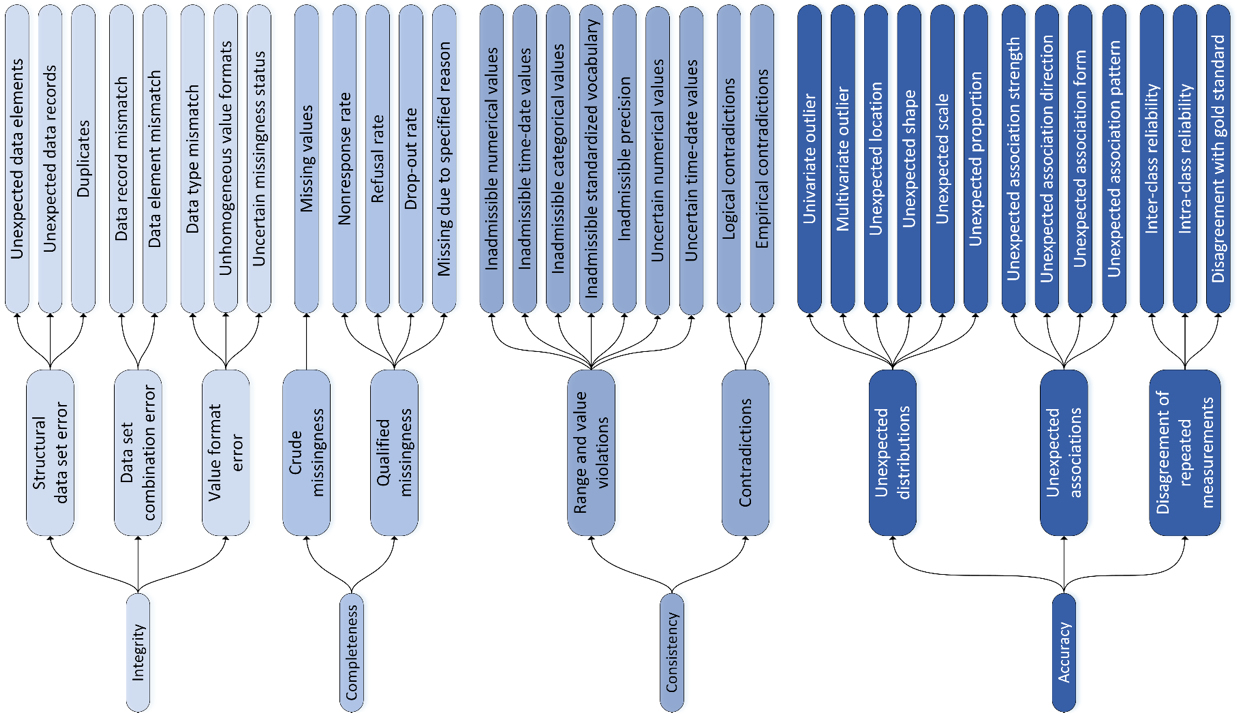
Insbesondere im Bereich der Markt- und Meinungsforschung stehen am Ende der Datenverarbeitung Auftraggebende oder Forschende als Consumer der Daten. Daher ist es besonders wichtig, zu verstehen, dass Datenqualität aus Konsumentensicht oft über die Präzision von Werten hinausgeht.
Consumer als Zielgrösse
Welche Aspekte der Datenqualität für Consumer ausschlaggebend sind, untersuchten Richard Y. Wang und Diane M. Strong in einer zweistufigen empirischen Studie. Definiert wurde Datenqualität dabei über das verbreitete «fitness-for-use»-Konzept[6], welches Datenqualität durch die Eignung der Daten zum von Consumern angedachten Zweck bestimmt. Das Ergebnis der Studie war ein vierdimensionales Modell von Datenqualität, welches das bestehende Konzept empirisch operationalisiert[6].
Die vier Dimensionen sind: intrinsic data quality, contextual data quality, representational data quality und accessibility data quality. Sie zeigen, dass für Consumer der Begriff der Datenqualität vielschichtig ist und nicht nur im Sinne der Richtigkeit verstanden werden sollte. Vielmehr sind auch Aspekte wie Glaubwürdigkeit, Relevanz, Vollständigkeit, Interpretierbarkeit, Konsistenz oder Zugänglichkeit der Daten für Consumer ausschlaggebend[4].

Vor der Befragung
Jede Onlinebefragung ist trotz Abwesenheit einer interviewenden Person und den damit wegfallenden primären Interviewer-Effekten (deshalb oft als «verzerrungsfrei» angepriesen) immer eine Situation, in der im Extremfall eine parasoziale Interaktion mit einem imaginären Interviewer stattfindet. Oder die mindestens irgendeine Art von kognitivem Stimulus-Response-Prozess bei Befragten auslöst. Dieser gliedert sich als Cognitive Aspects of Survey Methodology (CASM) vereinfacht in vier Schritte[7-10]:
- Lesen und Verstehen der Frage
- Abrufen relevanter Informationen aus dem Gedächtnis
- Beurteilung der abgerufenen Informationen bezüglich Vollständigkeit und Relevanz, kognitive Editierung der präferierten Antwort auf das gewünschte Antwortformat und Angemessenheit
- Antwortabgabe
Die kognitive Verarbeitung folgt dabei den Zweiprozessmodellen[11-12] und geschieht elaboriert (intensiv, zentral) oder peripher (oberflächlich, schnell, nebenbei, heuristisch). Eine elaborierte Verarbeitung begünstigen unter anderem die gute Verständlichkeit der Frage, die kognitive Fähigkeit sowie die Motivation der Antwortenden, genügend Zeit und wenig Ablenkung. Eine periphere Verarbeitung öffnet die Tür für Verzerrungseffekte noch weiter.
Zehn Gebote für gute Fragebögen
Bei dieser Verarbeitung sind eine Menge latenter Störeinflüsse (Response Bias[13]) im Spiel, die sich nur schwer kontrollieren lassen. Trotzdem kann im Design von Fragebögen mit zehn Geboten[9], soweit möglich und ökonomisch sinnvoll, vorgesorgt werden, wobei diese weniger als «starre» Regeln, denn als Reflexionsbasis für das Finetuning von Fragebögen dienen:
- einfache, unzweideutige Begriffe (werden von allen Befragten sehr ähnlich verstanden)
- unklare Begriffe definieren
- keine langen/komplexen Fragen
- keine hypothetischen Fragen
- keine Doppelstimuli/Doppelverneinung
- keine Unterstellungen/Suggestivfragen
- keine Fragen nach Informationen, die viele Befragte vermutlich nicht kennen
- Fragen mit eindeutigem zeitlichen Bezug
- Antwortkategorien sind erschöpfend und disjunkt (überschneidungsfrei)
- Kontext einer Frage wirkt sich nicht auf deren Beantwortung aus
Zum Beispiel kann eine Frage wie «Wurden in Ihrer Schule bereits Projekte im Rahmen des LP21 umgesetzt?» vielleicht Lehrpersonen gestellt werden, aber nicht Eltern (Gebote 2 und 7). Und «Experten denken, dass CO2-Massnahmen zu langsam umgesetzt werden – halten Sie diese Ansicht für richtig oder für falsch?» verstösst gegen das sechste Gebot. Sogar in wissenschaftlich angesehenen Studien werden Fragen gestellt, die sich in erheblichem Masse der Erinnerbarkeit entziehen (Mobiltelefonnutzung in den letzten 6 Monaten): «detailed questions were asked about the initial pattern of use, including network operator and average number and duration of calls, and any subsequent changes in use patterns. Questions were also asked about the proportion of time the phones were used in urban, suburban or rural settings»[14] (Gebot 3, 7, 8). Entsprechend der Konversationsmaximen nach Grice[15] gilt auch für Formulierungen in Fragebögen:
• Qualität (wahr und nicht suggestiv)
• Quantität (so ausführlich wie nötig, so kurz wie möglich)
• Relevanz (zielgruppengerecht, nur fragen und ansprechen, was zum Thema gehört)
• Modalität (klar, eindeutig, kompakt und geordnet)
Weiter sollten Übertragungseffekte minimiert werden: Steht vor der Frage, «Welche Partei wählen Sie am Wahlsonntag?» eine Frage zu Umweltkatastrophen oder eine zum Wirtschaftswachstum? Ist Fleisch 25% fett oder 75% mager?[16] Übertragungs- und Framing-Effekte sollten mit möglichst objektiven Formulierungen und Kontexten verringert werden.
Skalen sind Korsetts, die passen müssen
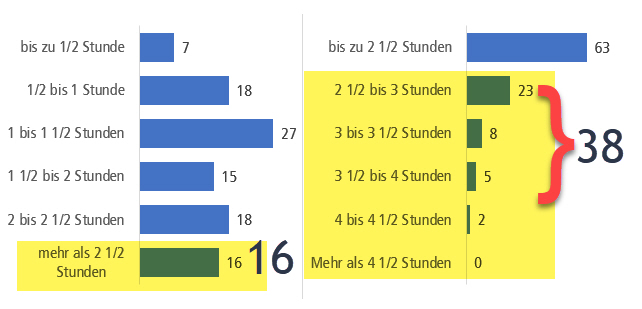
Auch Rating-Skalen an sich können Verzerrungen unterstützen, da Antworten von den Befragten «passend» gemacht werden. «Trash-Antworten» können reduziert werden, in dem eine Ausweichkategorie «keine Antwort» angeboten wird. Dadurch gehen leider einige gültige Antworten verloren, die versteckte Datenverschmutzung, wenn wegen Fehlen einer Ausweichkategorie einfach irgendwas angekreuzt wird[17], nimmt jedoch ab. Eine mittlere Ausprägung wie «teils/teils» wird ebenfalls empfohlen[18]. Rating-Skalen mit 5 bis 7 vollverbalisierten Antwortkategorien werden mehrheitlich als ratsam erachtet – zu wenige Kategorien differenzieren ungenügend, zu viele sind inhaltlich schwer zu unterscheiden, fehlende Verbalisierung ist schwerer zu interpretieren[18]. Einige weitere Verzerrungseffekte, denen in Online-Befragungen Beachtung geschenkt werden sollte, sind Akquieszenz (generelle Zustimmungstendenz in Skalen), Non-Attitude (beliebige Antworten bei Desinteresse, Zeitknappheit), soziale Erwünschtheit (Erwartungskonformität), Sponsorship-Effekte (Antworten dem Auftraggeber zuliebe), Situationseffekte (Kontext und Ort des Ausfüllens, Anwesenheit von Bekannten, Helfern), Tendenzen zur Mitte (Meiden von Extremen), Lageeffekte (Primacy/Recency-Effekt: Erste und letzte Antwortvorgaben werden besser erinnert und bevorzugt, weil salienter) oder Ankereffekte (Übertragung, Beeinflussung durch Vorfragen, selektives Antwortuniversum, Priming). Schwarz[19] hat zu Letzterem schon 1999 festgestellt, dass Antwortvorgaben implizite Anker setzen. So antworteten unter Verwendung der linken Skala (vgl. Bild 2) nur 16% der Befragten mit «mehr als 2 ½ Stunden». Mit der rechten Skala hingegen insgesamt 38%, obwohl dieselbe Frage gestellt worden war. Die Extremposition der Antwortvorgabe «mehr als 2 ½ Stunden» in der linken Skala lässt die Teilnehmenden unterreportieren, rechts ist der umgekehrte Effekt der Fall.
Die Datenqualität ist auch beeinflusst durch die Frageformate: offene Textfelder versus Skalen versus halboffene Formate, Validierungen direkt im Fragebogen, Regie-Anweisungen, visuelle Darstellung von Skalen, Mobildarstellung, technische Einflüsse wie schwer bedienbare Schieberegler; und ebenso Herausforderungen bestimmter Zielgruppen wie Kinder oder digital unerfahrene Benutzer. Pretesting sowie Regie-Hinweise bezüglich der erwarteten Dateneingaben in punkto Umfang, Art und Format der Eingaben sind im Fragebogen fast immer vorteilhaft.
Einige Probleme der Datenqualität können somit durch intensive Reflexion, Einbinden von Fragebogen-Consultants, ausführliches Pretesting (z. B. auch mit Explorieren oder Split-Half-Setups verschiedener Frageformate) und Überarbeiten von bereits bestehenden Fragebögen durchaus adressiert werden.
Nach der Befragung
Mit einem Prämienvolumen von knapp 6 Mrd. CHF (1) stellt die Motorfahrzeugsparte (MFZ) das grösste Auch im Nachgang können Massnahmen zur Verbesserung der Datenqualität getroffen werden. Diese beziehen sich hauptsächlich auf verzerrende Effekte, die Teilnehmende durch ihr Verhalten im Fragebogen erzeugen.
Während einige dieser Effekte, wie z. B. Ausreisser*, Speeder** oder inkomplette Fragebögen unabhängig vom Befragungsmodus auftreten (z. B. auch in CATI, Face-to-Face), häufen sich gerade bei schriftlichen und Online-Befragungen sogenannte «Response-Sets» (Tendenzen von Teilnehmenden, eine Reihe von Fragen in einem bestimmten Muster zu beantworten)[20]. Bei Online-Befragungen wird dies zusätzlich durch die erhöhte empfundene Anonymität verschärft, da mit steigender Anonymität die Tendenz steigt, Items weniger ernsthaft auszufüllen und falsche oder fiktive Antworten abzugeben[20].
*Datenpunkt, der bedeutend von den restlichen Datenpunkten entfernt liegt.
**Teilnehmende, die den Fragebogen in einer Zeit komplettieren, die bei seriösem Durchlesen der Fragen und Antwortmöglichkeiten nicht plausibel ist.
Klassische Antwortmuster, die in schriftlichen Befragungen mit Rating-Skalen beobachtet werden können, sind: Response-Ranges (Verwendung nur eines bestimmten Bereichs der Skala, unabhängig vom Inhalt der Frage oder der Ausrichtung der Antwortvorgaben), Extreme Checking Style (auch Extreme Response Style[21], ERS, genannt: abwechselndes Anwählen der linken und rechten Extrempunkte einer Skala), Muster-Ankreuzer (Ankreuzen von Mustern wie z. B. Diagonalen oder Pfeilen in Tabellenfragen) und Straightliner (Null-Varianz-Antwortverhalten, d. h. Auswahl eines bestimmten Skalenpunkts, unabhängig von der Skalenbreite, -ausrichtung und Frageformulierung). Gerade Letztere sind bei unmotivierten Teilnehmenden beliebt. Jandura identifiziert in einer offenen Online-Befragung zu Mediennutzungsverhalten von Jugendlichen bei einem Viertel der Befragten ein Null-Varianz-Antwortverhalten in mindestens einer der neun beantworteten Fragen[20]. Allerdings muss hier relativiert werden, dass Straightlining unter gewissen Umständen valide ist, beispielsweise, wenn eine Item-Batterie eine hohe interne Konsistenz aufweist und alle Items in dieselbe Richtung formuliert sind[22]. Um valides Straightlining auszuschliessen, könnte ein Item pro Frageblock vor der Feldphase umgepolt werden.
Um die Qualität der Ergebnisse einer Befragung zu erhöhen, sollten Fälle mit den beschriebenen Effekten untersucht und allenfalls aus der Analyse exkludiert werden. Während dies bei einigen Effekten relativ einfach möglich ist (z. B. können Speeder anhand der Bearbeitungszeit und inkomplette Fragebögen anhand der fehlenden Antworten schnell identifiziert werden), ist für andere Effekte ein genaueres Hinsehen notwendig (siehe Tabelle 2). Der Prozess kann dabei digital mit multifaktoriellen, statistischen Prozeduren unterstützt werden. Die Entscheidung, ob ein spezifischer Fall nun als Quality Fail ausgeschlossen werden soll oder nicht, sollte jedoch durch geschulte Mitarbeitende nach der Sichtung des entsprechenden Fragebogens und nicht auf Basis einzelner Kriterien erfolgen.

Fazit
In einem kurzen Artikel kann das Thema Datenqualität lediglich anhand ausgewählter Aspekte angeschnitten werden. Zusammenfassend ergeben sich drei essenzielle Punkte:
- Eine Ausrichtung der Datenqualität auf Abnehmergrupp
- Wesentliche Weichen für die Datenqualität werden schon vor der Feldphase gestellt.
- Eine Datenqualitätsanalyse und Datenbereinigung nach der Feldphase ist technisch möglich und nützlich.
Dies sind wichtige Erkenntnisse für validere Analysen, für die Kundenkommunikation, den Projektaufbau und das Branchen-Image.
Datenqualität geht zudem einher mit Themen wie Erhebungs- und Verwendungsethik, Zweckbestimmung von Daten, Panelpflege, Datenschutz und mit der Idee, auch komplexe Prozesse der Auswertungslogik, Algorithmen und Deep-Learning-Modelle so transparent wie möglich zu machen. Ein positives Wechselverhältnis von Datengebenden und -nehmenden widerspiegelt sich in einem emanzipierten und daher lohnenswerten Verständnis von Datenqualität für alle.
Literaturverzeichnis weiter unten
For English Version download pdf

Raffael Meier
Mitgründer und CTO von onlineumfragen.com und Pionier der Onlinebefragungstechnologie.
raffael.meier@onlineumfragen.com
+41 44 500 5137

Die Autoren
Raffael Meier, MA, MSc – Mitgründer und CTO von onlineumfragen.com und Pionier der Onlinebefragungstechnologie. Er befasst sich mit gesellschaftlichen und methodologischen Aspekten von Daten und berät Kundinnen und Kunden mit dem Ziel «Empowerment».
Nina Gwerder, MA – ist Consultant bei onlineumfragen.com und spezialisiert auf die Beratung namhafter nationaler und internationaler Unternehmen rund um das Thema Online-Befragungen und deren effektiver Auswertung.
Download Artikel
Swiss Insights News #11

Institute Member von
SWISS INSIGHTS
Alle SWISS INSIGHTS News finden Sie hier: SWISS INSIGHTS NEWS
Literaturverzeichnis
[1] Fisher, C. W., & Kingma, B. R. (2001). «Criticality of data quality as exemplified in two disasters », Information & Management, 39(2), 109–116. https://doi.org/10.1016/S0378-7206(01)00083-0
[2] Wrong house gets torn down based on a Google Maps error. Engadget. (n.d.). Abgerufen am 17. August 2022, von https://www.engadget.com/2016-03-24-texas-wrong-house-torn-down-google-maps.html
[3] Keller, S., Korkmaz, G., Orr, M., Schroeder, A. und Shipp, S. (2017). «The Evolution of Data Quality: Understanding the Transdisciplinary Origins of Data Quality Concepts and Approaches», Annual Review of Statistics and Its Application, 4(1), S.85-108.
[4] Schmidt, C. O., Struckmann, S., Enzenbach, C., Reineke, A., Stausberg, J., Damerow, S., Huebner, M., Schmidt, B., Sauerbrei, W., & Richter, A. (2021). «Facilitating harmonized data quality assessments. A data quality framework for observational health research data collections with software implementations in R», BMC Medical Research Methodology, 21(1). https://doi.org/10.1186/S12874-021-01252-7
[5] Haug, A. (2021). «Understanding the differences across data quality classifications: a literature review and guidelines for future research», Industrial Management and Data Systems, 121(12), 2651–2671. https://doi.org/10.1108/IMDS-12-2020-0756
[6] Wang, R.Y. und Strong, D.M. (1996). «Beyond Accuracy: What Data Quality Means to Data Consumers», Journal of Management Information Systems, 12(4), S.5-33.
[7] Cannell, C. F., Miller, P. v., & Oksenberg, L. (1981). «Research on interviewing techniques», in S. Leinhardt (Ed.), Social Methodology. Jossey-Bass Publishers.
[8] Tourangeau, R., Rips, L. J., & Rasinski, K. (2000). The Psychology of Survey Response. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511819322
[9] Porst, R. (2014). Fragebogen. Wiesbaden: Springer Fachmedien. https://doi.org/10.1007/978-3-658-02118-4
[10] Tourangeau, R. (2018). «The survey response process from a cognitive viewpoint», Quality Assurance in Education, 26(2), 169–181. https://doi.org/10.1108/QAE-06-2017-0034
[11] Petty, R. E., & Cacioppo, J. T. (1986). «The elaboration likelihood model of persuasion», Advances in Experimental Social Psychology, 19(C), 123–205. https://doi.org/10.1016/S0065-2601(08)60214-2
[12] Dual-process theories in social psychology. PsycNET. (n.d.). Abgerufen am 17. August 2022, von https://psycnet.apa.org/record/1999-02377-000
[13] Bogner, Kathrin und Landrock, Uta (2015). Antworttendenzen in standardisierten Umfragen. Mannheim, GESIS Leibniz Institut für Sozialwissenschaften (GESIS Survey Guidelines). https://doi.org/10.15465/gesis-sg_016
[14] Cardis, E., Richardson, L., Deltour, I. et al. (2007). «The INTERPHONE study: design, epidemiological methods, and description of the study population», Eur J Epidemiol, 22, 647–664. https://doi.org/10.1007/s10654-007-9152-z
[15] Grice, H. P. (1975). «Logic and Conversation», in P. Cole, & J. L. Morgan. (Eds.), Syntax and Semantics, Vol. 3, Speech Acts (pp. 41-58). New York: Academic Press.
[16] Levin, I. P., & Gaeth, G. J. (1988). «How Consumers are Affected by the Framing of Attribute Information Before and After Consuming the Product», Journal of Consumer Research,
[15] (3), 374. https://doi.org/10.1086/209174
[17] Berekoven, L., Eckert, W., & Ellenrieder, P. (2004). Marktforschung. Wiesbaden: Gabler Verlag. https://doi.org/10.1007/978-3-663-05734-5
[18] Menold, N., & Bogner, K. (2015). «Gestaltung von Ratingskalen in Fragebögen (Version 1.1)», GESIS Survey Guidelines, 13. https://doi.org/10.15465/GESIS-SG_015
[19] Schwarz, N. (1999). «Self-reports: How the questions shape the answers», American Psychologist, 54(2), 93–105. https://doi.org/10.1037/0003-066X.54.2.93
[20] Jandura, O. (2018). «Fake Data? Zur Trennung von sauberen und verschmutzten Daten bei selbst-administrierten Befragungsmodi», in Rössler P. & Rossman, C. (Hrsg.), Kumulierte Evidenzen. Wiesbaden: Springer VS, S. 207-223.
[21] Greenleaf, E. A. (1992). «Measuring Extreme Response Style», The Public Opinion Quarterly, 56(3), 328–351. http://www.jstor.org/stable/2749156
[22] Reunig, K. und Plutzer E. (2020). «Valid vs. Invalid Straightlining: The Complex Relationship Between Straightlining and Data Quality», Survey Research Methods, 14(5), S.439-459.
Literaturverzeichnis